 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Cluster Faces on an Affinity Graph
May 05, 2019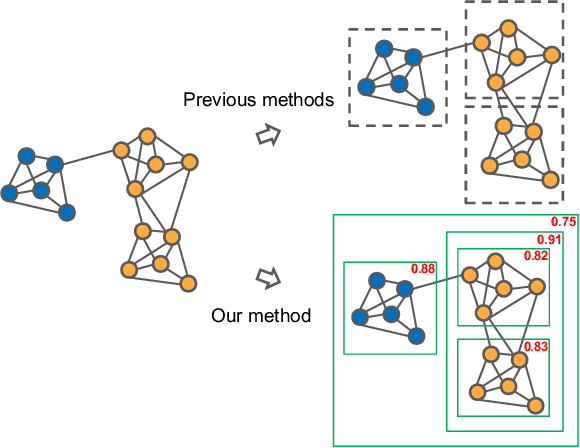
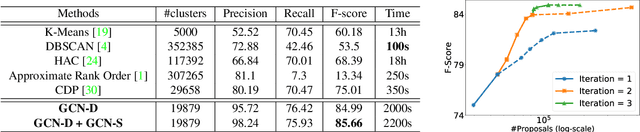
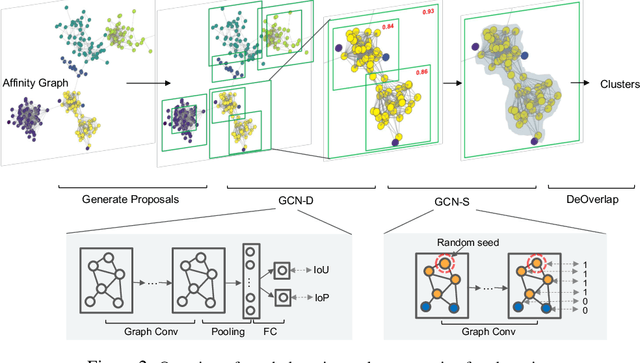
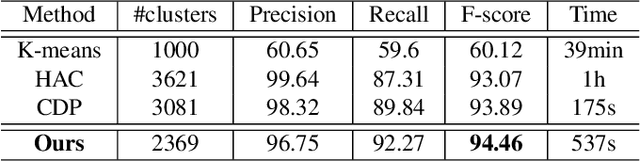
Face recognition sees remarkable progress in recent years, and its performance has reached a very high level. Taking it to a next level requires substantially larger data, which would involve prohibitive annotation cost. Hence, exploiting unlabeled data becomes an appealing alternative. Recent works have shown that clustering unlabeled faces is a promising approach, often leading to notable performance gains. Yet, how to effectively cluster, especially on a large-scale (i.e. million-level or above) dataset, remains an open question. A key challenge lies in the complex variations of cluster patterns, which make it difficult for conventional clustering methods to meet the needed accuracy. This work explores a novel approach, namely, learning to cluster instead of relying on hand-crafted criteria. Specifically, we propose a framework based on graph convolutional network, which combines a detection and a segmentation module to pinpoint face clusters. Experiments show that our method yields significantly more accurate face clusters, which, as a result, also lead to further performance gain in face recognition.
Knowledge Distillation via Route Constrained Optimization
Apr 19, 2019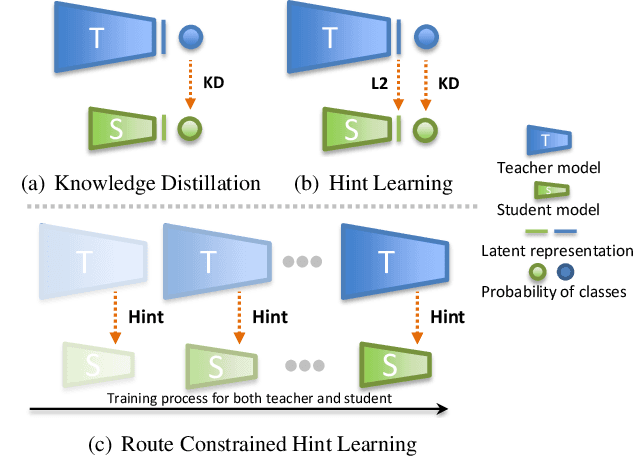
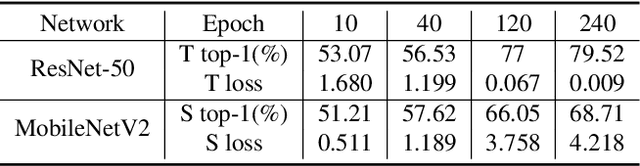
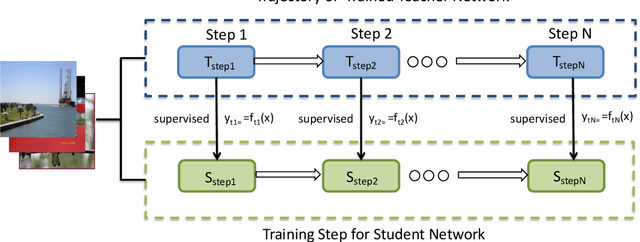
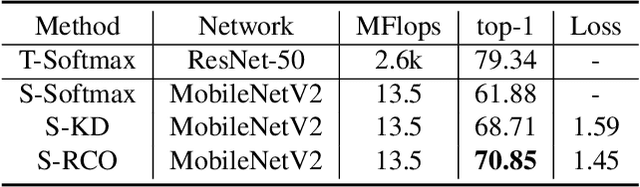
Distillation-based learning boosts the performance of the miniaturized neural network based on the hypothesis that the representation of a teacher model can be used as structured and relatively weak supervision, and thus would be easily learned by a miniaturized model. However, we find that the representation of a converged heavy model is still a strong constraint for training a small student model, which leads to a high lower bound of congruence loss. In this work, inspired by curriculum learning we consider the knowledge distillation from the perspective of curriculum learning by routing. Instead of supervising the student model with a converged teacher model, we supervised it with some anchor points selected from the route in parameter space that the teacher model passed by, as we called route constrained optimization (RCO). We experimentally demonstrate this simple operation greatly reduces the lower bound of congruence loss for knowledge distillation, hint and mimicking learning. On close-set classification tasks like CIFAR100 and ImageNet, RCO improves knowledge distillation by 2.14% and 1.5% respectively. For the sake of evaluating the generalization, we also test RCO on the open-set face recognition task MegaFace.
Dynamic Multi-path Neural Network
Apr 07, 2019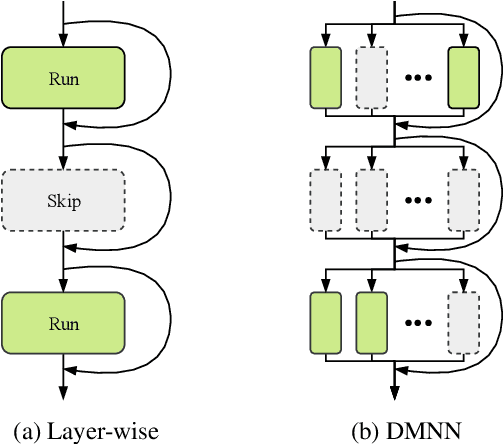
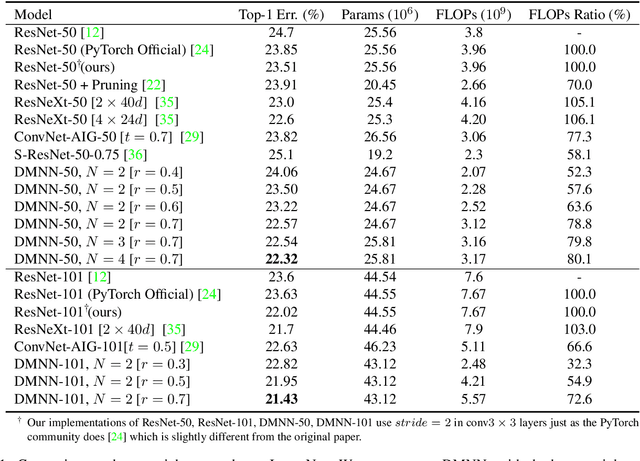
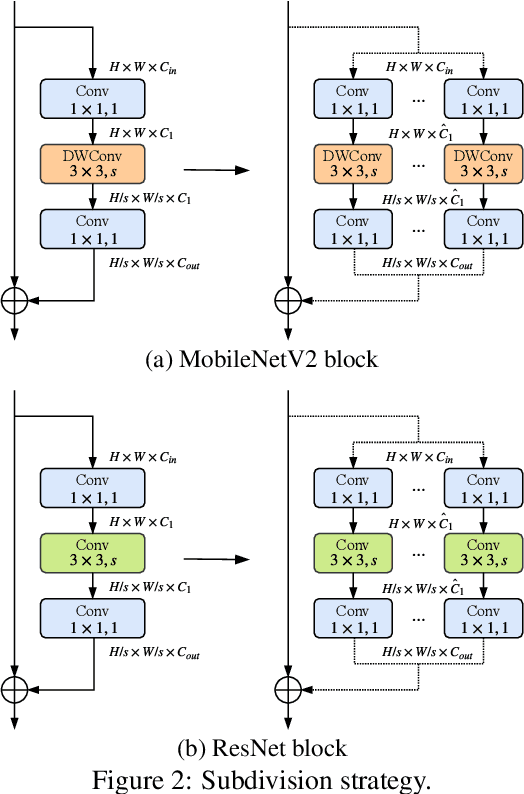
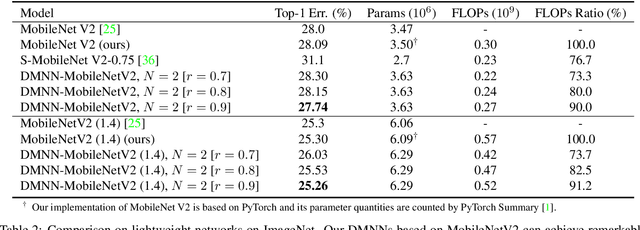
Although deeper and larger neural networks have achieved better performance, the complex network structure and increasing computational cost cannot meet the demands of many resource-constrained applications. Existing methods usually choose to execute or skip an entire specific layer, which can only alter the depth of the network. In this paper, we propose a novel method called Dynamic Multi-path Neural Network (DMNN), which provides more path selection choices in terms of network width and depth during inference. The inference path of the network is determined by a controller, which takes into account both previous state and object category information. The proposed method can be easily incorporated into most modern network architectures. Experimental results on ImageNet and CIFAR-100 demonstrate the superiority of our method on both efficiency and overall classification accuracy. To be specific, DMNN-101 significantly outperforms ResNet-101 with an encouraging 45.1% FLOPs reduction, and DMNN-50 performs comparably to ResNet-101 while saving 42.1% parameters.
Video Generation from Single Semantic Label Map
Mar 11, 2019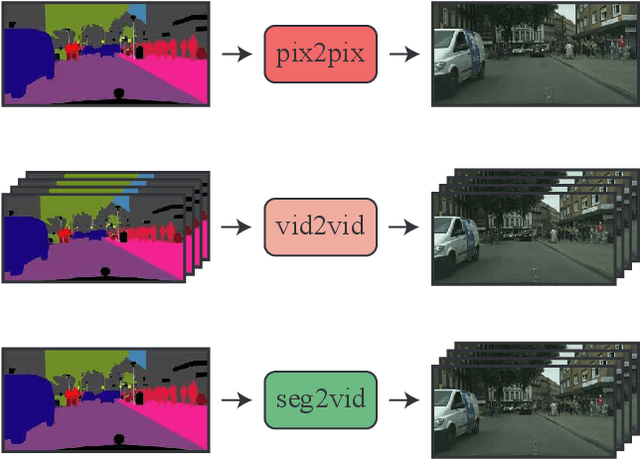

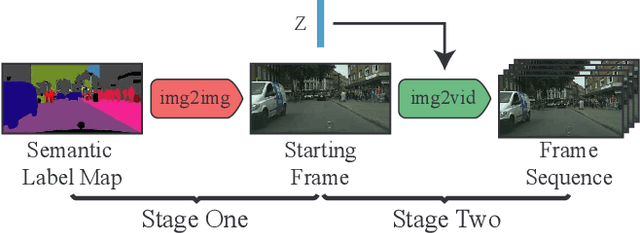

This paper proposes the novel task of video generation conditioned on a SINGLE semantic label map, which provides a good balance between flexibility and quality in the generation process. Different from typical end-to-end approaches, which model both scene content and dynamics in a single step, we propose to decompose this difficult task into two sub-problems. As current image generation methods do better than video generation in terms of detail, we synthesize high quality content by only generating the first frame. Then we animate the scene based on its semantic meaning to obtain the temporally coherent video, giving us excellent results overall. We employ a cVAE for predicting optical flow as a beneficial intermediate step to generate a video sequence conditioned on the initial single frame. A semantic label map is integrated into the flow prediction module to achieve major improvements in the image-to-video generation process. Extensive experiments on the Cityscapes dataset show that our method outperforms all competing methods.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019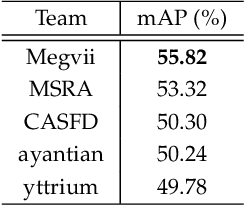

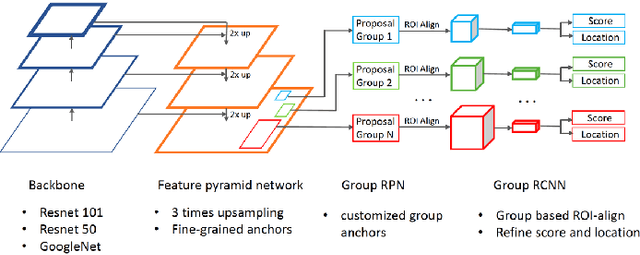
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.
Dynamic Curriculum Learning for Imbalanced Data Classification
Jan 21, 2019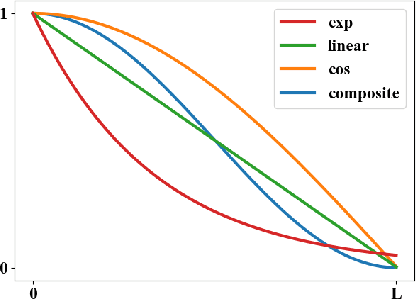
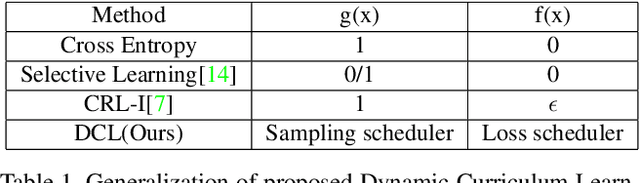
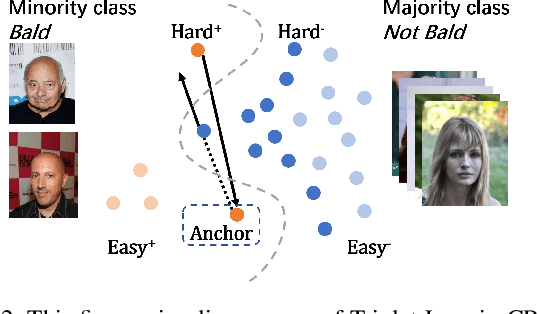
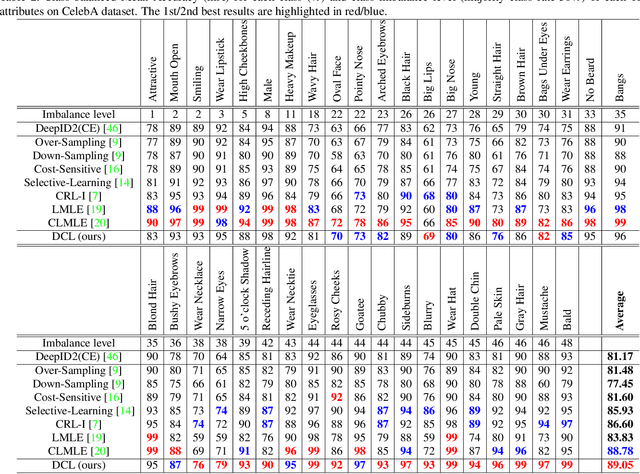
Human attribute analysis is a challenging task in the field of computer vision, since the data is largely imbalance-distributed. Common techniques such as re-sampling and cost-sensitive learning require prior-knowledge to train the system. To address this problem, we propose a unified framework called Dynamic Curriculum Learning (DCL) to online adaptively adjust the sampling strategy and loss learning in single batch, which resulting in better generalization and discrimination. Inspired by the curriculum learning, DCL consists of two level curriculum schedulers: (1) sampling scheduler not only manages the data distribution from imbalanced to balanced but also from easy to hard; (2) loss scheduler controls the learning importance between classification and metric learning loss. Learning from these two schedulers, we demonstrate our DCL framework with the new state-of-the-art performance on the widely used face attribute dataset CelebA and pedestrian attribute dataset RAP.
Multi-Object Tracking with Multiple Cues and Switcher-Aware Classification
Jan 18, 2019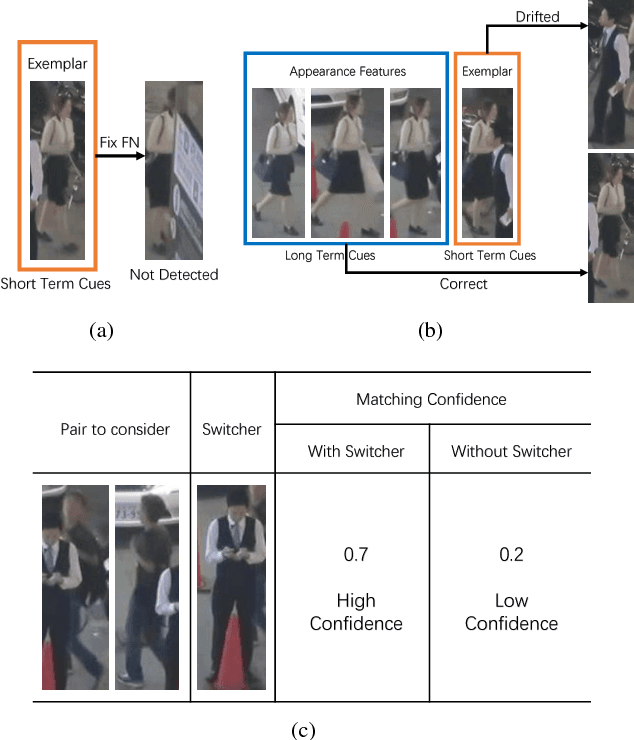
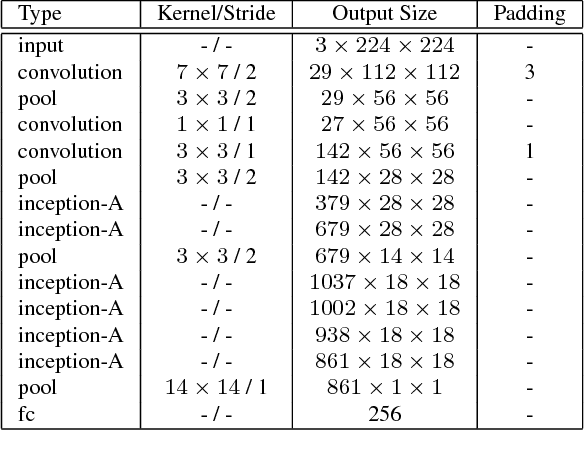
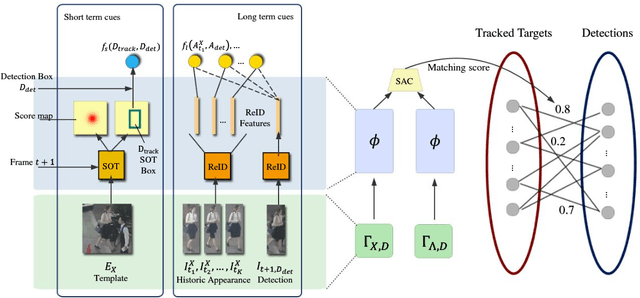
In this paper, we propose a unified Multi-Object Tracking (MOT) framework learning to make full use of long term and short term cues for handling complex cases in MOT scenes. Besides, for better association, we propose switcher-aware classification (SAC), which takes the potential identity-switch causer (switcher) into consideration. Specifically, the proposed framework includes a Single Object Tracking (SOT) sub-net to capture short term cues, a re-identification (ReID) sub-net to extract long term cues and a switcher-aware classifier to make matching decisions using extracted features from the main target and the switcher. Short term cues help to find false negatives, while long term cues avoid critical mistakes when occlusion happens, and the SAC learns to combine multiple cues in an effective way and improves robustness. The method is evaluated on the challenging MOT benchmarks and achieves the state-of-the-art results.
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
Dec 31, 2018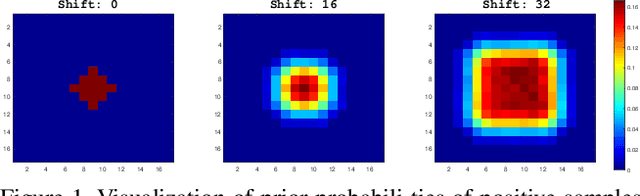
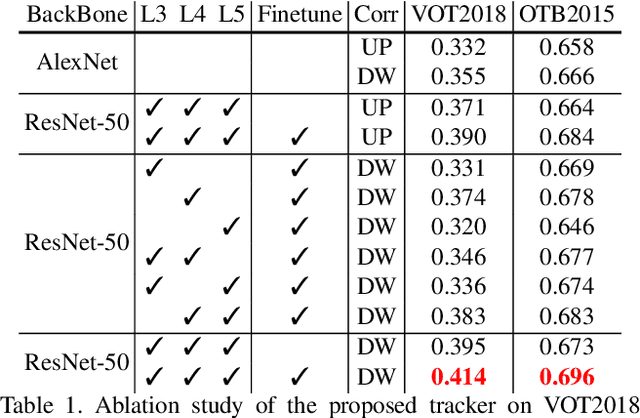
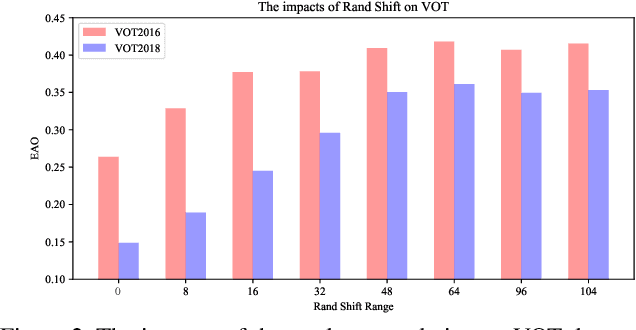

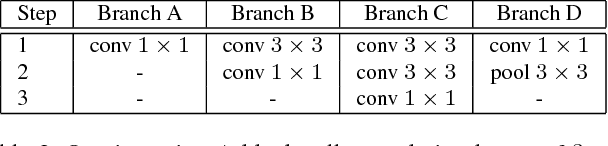
Siamese network based trackers formulate tracking as convolutional feature cross-correlation between target template and searching region. However, Siamese trackers still have accuracy gap compared with state-of-the-art algorithms and they cannot take advantage of feature from deep networks, such as ResNet-50 or deeper. In this work we prove the core reason comes from the lack of strict translation invariance. By comprehensive theoretical analysis and experimental validations, we break this restriction through a simple yet effective spatial aware sampling strategy and successfully train a ResNet-driven Siamese tracker with significant performance gain. Moreover, we propose a new model architecture to perform depth-wise and layer-wise aggregations, which not only further improves the accuracy but also reduces the model size. We conduct extensive ablation studies to demonstrate the effectiveness of the proposed tracker, which obtains currently the best results on four large tracking benchmarks, including OTB2015, VOT2018, UAV123, and LaSOT. Our model will be released to facilitate further studies based on this problem.
IRLAS: Inverse Reinforcement Learning for Architecture Search
Dec 14, 2018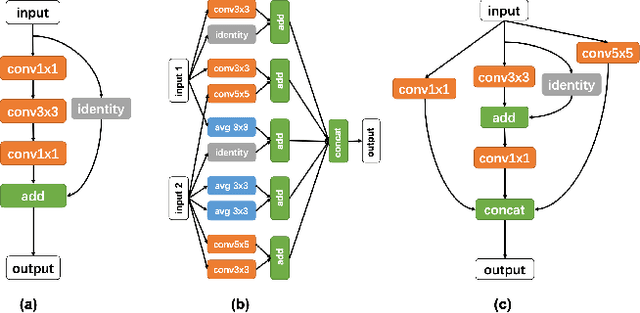
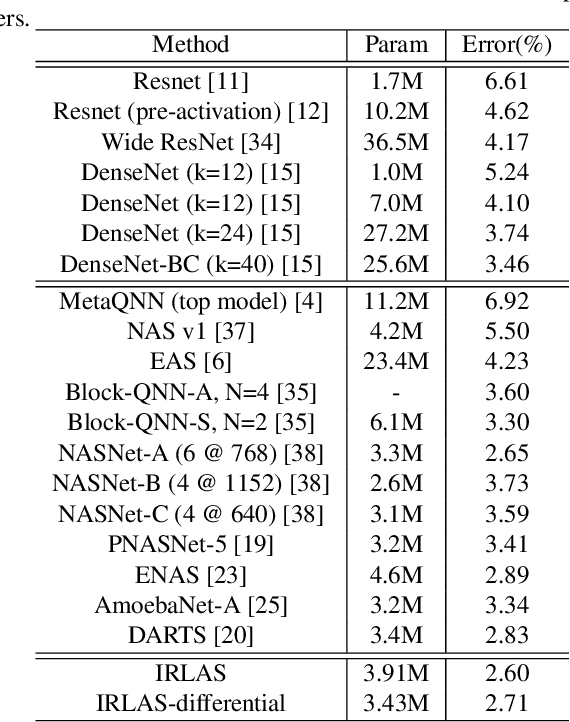
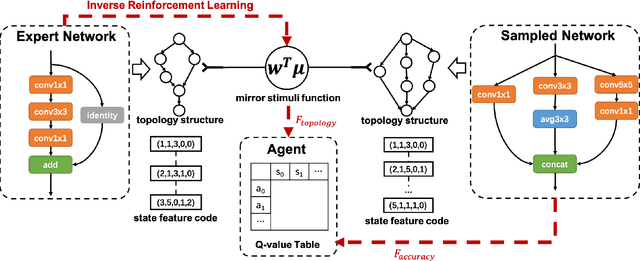
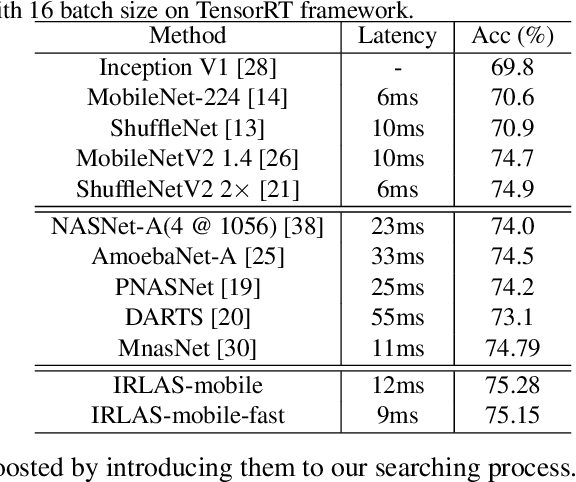
In this paper, we propose an inverse reinforcement learning method for architecture search (IRLAS), which trains an agent to learn to search network structures that are topologically inspired by human-designed network. Most existing architecture search approaches totally neglect the topological characteristics of architectures, which results in complicated architecture with a high inference latency. Motivated by the fact that human-designed networks are elegant in topology with a fast inference speed, we propose a mirror stimuli function inspired by biological cognition theory to extract the abstract topological knowledge of an expert human-design network (ResNeXt). To avoid raising a too strong prior over the search space, we introduce inverse reinforcement learning to train the mirror stimuli function and exploit it as a heuristic guidance for architecture search, easily generalized to different architecture search algorithms. On CIFAR-10, the best architecture searched by our proposed IRLAS achieves 2.60% error rate. For ImageNet mobile setting, our model achieves a state-of-the-art top-1 accuracy 75.28%, while being 2~4x faster than most auto-generated architectures. A fast version of this model achieves 10% faster than MobileNetV2, while maintaining a higher accuracy.
Factorized Attention: Self-Attention with Linear Complexities
Dec 04, 2018


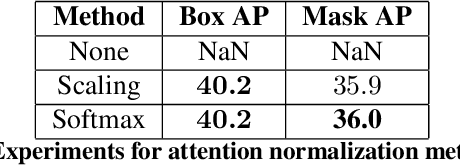
Recent works have been applying self-attention to various fields in computer vision and natural language processing. However, the memory and computational demands of existing self-attention operations grow quadratically with the spatiotemporal size of the input. This prohibits the application of self-attention on large inputs, e.g., long sequences, high-definition images, or large videos. To remedy this, this paper proposes a novel factorized attention (FA) module, which achieves the same expressive power as previous approaches with substantially less memory and computational consumption. The resource-efficiency allows more widespread and flexible application of it. Empirical evaluations on object recognition demonstrate the effectiveness of these advantages. FA-augmented models achieved state-of-the-art performance for object detection and instance segmentation on MS-COCO. Further, the resource-efficiency of FA democratizes self-attention to fields where the prohibitively high costs currently prevent its application. The state-of-the-art result for stereo depth estimation on the Scene Flow dataset exemplifies this.