 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodePercept: Code-Grounded Visual STEM Perception for MLLMs
Mar 11, 2026When MLLMs fail at Science, Technology, Engineering, and Mathematics (STEM) visual reasoning, a fundamental question arises: is it due to perceptual deficiencies or reasoning limitations? Through systematic scaling analysis that independently scales perception and reasoning components, we uncover a critical insight: scaling perception consistently outperforms scaling reasoning. This reveals perception as the true lever limiting current STEM visual reasoning. Motivated by this insight, our work focuses on systematically enhancing the perception capabilities of MLLMs by establishing code as a powerful perceptual medium--executable code provides precise semantics that naturally align with the structured nature of STEM visuals. Specifically, we construct ICC-1M, a large-scale dataset comprising 1M Image-Caption-Code triplets that materializes this code-as-perception paradigm through two complementary approaches: (1) Code-Grounded Caption Generation treats executable code as ground truth for image captions, eliminating the hallucinations inherent in existing knowledge distillation methods; (2) STEM Image-to-Code Translation prompts models to generate reconstruction code, mitigating the ambiguity of natural language for perception enhancement. To validate this paradigm, we further introduce STEM2Code-Eval, a novel benchmark that directly evaluates visual perception in STEM domains. Unlike existing work relying on problem-solving accuracy as a proxy that only measures problem-relevant understanding, our benchmark requires comprehensive visual comprehension through executable code generation for image reconstruction, providing deterministic and verifiable assessment. Code is available at https://github.com/TongkunGuan/Qwen-CodePercept.
From Narrow to Panoramic Vision: Attention-Guided Cold-Start Reshapes Multimodal Reasoning
Mar 04, 2026The cold-start initialization stage plays a pivotal role in training Multimodal Large Reasoning Models (MLRMs), yet its mechanisms remain insufficiently understood. To analyze this stage, we introduce the Visual Attention Score (VAS), an attention-based metric that quantifies how much a model attends to visual tokens. We find that reasoning performance is strongly correlated with VAS (r=0.9616): models with higher VAS achieve substantially stronger multimodal reasoning. Surprisingly, multimodal cold-start fails to elevate VAS, resulting in attention distributions close to the base model, whereas text-only cold-start leads to a clear increase. We term this counter-intuitive phenomenon Lazy Attention Localization. To validate its causal role, we design training-free interventions that directly modulate attention allocation during inference, performance gains of 1$-$2% without any retraining. Building on these insights, we further propose Attention-Guided Visual Anchoring and Reflection (AVAR), a comprehensive cold-start framework that integrates visual-anchored data synthesis, attention-guided objectives, and visual-anchored reward shaping. Applied to Qwen2.5-VL-7B, AVAR achieves an average gain of 7.0% across 7 multimodal reasoning benchmarks. Ablation studies further confirm that each component of AVAR contributes step-wise to the overall gains. The code, data, and models are available at https://github.com/lrlbbzl/Qwen-AVAR.
SMoFi: Step-wise Momentum Fusion for Split Federated Learning on Heterogeneous Data
Nov 16, 2025



Split Federated Learning is a system-efficient federated learning paradigm that leverages the rich computing resources at a central server to train model partitions. Data heterogeneity across silos, however, presents a major challenge undermining the convergence speed and accuracy of the global model. This paper introduces Step-wise Momentum Fusion (SMoFi), an effective and lightweight framework that counteracts gradient divergence arising from data heterogeneity by synchronizing the momentum buffers across server-side optimizers. To control gradient divergence over the training process, we design a staleness-aware alignment mechanism that imposes constraints on gradient updates of the server-side submodel at each optimization step. Extensive validations on multiple real-world datasets show that SMoFi consistently improves global model accuracy (up to 7.1%) and convergence speed (up to 10.25$\times$). Furthermore, SMoFi has a greater impact with more clients involved and deeper learning models, making it particularly suitable for model training in resource-constrained contexts.
Qwen2.5-VL Technical Report
Feb 19, 2025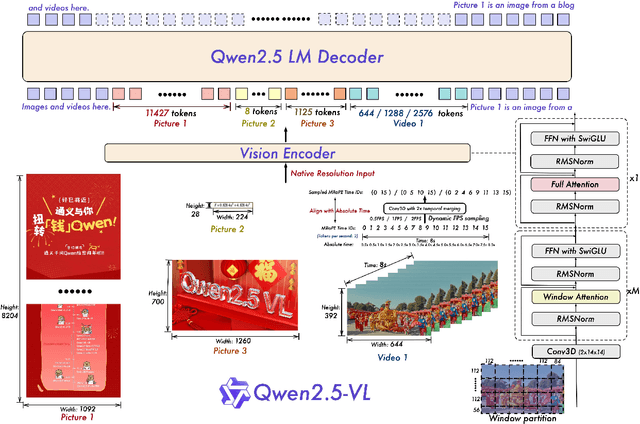
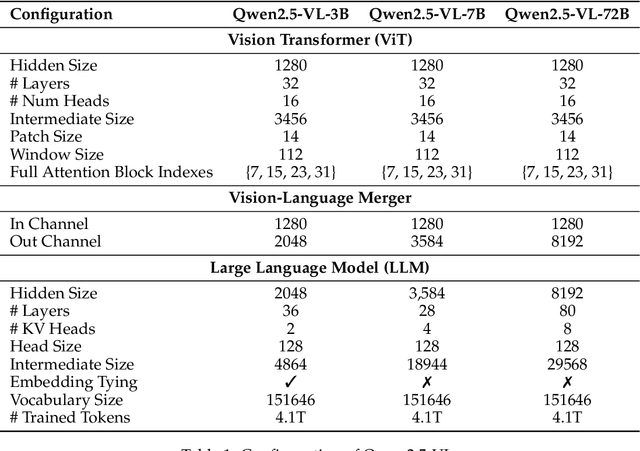
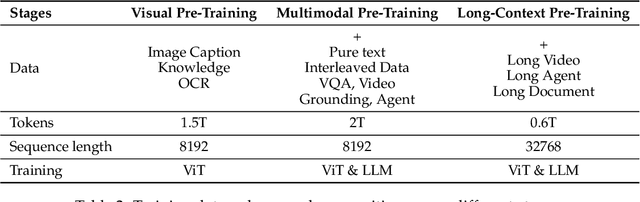
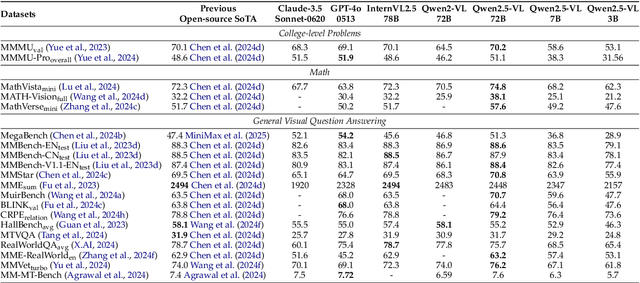
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy
Dec 03, 2024Large Multimodal Models (LMMs) have demonstrated impressive performance on recognizing document images with natural language instructions. However, it remains unclear to what extent capabilities in literacy with rich structure and fine-grained visual challenges. The current landscape lacks a comprehensive benchmark to effectively measure the literate capabilities of LMMs. Existing benchmarks are often limited by narrow scenarios and specified tasks. To this end, we introduce CC-OCR, a comprehensive benchmark that possess a diverse range of scenarios, tasks, and challenges. CC-OCR comprises four OCR-centric tracks: multi-scene text reading, multilingual text reading, document parsing, and key information extraction. It includes 39 subsets with 7,058 full annotated images, of which 41% are sourced from real applications, being released for the first time. Furthermore, we evaluate nine prominent LMMs and reveal both the strengths and weaknesses of these models, particularly in text grounding, multi-orientation, and hallucination of repetition. CC-OCR aims to comprehensively evaluate the capabilities of LMMs on OCR-centered tasks, driving advancement in LMMs.
Sequential Visual and Semantic Consistency for Semi-supervised Text Recognition
Feb 24, 2024Scene text recognition (STR) is a challenging task that requires large-scale annotated data for training. However, collecting and labeling real text images is expensive and time-consuming, which limits the availability of real data. Therefore, most existing STR methods resort to synthetic data, which may introduce domain discrepancy and degrade the performance of STR models. To alleviate this problem, recent semi-supervised STR methods exploit unlabeled real data by enforcing character-level consistency regularization between weakly and strongly augmented views of the same image. However, these methods neglect word-level consistency, which is crucial for sequence recognition tasks. This paper proposes a novel semi-supervised learning method for STR that incorporates word-level consistency regularization from both visual and semantic aspects. Specifically, we devise a shortest path alignment module to align the sequential visual features of different views and minimize their distance. Moreover, we adopt a reinforcement learning framework to optimize the semantic similarity of the predicted strings in the embedding space. We conduct extensive experiments on several standard and challenging STR benchmarks and demonstrate the superiority of our proposed method over existing semi-supervised STR methods.
Class-Aware Mask-Guided Feature Refinement for Scene Text Recognition
Feb 21, 2024Scene text recognition is a rapidly developing field that faces numerous challenges due to the complexity and diversity of scene text, including complex backgrounds, diverse fonts, flexible arrangements, and accidental occlusions. In this paper, we propose a novel approach called Class-Aware Mask-guided feature refinement (CAM) to address these challenges. Our approach introduces canonical class-aware glyph masks generated from a standard font to effectively suppress background and text style noise, thereby enhancing feature discrimination. Additionally, we design a feature alignment and fusion module to incorporate the canonical mask guidance for further feature refinement for text recognition. By enhancing the alignment between the canonical mask feature and the text feature, the module ensures more effective fusion, ultimately leading to improved recognition performance. We first evaluate CAM on six standard text recognition benchmarks to demonstrate its effectiveness. Furthermore, CAM exhibits superiority over the state-of-the-art method by an average performance gain of 4.1% across six more challenging datasets, despite utilizing a smaller model size. Our study highlights the importance of incorporating canonical mask guidance and aligned feature refinement techniques for robust scene text recognition. The code is available at https://github.com/MelosY/CAM.
Visual Information Extraction in the Wild: Practical Dataset and End-to-end Solution
May 12, 2023



Visual information extraction (VIE), which aims to simultaneously perform OCR and information extraction in a unified framework, has drawn increasing attention due to its essential role in various applications like understanding receipts, goods, and traffic signs. However, as existing benchmark datasets for VIE mainly consist of document images without the adequate diversity of layout structures, background disturbs, and entity categories, they cannot fully reveal the challenges of real-world applications. In this paper, we propose a large-scale dataset consisting of camera images for VIE, which contains not only the larger variance of layout, backgrounds, and fonts but also much more types of entities. Besides, we propose a novel framework for end-to-end VIE that combines the stages of OCR and information extraction in an end-to-end learning fashion. Different from the previous end-to-end approaches that directly adopt OCR features as the input of an information extraction module, we propose to use contrastive learning to narrow the semantic gap caused by the difference between the tasks of OCR and information extraction. We evaluate the existing end-to-end methods for VIE on the proposed dataset and observe that the performance of these methods has a distinguishable drop from SROIE (a widely used English dataset) to our proposed dataset due to the larger variance of layout and entities. These results demonstrate our dataset is more practical for promoting advanced VIE algorithms. In addition, experiments demonstrate that the proposed VIE method consistently achieves the obvious performance gains on the proposed and SROIE datasets.
Reading and Writing: Discriminative and Generative Modeling for Self-Supervised Text Recognition
Jul 01, 2022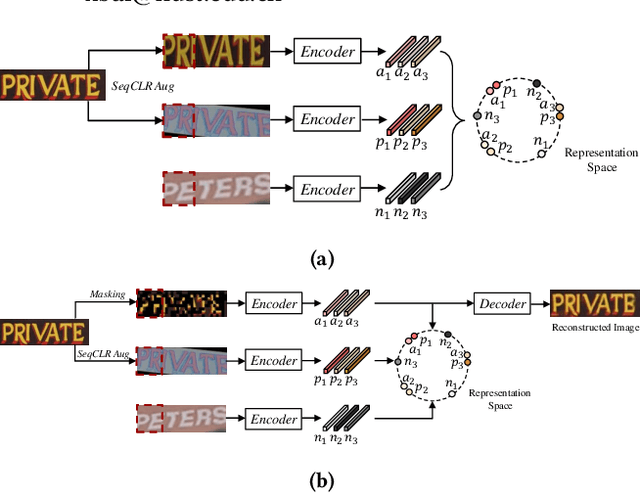
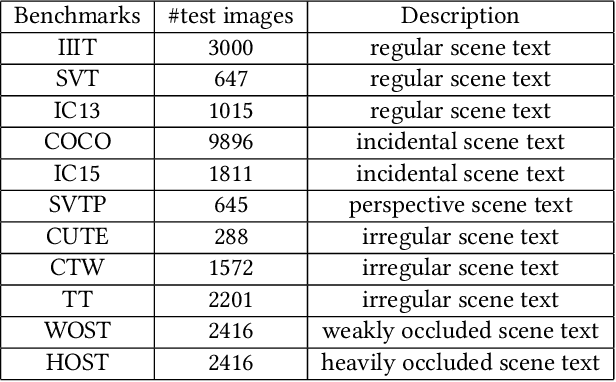
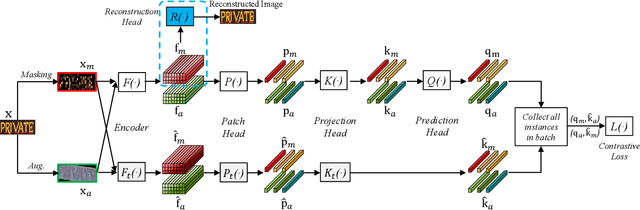
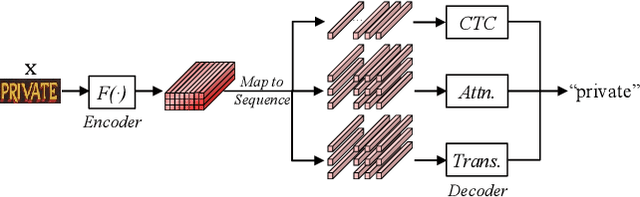
Existing text recognition methods usually need large-scale training data. Most of them rely on synthetic training data due to the lack of annotated real images. However, there is a domain gap between the synthetic data and real data, which limits the performance of the text recognition models. Recent self-supervised text recognition methods attempted to utilize unlabeled real images by introducing contrastive learning, which mainly learns the discrimination of the text images. Inspired by the observation that humans learn to recognize the texts through both reading and writing, we propose to learn discrimination and generation by integrating contrastive learning and masked image modeling in our self-supervised method. The contrastive learning branch is adopted to learn the discrimination of text images, which imitates the reading behavior of humans. Meanwhile, masked image modeling is firstly introduced for text recognition to learn the context generation of the text images, which is similar to the writing behavior. The experimental results show that our method outperforms previous self-supervised text recognition methods by 10.2%-20.2% on irregular scene text recognition datasets. Moreover, our proposed text recognizer exceeds previous state-of-the-art text recognition methods by averagely 5.3% on 11 benchmarks, with similar model size. We also demonstrate that our pre-trained model can be easily applied to other text-related tasks with obvious performance gain.
DeepAVO: Efficient Pose Refining with Feature Distilling for Deep Visual Odometry
May 20, 2021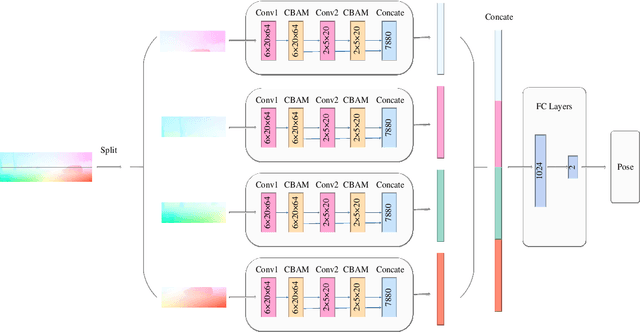
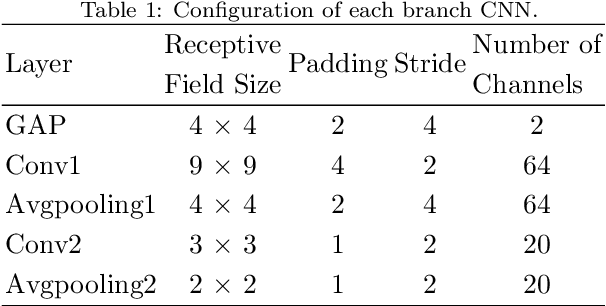

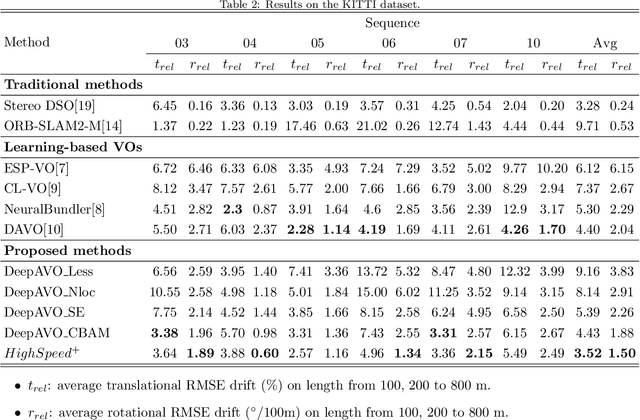
The technology for Visual Odometry (VO) that estimates the position and orientation of the moving object through analyzing the image sequences captured by on-board cameras, has been well investigated with the rising interest in autonomous driving. This paper studies monocular VO from the perspective of Deep Learning (DL). Unlike most current learning-based methods, our approach, called DeepAVO, is established on the intuition that features contribute discriminately to different motion patterns. Specifically, we present a novel four-branch network to learn the rotation and translation by leveraging Convolutional Neural Networks (CNNs) to focus on different quadrants of optical flow input. To enhance the ability of feature selection, we further introduce an effective channel-spatial attention mechanism to force each branch to explicitly distill related information for specific Frame to Frame (F2F) motion estimation. Experiments on various datasets involving outdoor driving and indoor walking scenarios show that the proposed DeepAVO outperforms the state-of-the-art monocular methods by a large margin, demonstrating competitive performance to the stereo VO algorithm and verifying promising potential for generalization.