 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuRA: Internalizing Audio Understanding into LLMs as LoRA
Jun 09, 2026Recent efforts to extend large language models (LLMs) to speech inputs typically rely on cascaded ASR-LLM pipelines, end-to-end speech-language models, or bridge/distillation-based adaptation. While these routes respectively reuse strong pretrained components, enable native speech-language interaction, or offer lightweight adaptation, they often suffer from transcript-interface latency, costly multimodal training, or sequential speech-language coupling. To address these limitations, we present AuRA, a method that distills audio encoding capability into the LLM. Specifically, AuRA feeds the same speech input to an ASR encoder (as a teacher) and a LoRA-adapted LLM (as a student) through a lightweight audio embedding layer, and uses layer-wise distillation to align the student's hidden states with corresponding teacher representations, thereby internalizing speech representations into lightweight LLM-side adaptations. Compared with cascaded and serial bridge methods, AuRA enables tighter speech-language joint modeling and efficient parallel end-to-end inference, while also reusing pretrained speech and language models rather than requiring large-scale multimodal training. On multiple speech-language benchmarks, AuRA consistently outperforms cascaded systems, speech-to-LLM adaptation baselines, and large-scale speech-language and multimodal models in both effectiveness and efficiency.
Convergence Rates for Neural-Network Estimation with Current-Status Data
Jun 08, 2026Current-status data arise when an event time is observed only through an indicator of whether it occurred before an examination time. This paper studies a nonparametric neural-network sieve maximum likelihood estimator of the conditional cumulative distribution function of the event time. Under Hölder smoothness assumptions, we establish an explicit convergence rate by combining approximation theory for rectified linear unit neural networks with empirical-process arguments. This result provides theoretical support for neural-network estimation and subsequent inference under current-status observation.
A Systematic Evaluation of Positional Bias in Multi-Video Summarization with MLLMs
Jun 03, 2026Multimodal Large Language Models (MLLMs) are increasingly used for video understanding, yet their reliability under multi-video inputs remains poorly understood. We study positional bias in multi-video summarization, where the quality of a per-video summary can change with the video's input slot even when the underlying content is unchanged. We construct a benchmark from ActivityNet and News videos, covering Cooking, Domestic, Leisure, and News settings with two- and four-video inputs. We evaluate nine open-source and proprietary MLLMs and measure position effects with three complementary metrics: Coverage, Directional Positional Bias (DPB), and Middle-Edge Gap (MEG). Our results show that positional effects are domain- and model-dependent: signed directional bias can be small even when middle positions underperform, and increasing visual or generation budget does not uniformly remove the imbalance. We further analyze prompt-level mitigation methods. Together, the results show that multi-video summarization remains sensitive to input protocol and position, motivating more robust order-invariant multimodal systems.
VCIFBench: Evaluating Complex Instruction Following for Video Understanding
Jun 03, 2026Multimodal large language models have made rapid progress in video understanding, yet existing benchmarks largely rely on simple prompts and provide limited evidence about whether models can satisfy explicit output constraints. We introduce VCIFBench, a benchmark for evaluating complex instruction following in video understanding. VCIFBench constructs constraint-rich instructions from both benchmark-adapted and directly video-grounded prompts, covering content, format, style, and structure requirements, and evaluates model outputs with a hybrid verification pipeline. The benchmark contains 306 satisfiable test instructions, a 540-pair DPO preference dataset, and a 30-item conflict diagnostic subset. Experiments on 10 MLLMs show that joint constraint satisfaction remains challenging. We further show that DPO training on VCIFBench data can improve instruction-following performance.
Height-Guided Projection Reparameterization for Camera-LiDAR Occupancy
May 06, 20263D occupancy prediction aims to infer dense, voxel-wise scene semantics from sensor observations, where the 2D-to-3D view transformation serves as a crucial step in bridging image features and volumetric representations. Most previous methods rely on a fixed projection space, where 3D reference points are uniformly sampled along pillars. However, such sampling struggles to capture the sparsity and height variations of real-world scenes, leading to ambiguous correspondences and unreliable feature aggregation. To address these challenges, we propose HiPR, a camera-LiDAR occupancy framework with Height-Guided Projection Reparameterization. HiPR first encodes LiDAR into a BEV height map to capture the maximum height of the point cloud. HiPR then adjusts the sampling range of each pillar using the height prior, enabling adaptive reparameterization of the projection space. As a result, the projected points are redistributed into geometrically meaningful regions rather than fixed ranges. Meanwhile, we mask out the invalid parts of the height map to avoid misleading the feature aggregation. In addition, to alleviate the training instability caused by noisy LiDAR-derived heights, we introduce a training-time Progressive Height Conditioning strategy, which gradually transitions the conditioning signal from ground-truth heights to LiDAR heights. Extensive experiments demonstrate that HiPR consistently outperforms existing state-of-the-art methods while maintaining real-time inference. The code and pretrained models can be found at https://github.com/Rayn-Wu/HiPR.
AutoFly: Vision-Language-Action Model for UAV Autonomous Navigation in the Wild
Feb 10, 2026Vision-language navigation (VLN) requires intelligent agents to navigate environments by interpreting linguistic instructions alongside visual observations, serving as a cornerstone task in Embodied AI. Current VLN research for unmanned aerial vehicles (UAVs) relies on detailed, pre-specified instructions to guide the UAV along predetermined routes. However, real-world outdoor exploration typically occurs in unknown environments where detailed navigation instructions are unavailable. Instead, only coarse-grained positional or directional guidance can be provided, requiring UAVs to autonomously navigate through continuous planning and obstacle avoidance. To bridge this gap, we propose AutoFly, an end-to-end Vision-Language-Action (VLA) model for autonomous UAV navigation. AutoFly incorporates a pseudo-depth encoder that derives depth-aware features from RGB inputs to enhance spatial reasoning, coupled with a progressive two-stage training strategy that effectively aligns visual, depth, and linguistic representations with action policies. Moreover, existing VLN datasets have fundamental limitations for real-world autonomous navigation, stemming from their heavy reliance on explicit instruction-following over autonomous decision-making and insufficient real-world data. To address these issues, we construct a novel autonomous navigation dataset that shifts the paradigm from instruction-following to autonomous behavior modeling through: (1) trajectory collection emphasizing continuous obstacle avoidance, autonomous planning, and recognition workflows; (2) comprehensive real-world data integration. Experimental results demonstrate that AutoFly achieves a 3.9% higher success rate compared to state-of-the-art VLA baselines, with consistent performance across simulated and real environments.
AGGC: Adaptive Group Gradient Clipping for Stabilizing Large Language Model Training
Jan 17, 2026To stabilize the training of Large Language Models (LLMs), gradient clipping is a nearly ubiquitous heuristic used to alleviate exploding gradients. However, traditional global norm clipping erroneously presupposes gradient homogeneity across different functional modules, leading to an adverse "spill-over" effect where volatile parameters force unnecessary scaling on stable ones. To overcome this, we propose Adaptive Group-wise Gradient Clipping (AGGC). AGGC partitions parameters into groups based on functional types and regulates each according to its historical behavior using an Exponential Moving Average (EMA). Specifically, it constructs an adaptive interval to simultaneously mitigate gradient explosion and vanishing, while employing a time-dependent scheduling mechanism to balance exploration and convergence. Experiments on LLaMA 2-7B, Mistral-7B, and Gemma-7B models show that AGGC consistently outperforms LoRA and frequently surpasses Full Fine-Tuning. On the GSM8K benchmark, Mistral-7B fine-tuned with AGGC achieves an accuracy of 72.93%, exceeding LoRA's 69.5%. AGGC also effectively stabilizes Reinforcement Learning with Verifiable Rewards (RLVR), enhancing the logic deduction of Qwen 2.5 and Llama 3.2 models. Experimental results demonstrate that AGGC effectively addresses the limitations of traditional gradient clipping methods, particularly in overcoming gradient heterogeneity, by utilizing a modular, adaptive clipping strategy to stabilize the training process. Due to its lightweight design, AGGC can be seamlessly integrated into existing post-training pipelines with negligible overhead.
Align, Don't Divide: Revisiting the LoRA Architecture in Multi-Task Learning
Aug 07, 2025Parameter-Efficient Fine-Tuning (PEFT) is essential for adapting Large Language Models (LLMs). In practice, LLMs are often required to handle a diverse set of tasks from multiple domains, a scenario naturally addressed by multi-task learning (MTL). Within this MTL context, a prevailing trend involves LoRA variants with multiple adapters or heads, which advocate for structural diversity to capture task-specific knowledge. Our findings present a direct challenge to this paradigm. We first show that a simplified multi-head architecture with high inter-head similarity substantially outperforms complex multi-adapter and multi-head systems. This leads us to question the multi-component paradigm itself, and we further demonstrate that a standard single-adapter LoRA, with a sufficiently increased rank, also achieves highly competitive performance. These results lead us to a new hypothesis: effective MTL generalization hinges on learning robust shared representations, not isolating task-specific features. To validate this, we propose Align-LoRA, which incorporates an explicit loss to align task representations within the shared adapter space. Experiments confirm that Align-LoRA significantly surpasses all baselines, establishing a simpler yet more effective paradigm for adapting LLMs to multiple tasks. The code is available at https://github.com/jinda-liu/Align-LoRA.
ConfProBench: A Confidence Evaluation Benchmark for MLLM-Based Process Judges
Aug 06, 2025



Reasoning is a critical capability of multimodal large language models (MLLMs) for solving complex multimodal tasks, and judging the correctness of reasoning steps is crucial for improving this capability. Recently, MLLM-based process judges (MPJs) have been widely used to assess the correctness of reasoning steps in multimodal tasks. Therefore, evaluating MPJs is important for identifying their limitations and guiding future improvements. However, existing benchmarks for MPJs mainly focus on tasks such as step correctness classification and reasoning process search, while overlooking a key aspect: whether the confidence scores produced by MPJs at the step level are reliable. To address this gap, we propose ConfProBench, the first comprehensive benchmark designed to systematically evaluate the reliability of step-level confidence scores generated by MPJs. Our benchmark constructs three types of adversarially perturbed reasoning steps: Synonym Substitution, Syntactic Transformation, and Image Perturbation, to test the robustness of MPJ confidence under perturbations. In addition, we introduce three novel evaluation metrics: Confidence Robustness Score (CRS), Confidence Sensitivity Score (CSS), and Confidence Calibration Score (CCS), which evaluate robustness, sensitivity, and calibration, respectively. We evaluate 14 state-of-the-art MLLMs, including both proprietary and open-source models. Experiments reveal limitations in current MPJs' confidence performance and offer competitive baselines to support future research.
Can Large Multimodal Models Actively Recognize Faulty Inputs? A Systematic Evaluation Framework of Their Input Scrutiny Ability
Aug 06, 2025
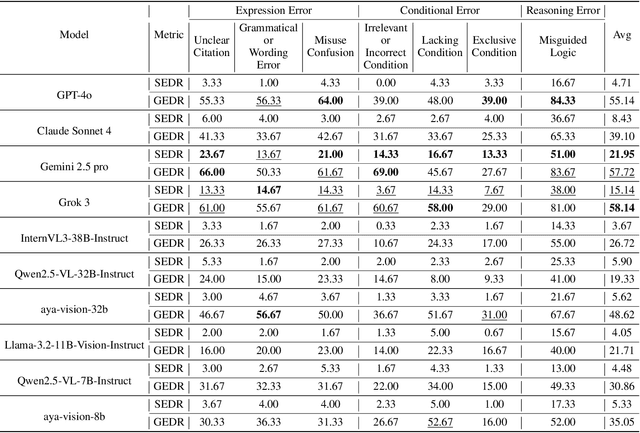
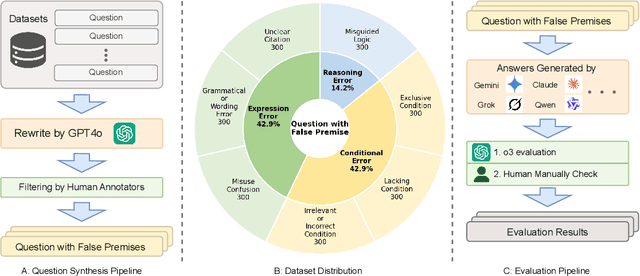
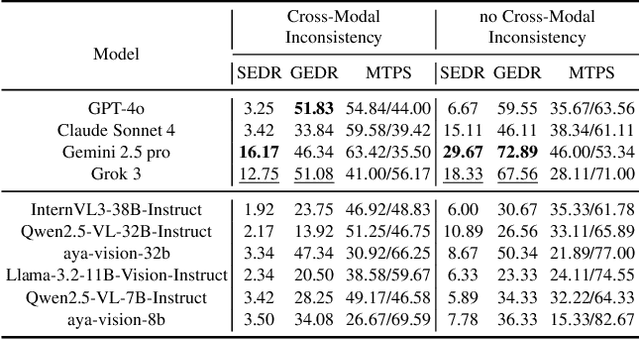
Large Multimodal Models (LMMs) have witnessed remarkable growth, showcasing formidable capabilities in handling intricate multimodal tasks with exceptional performance. Recent research has underscored the inclination of large language models to passively accept defective inputs, often resulting in futile reasoning on invalid prompts. However, the same critical question of whether LMMs can actively detect and scrutinize erroneous inputs still remains unexplored. To address this gap, we introduce the Input Scrutiny Ability Evaluation Framework (ISEval), which encompasses seven categories of flawed premises and three evaluation metrics. Our extensive evaluation of ten advanced LMMs has identified key findings. Most models struggle to actively detect flawed textual premises without guidance, which reflects a strong reliance on explicit prompts for premise error identification. Error type affects performance: models excel at identifying logical fallacies but struggle with surface-level linguistic errors and certain conditional flaws. Modality trust varies-Gemini 2.5 pro and Claude Sonnet 4 balance visual and textual info, while aya-vision-8b over-rely on text in conflicts. These insights underscore the urgent need to enhance LMMs' proactive verification of input validity and shed novel insights into mitigating the problem. The code is available at https://github.com/MLGroupJLU/LMM_ISEval.