 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEBATE: A Dataset for Disentangling Textual Ambiguity in Mandarin Through Speech
Jun 09, 2025Despite extensive research on textual and visual disambiguation, disambiguation through speech (DTS) remains underexplored. This is largely due to the lack of high-quality datasets that pair spoken sentences with richly ambiguous text. To address this gap, we present DEBATE, a unique public Chinese speech-text dataset designed to study how speech cues and patterns-pronunciation, pause, stress and intonation-can help resolve textual ambiguity and reveal a speaker's true intent. DEBATE contains 1,001 carefully selected ambiguous utterances, each recorded by 10 native speakers, capturing diverse linguistic ambiguities and their disambiguation through speech. We detail the data collection pipeline and provide rigorous quality analysis. Additionally, we benchmark three state-of-the-art large speech and audio-language models, illustrating clear and huge performance gaps between machine and human understanding of spoken intent. DEBATE represents the first effort of its kind and offers a foundation for building similar DTS datasets across languages and cultures. The dataset and associated code are available at: https://github.com/SmileHnu/DEBATE.
Adaptive Rotated Convolution for Rotated Object Detection
Mar 14, 2023



Rotated object detection aims to identify and locate objects in images with arbitrary orientation. In this scenario, the oriented directions of objects vary considerably across different images, while multiple orientations of objects exist within an image. This intrinsic characteristic makes it challenging for standard backbone networks to extract high-quality features of these arbitrarily orientated objects. In this paper, we present Adaptive Rotated Convolution (ARC) module to handle the aforementioned challenges. In our ARC module, the convolution kernels rotate adaptively to extract object features with varying orientations in different images, and an efficient conditional computation mechanism is introduced to accommodate the large orientation variations of objects within an image. The two designs work seamlessly in rotated object detection problem. Moreover, ARC can conveniently serve as a plug-and-play module in various vision backbones to boost their representation ability to detect oriented objects accurately. Experiments on commonly used benchmarks (DOTA and HRSC2016) demonstrate that equipped with our proposed ARC module in the backbone network, the performance of multiple popular oriented object detectors is significantly improved (e.g. +3.03% mAP on Rotated RetinaNet and +4.16% on CFA). Combined with the highly competitive method Oriented R-CNN, the proposed approach achieves state-of-the-art performance on the DOTA dataset with 81.77% mAP.
Cross Domain Object Detection by Target-Perceived Dual Branch Distillation
May 03, 2022
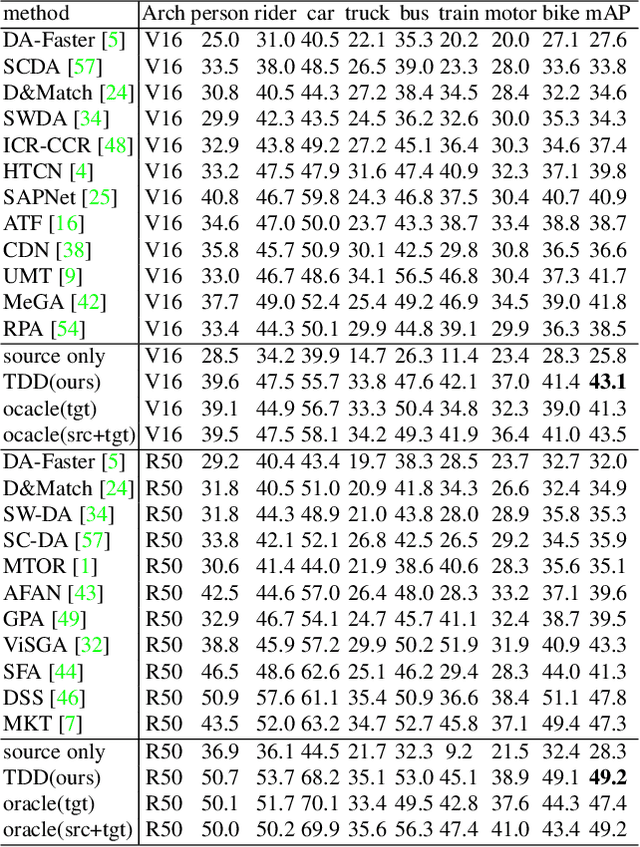
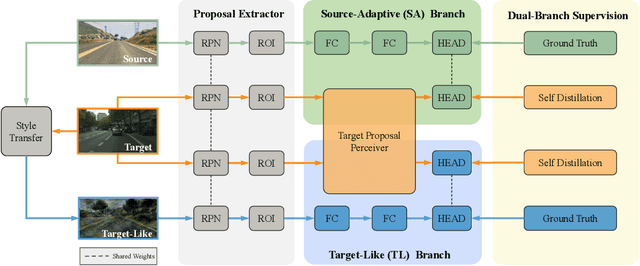
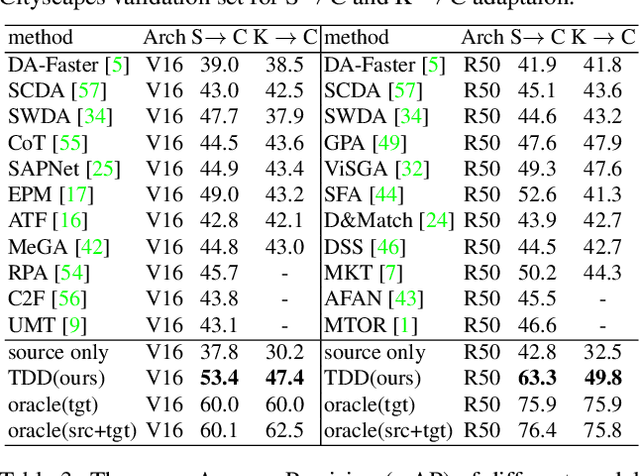
Cross domain object detection is a realistic and challenging task in the wild. It suffers from performance degradation due to large shift of data distributions and lack of instance-level annotations in the target domain. Existing approaches mainly focus on either of these two difficulties, even though they are closely coupled in cross domain object detection. To solve this problem, we propose a novel Target-perceived Dual-branch Distillation (TDD) framework. By integrating detection branches of both source and target domains in a unified teacher-student learning scheme, it can reduce domain shift and generate reliable supervision effectively. In particular, we first introduce a distinct Target Proposal Perceiver between two domains. It can adaptively enhance source detector to perceive objects in a target image, by leveraging target proposal contexts from iterative cross-attention. Afterwards, we design a concise Dual Branch Self Distillation strategy for model training, which can progressively integrate complementary object knowledge from different domains via self-distillation in two branches. Finally, we conduct extensive experiments on a number of widely-used scenarios in cross domain object detection. The results show that our TDD significantly outperforms the state-of-the-art methods on all the benchmarks. Our code and model will be available at https://github.com/Feobi1999/TDD.
Target-Relevant Knowledge Preservation for Multi-Source Domain Adaptive Object Detection
Apr 17, 2022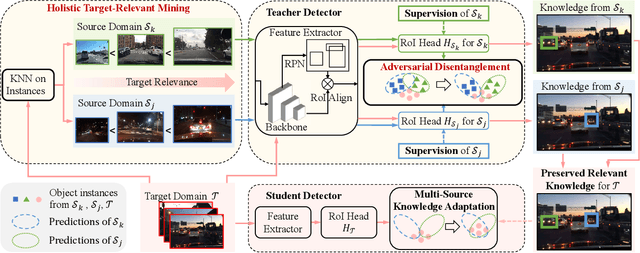
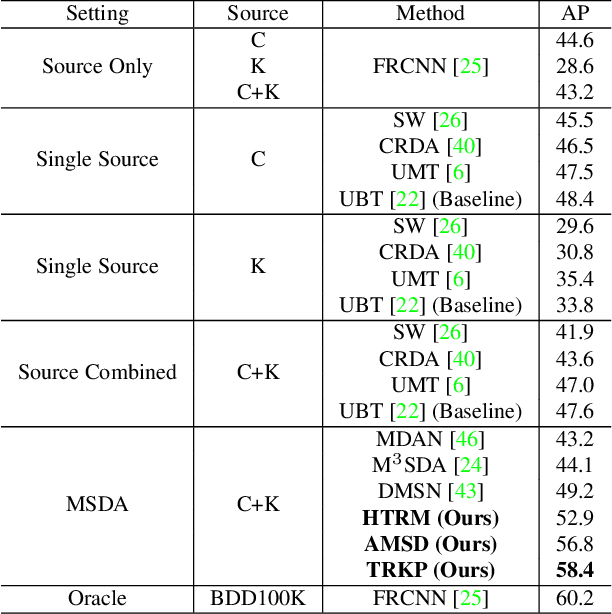
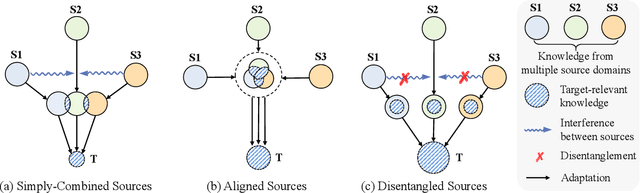
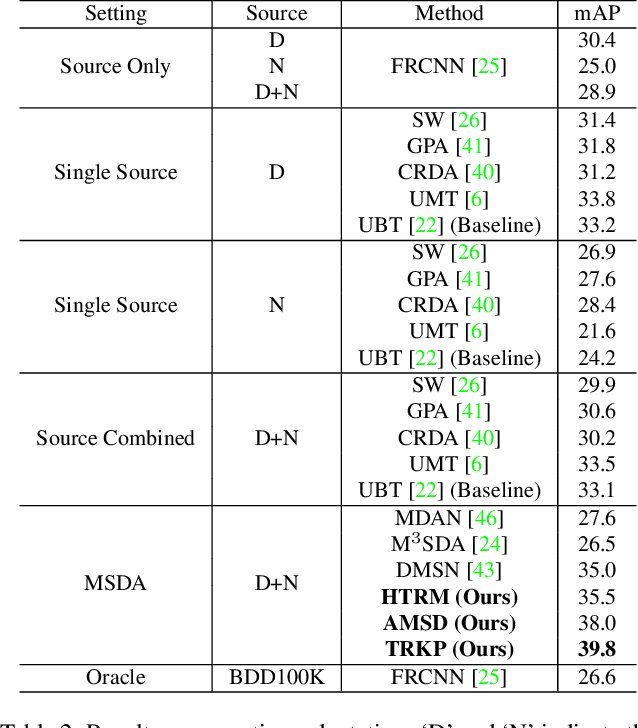
Domain adaptive object detection (DAOD) is a promising way to alleviate performance drop of detectors in new scenes. Albeit great effort made in single source domain adaptation, a more generalized task with multiple source domains remains not being well explored, due to knowledge degradation during their combination. To address this issue, we propose a novel approach, namely target-relevant knowledge preservation (TRKP), to unsupervised multi-source DAOD. Specifically, TRKP adopts the teacher-student framework, where the multi-head teacher network is built to extract knowledge from labeled source domains and guide the student network to learn detectors in unlabeled target domain. The teacher network is further equipped with an adversarial multi-source disentanglement (AMSD) module to preserve source domain-specific knowledge and simultaneously perform cross-domain alignment. Besides, a holistic target-relevant mining (HTRM) scheme is developed to re-weight the source images according to the source-target relevance. By this means, the teacher network is enforced to capture target-relevant knowledge, thus benefiting decreasing domain shift when mentoring object detection in the target domain. Extensive experiments are conducted on various widely used benchmarks with new state-of-the-art scores reported, highlighting the effectiveness.
Unsupervised Learning of Accurate Siamese Tracking
Apr 04, 2022
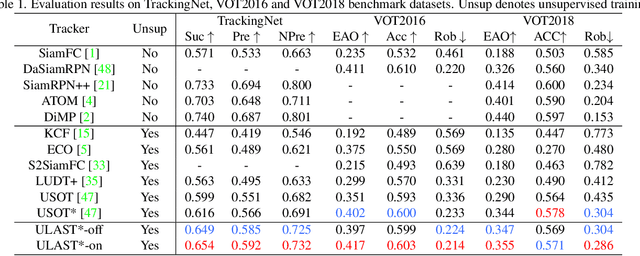
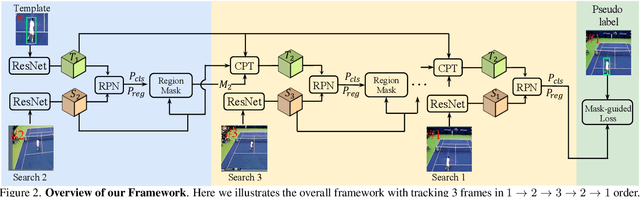
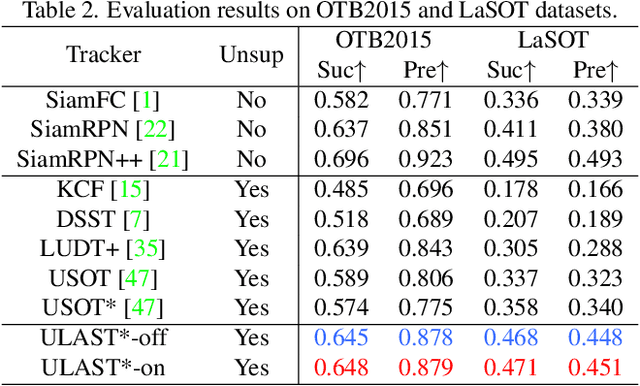
Unsupervised learning has been popular in various computer vision tasks, including visual object tracking. However, prior unsupervised tracking approaches rely heavily on spatial supervision from template-search pairs and are still unable to track objects with strong variation over a long time span. As unlimited self-supervision signals can be obtained by tracking a video along a cycle in time, we investigate evolving a Siamese tracker by tracking videos forward-backward. We present a novel unsupervised tracking framework, in which we can learn temporal correspondence both on the classification branch and regression branch. Specifically, to propagate reliable template feature in the forward propagation process so that the tracker can be trained in the cycle, we first propose a consistency propagation transformation. We then identify an ill-posed penalty problem in conventional cycle training in backward propagation process. Thus, a differentiable region mask is proposed to select features as well as to implicitly penalize tracking errors on intermediate frames. Moreover, since noisy labels may degrade training, we propose a mask-guided loss reweighting strategy to assign dynamic weights based on the quality of pseudo labels. In extensive experiments, our tracker outperforms preceding unsupervised methods by a substantial margin, performing on par with supervised methods on large-scale datasets such as TrackingNet and LaSOT. Code is available at https://github.com/FlorinShum/ULAST.
ActFormer: A GAN Transformer Framework towards General Action-Conditioned 3D Human Motion Generation
Mar 15, 2022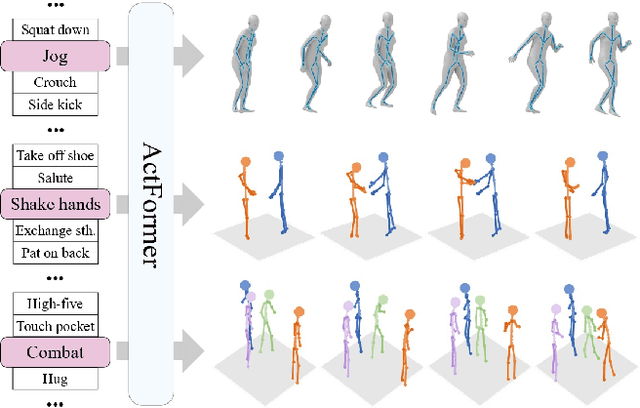

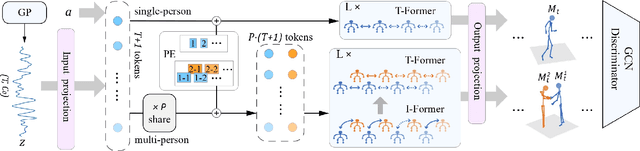

We present a GAN Transformer framework for general action-conditioned 3D human motion generation, including not only single-person actions but also multi-person interactive actions. Our approach consists of a powerful Action-conditioned motion transFormer (ActFormer) under a GAN training scheme, equipped with a Gaussian Process latent prior. Such a design combines the strong spatio-temporal representation capacity of Transformer, superiority in generative modeling of GAN, and inherent temporal correlations from latent prior. Furthermore, ActFormer can be naturally extended to multi-person motions by alternately modeling temporal correlations and human interactions with Transformer encoders. We validate our approach by comparison with other methods on larger-scale benchmarks, including NTU RGB+D 120 and BABEL. We also introduce a new synthetic dataset of complex multi-person combat behaviors to facilitate research on multi-person motion generation. Our method demonstrates adaptability to various human motion representations and achieves leading performance over SOTA methods on both single-person and multi-person motion generation tasks, indicating a hopeful step towards a universal human motion generator.
Backbone is All Your Need: A Simplified Architecture for Visual Object Tracking
Mar 10, 2022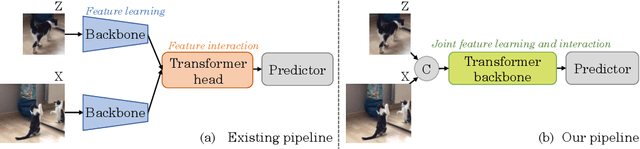
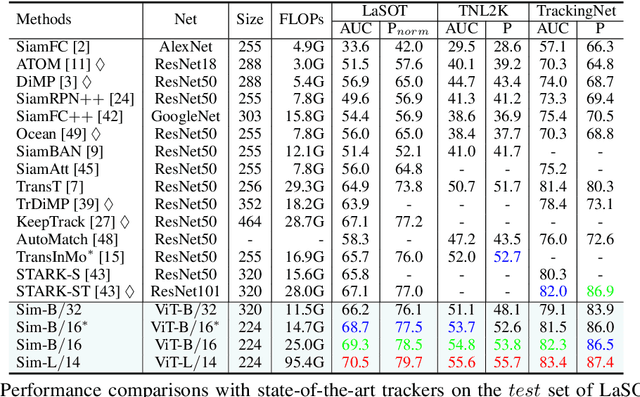
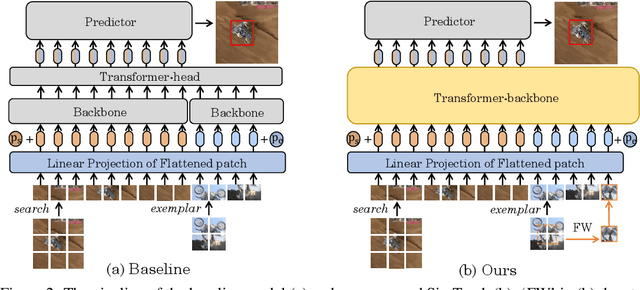
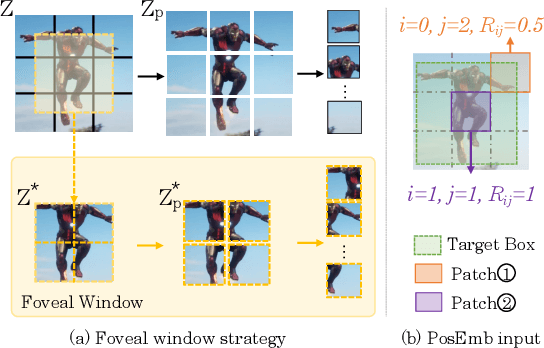
Exploiting a general-purpose neural architecture to replace hand-wired designs or inductive biases has recently drawn extensive interest. However, existing tracking approaches rely on customized sub-modules and need prior knowledge for architecture selection, hindering the tracking development in a more general system. This paper presents a Simplified Tracking architecture (SimTrack) by leveraging a transformer backbone for joint feature extraction and interaction. Unlike existing Siamese trackers, we serialize the input images and concatenate them directly before the one-branch backbone. Feature interaction in the backbone helps to remove well-designed interaction modules and produce a more efficient and effective framework. To reduce the information loss from down-sampling in vision transformers, we further propose a foveal window strategy, providing more diverse input patches with acceptable computational costs. Our SimTrack improves the baseline with 2.5%/2.6% AUC gains on LaSOT/TNL2K and gets results competitive with other specialized tracking algorithms without bells and whistles.
Regularity Learning via Explicit Distribution Modeling for Skeletal Video Anomaly Detection
Dec 08, 2021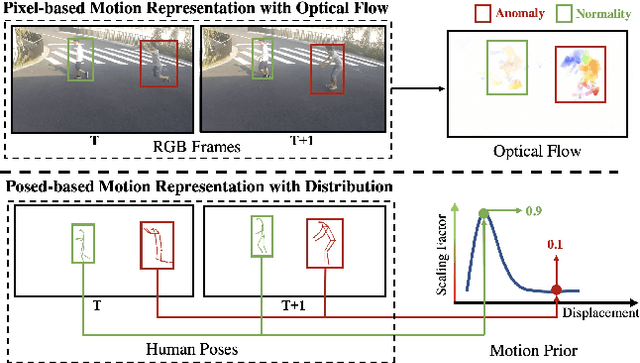
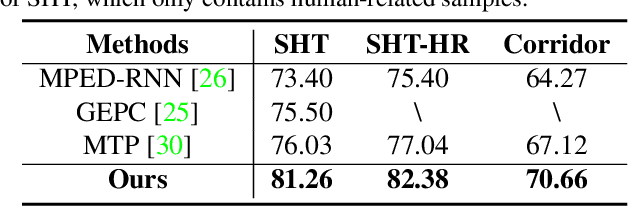
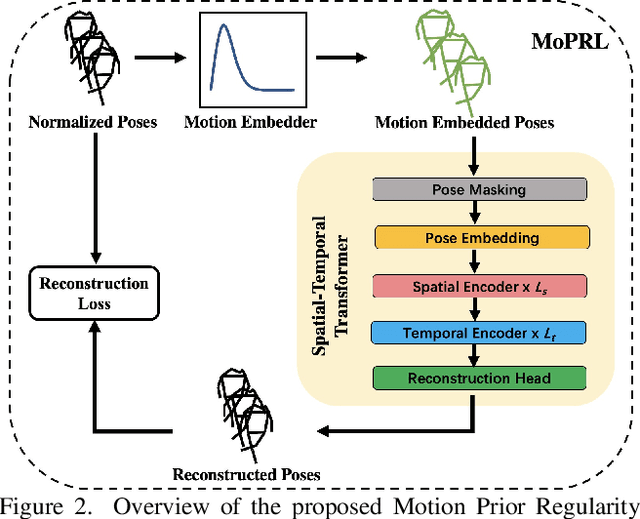

Anomaly detection in surveillance videos is challenging and important for ensuring public security. Different from pixel-based anomaly detection methods, pose-based methods utilize highly-structured skeleton data, which decreases the computational burden and also avoids the negative impact of background noise. However, unlike pixel-based methods, which could directly exploit explicit motion features such as optical flow, pose-based methods suffer from the lack of alternative dynamic representation. In this paper, a novel Motion Embedder (ME) is proposed to provide a pose motion representation from the probability perspective. Furthermore, a novel task-specific Spatial-Temporal Transformer (STT) is deployed for self-supervised pose sequence reconstruction. These two modules are then integrated into a unified framework for pose regularity learning, which is referred to as Motion Prior Regularity Learner (MoPRL). MoPRL achieves the state-of-the-art performance by an average improvement of 4.7% AUC on several challenging datasets. Extensive experiments validate the versatility of each proposed module.
Transferable Knowledge-Based Multi-Granularity Aggregation Network for Temporal Action Localization: Submission to ActivityNet Challenge 2021
Jul 27, 2021
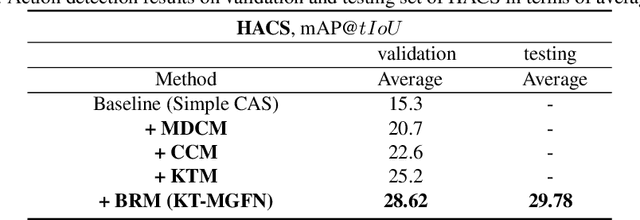
This technical report presents an overview of our solution used in the submission to 2021 HACS Temporal Action Localization Challenge on both Supervised Learning Track and Weakly-Supervised Learning Track. Temporal Action Localization (TAL) requires to not only precisely locate the temporal boundaries of action instances, but also accurately classify the untrimmed videos into specific categories. However, Weakly-Supervised TAL indicates locating the action instances using only video-level class labels. In this paper, to train a supervised temporal action localizer, we adopt Temporal Context Aggregation Network (TCANet) to generate high-quality action proposals through ``local and global" temporal context aggregation and complementary as well as progressive boundary refinement. As for the WSTAL, a novel framework is proposed to handle the poor quality of CAS generated by simple classification network, which can only focus on local discriminative parts, rather than locate the entire interval of target actions. Further inspired by the transfer learning method, we also adopt an additional module to transfer the knowledge from trimmed videos (HACS Clips dataset) to untrimmed videos (HACS Segments dataset), aiming at promoting the classification performance on untrimmed videos. Finally, we employ a boundary regression module embedded with Outer-Inner-Contrastive (OIC) loss to automatically predict the boundaries based on the enhanced CAS. Our proposed scheme achieves 39.91 and 29.78 average mAP on the challenge testing set of supervised and weakly-supervised temporal action localization track respectively.
TSI: Temporal Saliency Integration for Video Action Recognition
Jun 02, 2021
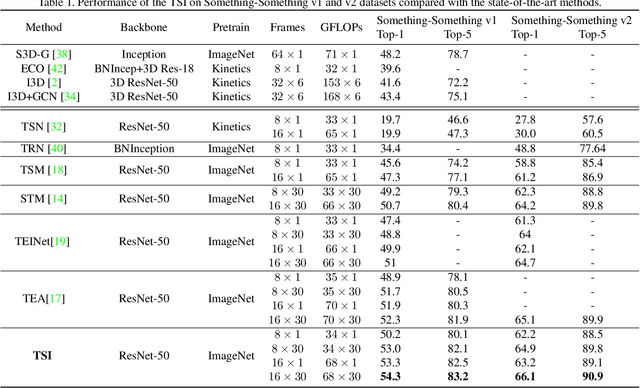
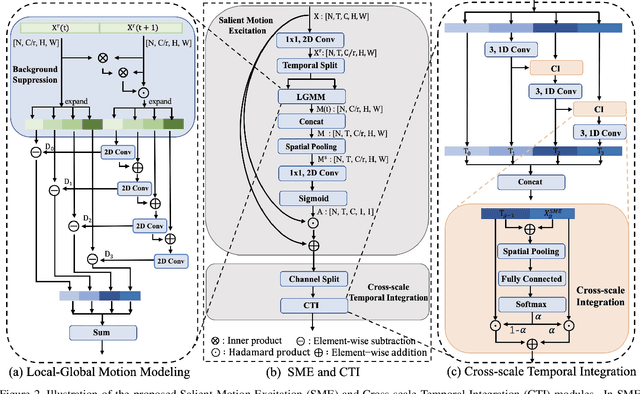
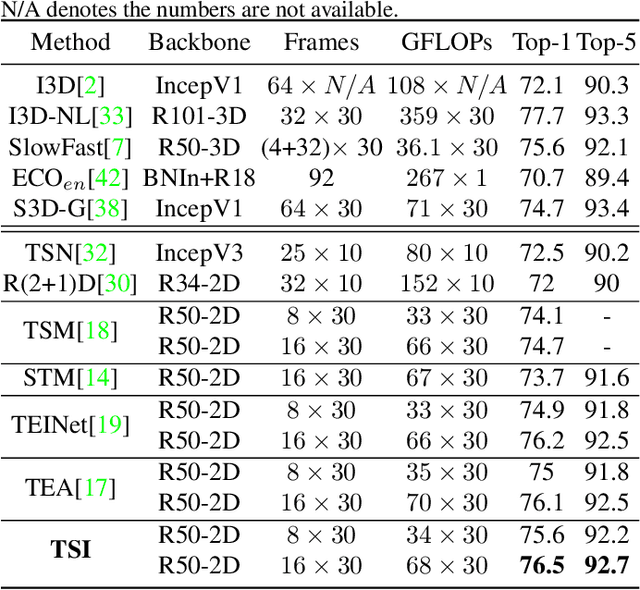
Efficient spatiotemporal modeling is an important yet challenging problem for video action recognition. Existing state-of-the-art methods exploit motion clues to assist in short-term temporal modeling through temporal difference over consecutive frames. However, background noises will be inevitably introduced due to the camera movement. Besides, movements of different actions can vary greatly. In this paper, we propose a Temporal Saliency Integration (TSI) block, which mainly contains a Salient Motion Excitation (SME) module and a Cross-scale Temporal Integration (CTI) module. Specifically, SME aims to highlight the motion-sensitive area through local-global motion modeling, where the background suppression and pyramidal feature difference are conducted successively between neighboring frames to capture motion dynamics with less background noises. CTI is designed to perform multi-scale temporal modeling through a group of separate 1D convolutions respectively. Meanwhile, temporal interactions across different scales are integrated with attention mechanism. Through these two modules, long short-term temporal relationships can be encoded efficiently by introducing limited additional parameters. Extensive experiments are conducted on several popular benchmarks (i.e., Something-Something v1 & v2, Kinetics-400, UCF-101, and HMDB-51), which demonstrate the effectiveness and superiority of our proposed method.