 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Scope: Turning Sparse Features into Development Tools for Large Language Models
May 12, 2026Large language models have achieved remarkable capabilities across diverse tasks, yet their internal decision-making processes remain largely opaque, limiting our ability to inspect, control, and systematically improve them. This opacity motivates a growing body of research in mechanistic interpretability, with sparse autoencoders (SAEs) emerging as one of the most promising tools for decomposing model activations into sparse, interpretable feature representations. We introduce Qwen-Scope, an open-source suite of SAEs built on the Qwen model family, comprising 14 groups of SAEs across 7 model variants from the Qwen3 and Qwen3.5 series, covering both dense and mixture-of-expert architectures. Built on top of these SAEs, we show that SAEs can go beyond post-hoc analysis to serve as practical interfaces for model development along four directions: (i) inference-time steering, where SAE feature directions control language, concepts, and preferences without modifying model weights; (ii) evaluation analysis, where activated SAE features provide a representation-level proxy for benchmark redundancy and capability coverage; (iii) data-centric workflows, where SAE features support multilingual toxicity classification and safety-oriented data synthesis; and (iv) post-training optimization, where SAE-derived signals are incorporated into supervised fine-tuning and reinforcement learning objectives to mitigate undesirable behaviors such as code-switching and repetition. Together, these results demonstrate that SAEs can serve not only as post-hoc analysis tools, but also as reusable representation-level interfaces for diagnosing, controlling, evaluating, and improving large language models. By open-sourcing Qwen-Scope, we aim to support mechanistic research and accelerate practical workflows that connect model internals to downstream behavior.
Language as a Latent Variable for Reasoning Optimization
Apr 23, 2026As LLMs reduce English-centric bias, a surprising trend emerges: non-English responses sometimes outperform English on reasoning tasks. We hypothesize that language functions as a latent variable that structurally modulates the model's internal inference pathways, rather than merely serving as an output medium. To test this, we conducted a Polyglot Thinking Experiment, in which models were prompted to solve identical problems under language-constrained and language-unconstrained conditions. Results show that non-English responses often achieve higher accuracy, and the best performance frequently occur when language is unconstrained, suggesting that multilinguality broadens the model's latent reasoning space. Based on this insight, we propose polyGRPO (Polyglot Group Relative Policy Optimization), an RL framework that treats language variation as an implicit exploration signal. It generates polyglot preference data online under language-constrained and unconstrained conditions, optimizing the policy with respect to both answer accuracy and reasoning structure. Trained on only 18.1K multilingual math problems without chain-of-thought annotations, polyGRPO improves the base model (Qwen2.5-7B-Instruct) by 6.72% absolute accuracy on four English reasoning testset and 6.89% in their multilingual benchmark. Remarkably, it is the only method that surpasses the base LLM on English commonsense reasoning task (4.9%), despite being trained solely on math data-highlighting its strong cross-task generalization. Further analysis reveals that treating language as a latent variable expands the model's latent reasoning space, yielding consistent and generalizable improvements in reasoning performance.
DeepSeek-OCR 2: Visual Causal Flow
Jan 28, 2026We present DeepSeek-OCR 2 to investigate the feasibility of a novel encoder-DeepEncoder V2-capable of dynamically reordering visual tokens upon image semantics. Conventional vision-language models (VLMs) invariably process visual tokens in a rigid raster-scan order (top-left to bottom-right) with fixed positional encoding when fed into LLMs. However, this contradicts human visual perception, which follows flexible yet semantically coherent scanning patterns driven by inherent logical structures. Particularly for images with complex layouts, human vision exhibits causally-informed sequential processing. Inspired by this cognitive mechanism, DeepEncoder V2 is designed to endow the encoder with causal reasoning capabilities, enabling it to intelligently reorder visual tokens prior to LLM-based content interpretation. This work explores a novel paradigm: whether 2D image understanding can be effectively achieved through two-cascaded 1D causal reasoning structures, thereby offering a new architectural approach with the potential to achieve genuine 2D reasoning. Codes and model weights are publicly accessible at http://github.com/deepseek-ai/DeepSeek-OCR-2.
CMP: A Composable Meta Prompt for SAM-Based Cross-Domain Few-Shot Segmentation
Jul 22, 2025Cross-Domain Few-Shot Segmentation (CD-FSS) remains challenging due to limited data and domain shifts. Recent foundation models like the Segment Anything Model (SAM) have shown remarkable zero-shot generalization capability in general segmentation tasks, making it a promising solution for few-shot scenarios. However, adapting SAM to CD-FSS faces two critical challenges: reliance on manual prompt and limited cross-domain ability. Therefore, we propose the Composable Meta-Prompt (CMP) framework that introduces three key modules: (i) the Reference Complement and Transformation (RCT) module for semantic expansion, (ii) the Composable Meta-Prompt Generation (CMPG) module for automated meta-prompt synthesis, and (iii) the Frequency-Aware Interaction (FAI) module for domain discrepancy mitigation. Evaluations across four cross-domain datasets demonstrate CMP's state-of-the-art performance, achieving 71.8\% and 74.5\% mIoU in 1-shot and 5-shot scenarios respectively.
DFR: A Decompose-Fuse-Reconstruct Framework for Multi-Modal Few-Shot Segmentation
Jul 22, 2025This paper presents DFR (Decompose, Fuse and Reconstruct), a novel framework that addresses the fundamental challenge of effectively utilizing multi-modal guidance in few-shot segmentation (FSS). While existing approaches primarily rely on visual support samples or textual descriptions, their single or dual-modal paradigms limit exploitation of rich perceptual information available in real-world scenarios. To overcome this limitation, the proposed approach leverages the Segment Anything Model (SAM) to systematically integrate visual, textual, and audio modalities for enhanced semantic understanding. The DFR framework introduces three key innovations: 1) Multi-modal Decompose: a hierarchical decomposition scheme that extracts visual region proposals via SAM, expands textual semantics into fine-grained descriptors, and processes audio features for contextual enrichment; 2) Multi-modal Contrastive Fuse: a fusion strategy employing contrastive learning to maintain consistency across visual, textual, and audio modalities while enabling dynamic semantic interactions between foreground and background features; 3) Dual-path Reconstruct: an adaptive integration mechanism combining semantic guidance from tri-modal fused tokens with geometric cues from multi-modal location priors. Extensive experiments across visual, textual, and audio modalities under both synthetic and real settings demonstrate DFR's substantial performance improvements over state-of-the-art methods.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
PolyMath: Evaluating Mathematical Reasoning in Multilingual Contexts
Apr 30, 2025In this paper, we introduce PolyMath, a multilingual mathematical reasoning benchmark covering 18 languages and 4 easy-to-hard difficulty levels. Our benchmark ensures difficulty comprehensiveness, language diversity, and high-quality translation, making it a highly discriminative multilingual mathematical benchmark in the era of reasoning LLMs. We conduct a comprehensive evaluation for advanced LLMs and find that even Qwen-3-235B-A22B-Thinking and Gemini-2.5-pro, achieve only 54.6 and 52.2 benchmark scores, with about 40% accuracy under the highest level From a language perspective, our benchmark reveals several key challenges of LLMs in multilingual reasoning: (1) Reasoning performance varies widely across languages for current LLMs; (2) Input-output language consistency is low in reasoning LLMs and may be correlated with performance; (3) The thinking length differs significantly by language for current LLMs. Additionally, we demonstrate that controlling the output language in the instructions has the potential to affect reasoning performance, especially for some low-resource languages, suggesting a promising direction for improving multilingual capabilities in LLMs.
Enhancing LLM Language Adaption through Cross-lingual In-Context Pre-training
Apr 29, 2025Large language models (LLMs) exhibit remarkable multilingual capabilities despite English-dominated pre-training, attributed to cross-lingual mechanisms during pre-training. Existing methods for enhancing cross-lingual transfer remain constrained by parallel resources, suffering from limited linguistic and domain coverage. We propose Cross-lingual In-context Pre-training (CrossIC-PT), a simple and scalable approach that enhances cross-lingual transfer by leveraging semantically related bilingual texts via simple next-word prediction. We construct CrossIC-PT samples by interleaving semantic-related bilingual Wikipedia documents into a single context window. To access window size constraints, we implement a systematic segmentation policy to split long bilingual document pairs into chunks while adjusting the sliding window mechanism to preserve contextual coherence. We further extend data availability through a semantic retrieval framework to construct CrossIC-PT samples from web-crawled corpus. Experimental results demonstrate that CrossIC-PT improves multilingual performance on three models (Llama-3.1-8B, Qwen2.5-7B, and Qwen2.5-1.5B) across six target languages, yielding performance gains of 3.79%, 3.99%, and 1.95%, respectively, with additional improvements after data augmentation.
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025



Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
Perception in Reflection
Apr 09, 2025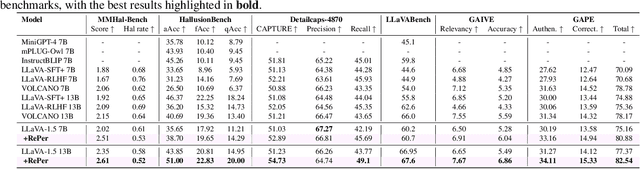


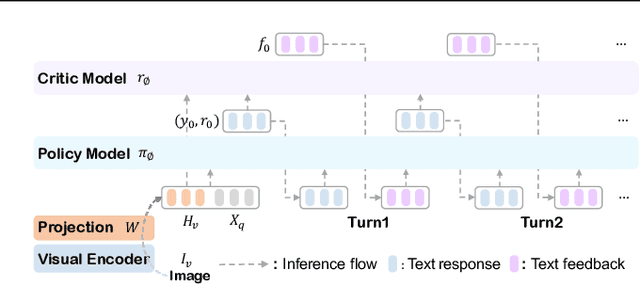
We present a perception in reflection paradigm designed to transcend the limitations of current large vision-language models (LVLMs), which are expected yet often fail to achieve perfect perception initially. Specifically, we propose Reflective Perception (RePer), a dual-model reflection mechanism that systematically alternates between policy and critic models, enables iterative refinement of visual perception. This framework is powered by Reflective Perceptual Learning (RPL), which reinforces intrinsic reflective capabilities through a methodically constructed visual reflection dataset and reflective unlikelihood training. Comprehensive experimental evaluation demonstrates RePer's quantifiable improvements in image understanding, captioning precision, and hallucination reduction. Notably, RePer achieves strong alignment between model attention patterns and human visual focus, while RPL optimizes fine-grained and free-form preference alignment. These advancements establish perception in reflection as a robust paradigm for future multimodal agents, particularly in tasks requiring complex reasoning and multi-step manipulation.