 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSashimi-Bot: Autonomous Tri-manual Advanced Manipulation and Cutting of Deformable Objects
Nov 14, 2025Advanced robotic manipulation of deformable, volumetric objects remains one of the greatest challenges due to their pliancy, frailness, variability, and uncertainties during interaction. Motivated by these challenges, this article introduces Sashimi-Bot, an autonomous multi-robotic system for advanced manipulation and cutting, specifically the preparation of sashimi. The objects that we manipulate, salmon loins, are natural in origin and vary in size and shape, they are limp and deformable with poorly characterized elastoplastic parameters, while also being slippery and hard to hold. The three robots straighten the loin; grasp and hold the knife; cut with the knife in a slicing motion while cooperatively stabilizing the loin during cutting; and pick up the thin slices from the cutting board or knife blade. Our system combines deep reinforcement learning with in-hand tool shape manipulation, in-hand tool cutting, and feedback of visual and tactile information to achieve robustness to the variabilities inherent in this task. This work represents a milestone in robotic manipulation of deformable, volumetric objects that may inspire and enable a wide range of other real-world applications.
Towards Assessing Compliant Robotic Grasping from First-Object Perspective via Instrumented Objects
Jan 15, 2024



Grasping compliant objects is difficult for robots - applying too little force may cause the grasp to fail, while too much force may lead to object damage. A robot needs to apply the right amount of force to quickly and confidently grasp the objects so that it can perform the required task. Although some methods have been proposed to tackle this issue, performance assessment is still a problem for directly measuring object property changes and possible damage. To fill the gap, a new concept is introduced in this paper to assess compliant robotic grasping using instrumented objects. A proof-of-concept design is proposed to measure the force applied on a cuboid object from a first-object perspective. The design can detect multiple contact locations and applied forces on its surface by using multiple embedded 3D Hall sensors to detect deformation relative to embedded magnets. The contact estimation is achieved by interpreting the Hall-effect signals using neural networks. In comprehensive experiments, the design achieved good performance in estimating contacts from each single face of the cuboid and decent performance in detecting contacts from multiple faces when being used to evaluate grasping from a parallel jaw gripper, demonstrating the effectiveness of the design and the feasibility of the concept.
Re-evaluating Parallel Finger-tip Tactile Sensing for Inferring Object Adjectives: An Empirical Study
Mar 12, 2023



Finger-tip tactile sensors are increasingly used for robotic sensing to establish stable grasps and to infer object properties. Promising performance has been shown in a number of works for inferring adjectives that describe the object, but there remains a question about how each taxel contributes to the performance. This paper explores this question with empirical experiments, leading insights for future finger-tip tactile sensor usage and design.
Learning Fabric Manipulation in the Real World with Human Videos
Nov 12, 2022



Fabric manipulation is a long-standing challenge in robotics due to the enormous state space and complex dynamics. Learning approaches stand out as promising for this domain as they allow us to learn behaviours directly from data. Most prior methods however rely heavily on simulation, which is still limited by the large sim-to-real gap of deformable objects or rely on large datasets. A promising alternative is to learn fabric manipulation directly from watching humans perform the task. In this work, we explore how demonstrations for fabric manipulation tasks can be collected directly by humans, providing an extremely natural and fast data collection pipeline. Then, using only a handful of such demonstrations, we show how a pick-and-place policy can be learned and deployed on a real robot, without any robot data collection at all. We demonstrate our approach on a fabric folding task, showing that our policy can reliably reach folded states from crumpled initial configurations. Videos are available at: https://sites.google.com/view/foldingbyhand
Ada-NETS: Face Clustering via Adaptive Neighbour Discovery in the Structure Space
Feb 08, 2022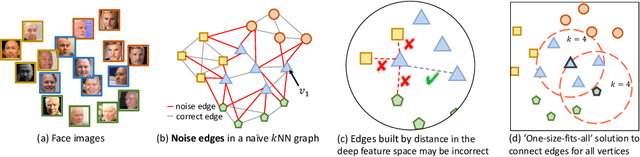
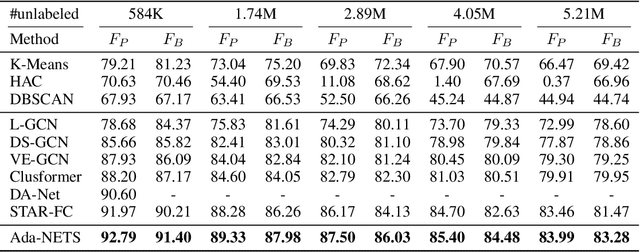
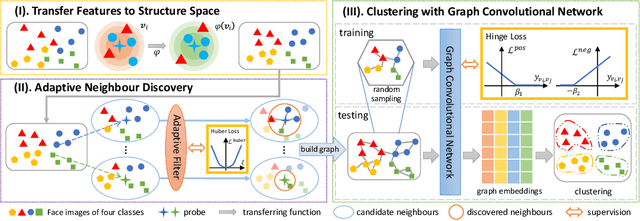
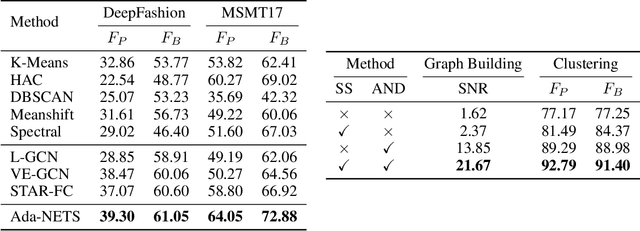
Face clustering has attracted rising research interest recently to take advantage of massive amounts of face images on the web. State-of-the-art performance has been achieved by Graph Convolutional Networks (GCN) due to their powerful representation capacity. However, existing GCN-based methods build face graphs mainly according to kNN relations in the feature space, which may lead to a lot of noise edges connecting two faces of different classes. The face features will be polluted when messages pass along these noise edges, thus degrading the performance of GCNs. In this paper, a novel algorithm named Ada-NETS is proposed to cluster faces by constructing clean graphs for GCNs. In Ada-NETS, each face is transformed to a new structure space, obtaining robust features by considering face features of the neighbour images. Then, an adaptive neighbour discovery strategy is proposed to determine a proper number of edges connecting to each face image. It significantly reduces the noise edges while maintaining the good ones to build a graph with clean yet rich edges for GCNs to cluster faces. Experiments on multiple public clustering datasets show that Ada-NETS significantly outperforms current state-of-the-art methods, proving its superiority and generalization.
Interpolation variable rate image compression
Sep 20, 2021
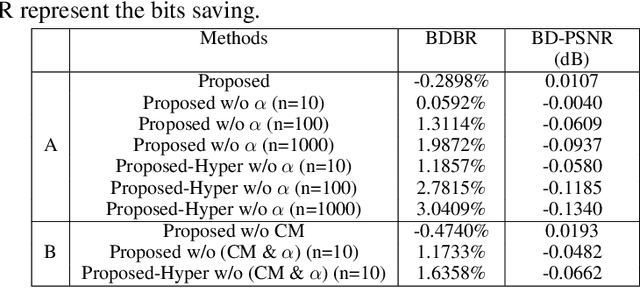
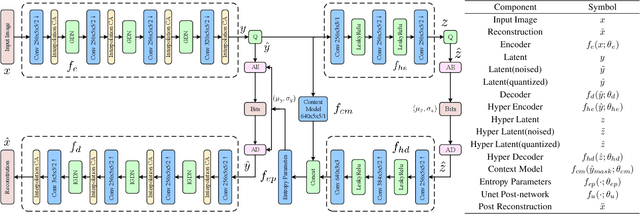
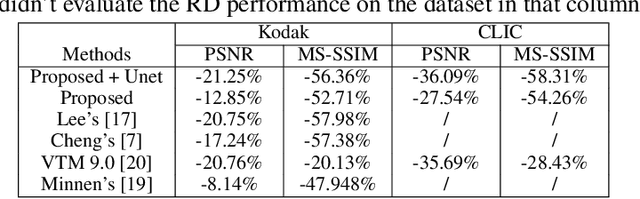
Compression standards have been used to reduce the cost of image storage and transmission for decades. In recent years, learned image compression methods have been proposed and achieved compelling performance to the traditional standards. However, in these methods, a set of different networks are used for various compression rates, resulting in a high cost in model storage and training. Although some variable-rate approaches have been proposed to reduce the cost by using a single network, most of them brought some performance degradation when applying fine rate control. To enable variable-rate control without sacrificing the performance, we propose an efficient Interpolation Variable-Rate (IVR) network, by introducing a handy Interpolation Channel Attention (InterpCA) module in the compression network. With the use of two hyperparameters for rate control and linear interpolation, the InterpCA achieves a fine PSNR interval of 0.001 dB and a fine rate interval of 0.0001 Bits-Per-Pixel (BPP) with 9000 rates in the IVR network. Experimental results demonstrate that the IVR network is the first variable-rate learned method that outperforms VTM 9.0 (intra) in PSNR and Multiscale Structural Similarity (MS-SSIM).
Fine-Grained AutoAugmentation for Multi-Label Classification
Jul 13, 2021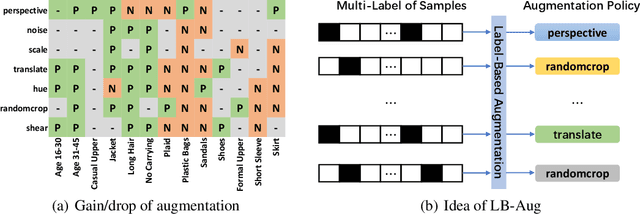
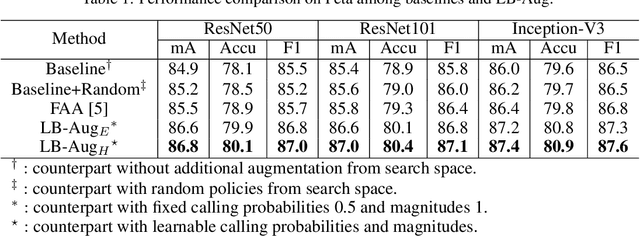
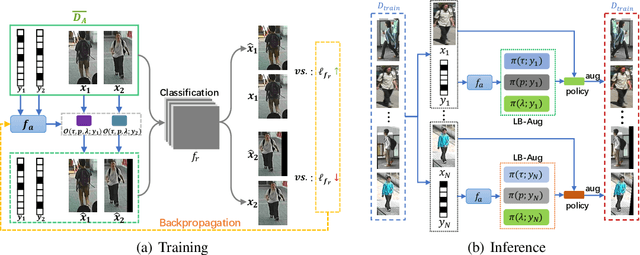
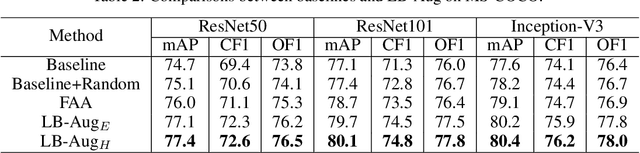
Data augmentation is a commonly used approach to improving the generalization of deep learning models. Recent works show that learned data augmentation policies can achieve better generalization than hand-crafted ones. However, most of these works use unified augmentation policies for all samples in a dataset, which is observed not necessarily beneficial for all labels in multi-label classification tasks, i.e., some policies may have negative impacts on some labels while benefitting the others. To tackle this problem, we propose a novel Label-Based AutoAugmentation (LB-Aug) method for multi-label scenarios, where augmentation policies are generated with respect to labels by an augmentation-policy network. The policies are learned via reinforcement learning using policy gradient methods, providing a mapping from instance labels to their optimal augmentation policies. Numerical experiments show that our LB-Aug outperforms previous state-of-the-art augmentation methods by large margins in multiple benchmarks on image and video classification.
GCN-Based Linkage Prediction for Face Clustering on Imbalanced Datasets: An Empirical Study
Jul 07, 2021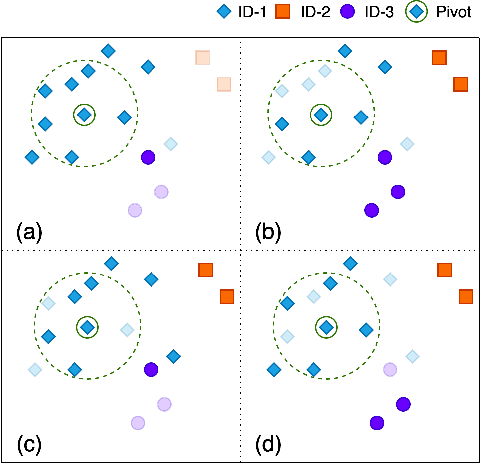
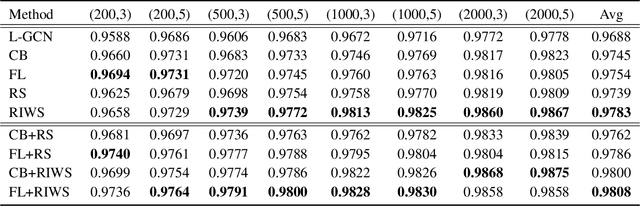
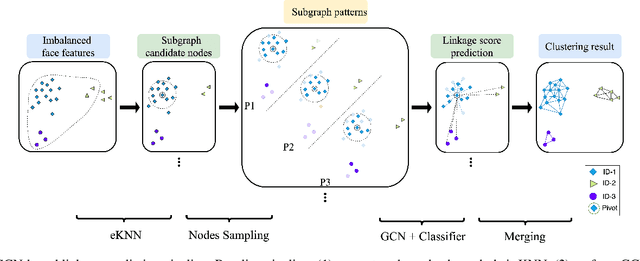
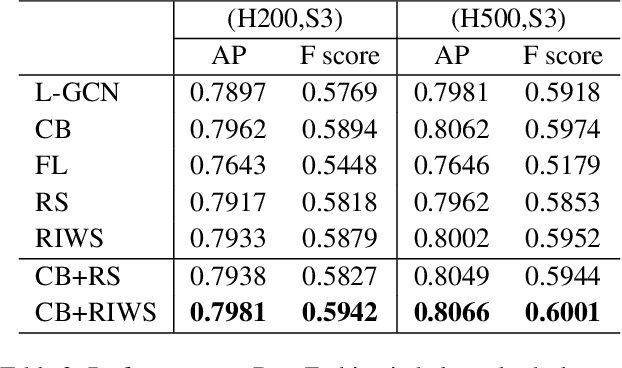
In recent years, benefiting from the expressive power of Graph Convolutional Networks (GCNs), significant breakthroughs have been made in face clustering. However, rare attention has been paid to GCN-based clustering on imbalanced data. Although imbalance problem has been extensively studied, the impact of imbalanced data on GCN-based linkage prediction task is quite different, which would cause problems in two aspects: imbalanced linkage labels and biased graph representations. The problem of imbalanced linkage labels is similar to that in image classification task, but the latter is a particular problem in GCN-based clustering via linkage prediction. Significantly biased graph representations in training can cause catastrophic overfitting of a GCN model. To tackle these problems, we evaluate the feasibility of those existing methods for imbalanced image classification problem on graphs with extensive experiments, and present a new method to alleviate the imbalanced labels and also augment graph representations using a Reverse-Imbalance Weighted Sampling (RIWS) strategy, followed with insightful analyses and discussions. The code and a series of imbalanced benchmark datasets synthesized from MS-Celeb-1M and DeepFashion are available on https://github.com/espectre/GCNs_on_imbalanced_datasets.
Importance Weighted Adversarial Discriminative Transfer for Anomaly Detection
May 19, 2021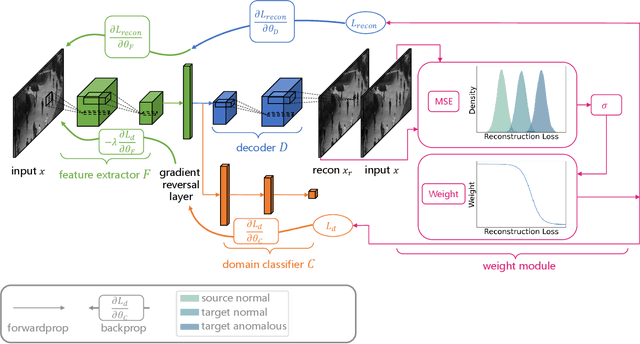
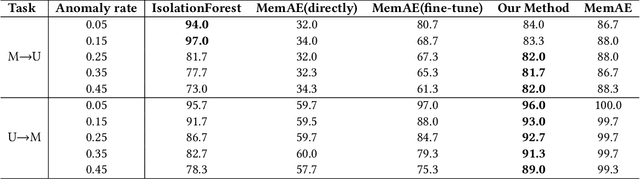
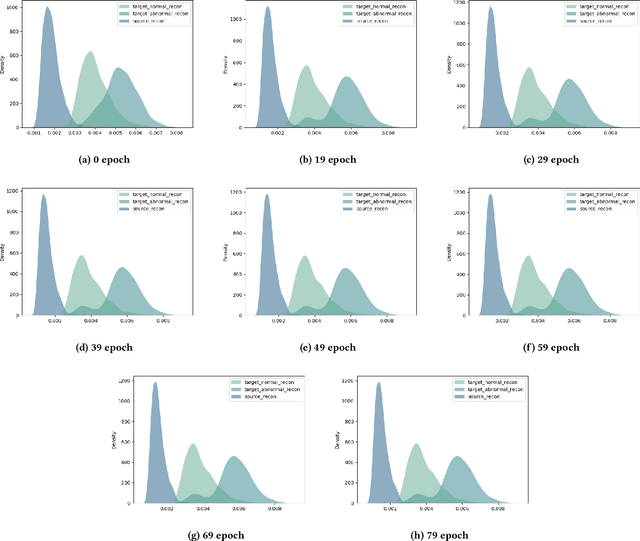
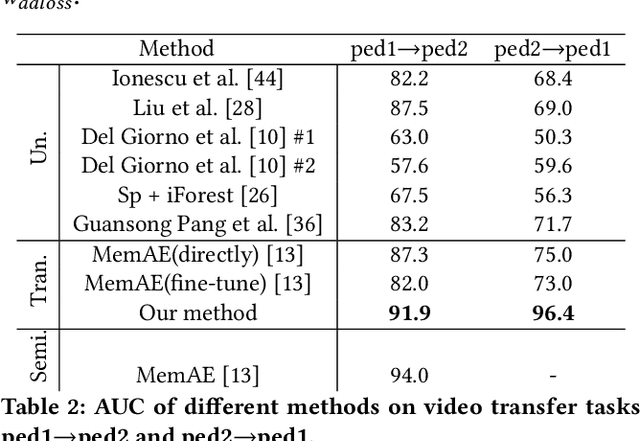
Previous transfer methods for anomaly detection generally assume the availability of labeled data in source or target domains. However, such an assumption is not valid in most real applications where large-scale labeled data are too expensive. Therefore, this paper proposes an importance weighted adversarial autoencoder-based method to transfer anomaly detection knowledge in an unsupervised manner, particularly for a rarely studied scenario where a target domain has no labeled normal/abnormal data while only normal data from a related source domain exist. Specifically, the method learns to align the distributions of normal data in both source and target domains, but leave the distribution of abnormal data in the target domain unchanged. In this way, an obvious gap can be produced between the distributions of normal and abnormal data in the target domain, therefore enabling the anomaly detection in the domain. Extensive experiments on multiple synthetic datasets and the UCSD benchmark demonstrate the effectiveness of our approach.
Spatiotemporal Entropy Model is All You Need for Learned Video Compression
Apr 13, 2021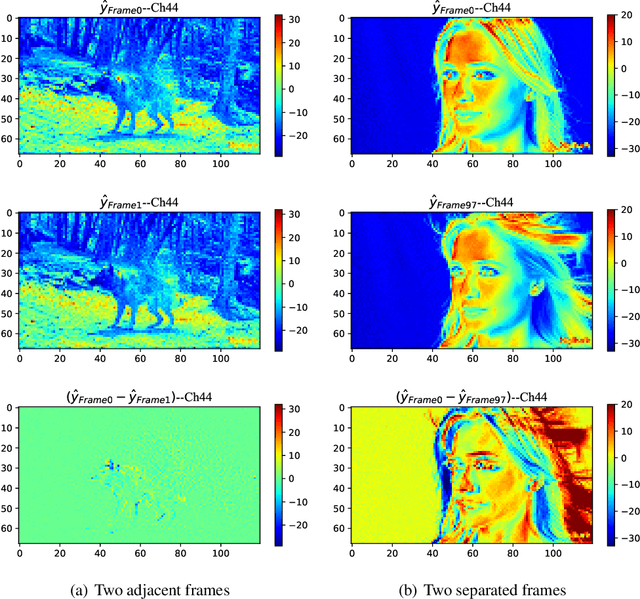

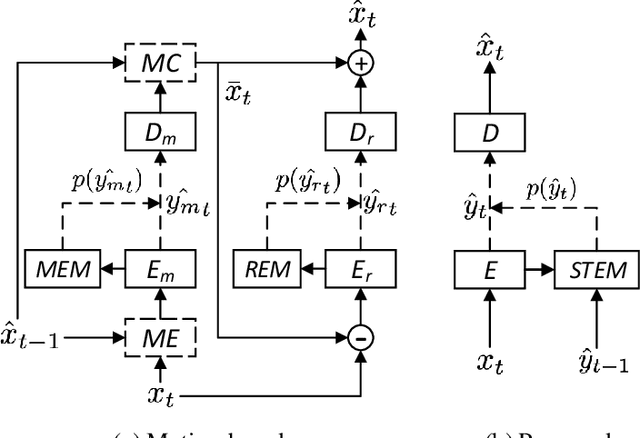
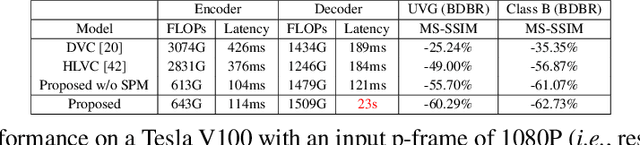
The framework of dominant learned video compression methods is usually composed of motion prediction modules as well as motion vector and residual image compression modules, suffering from its complex structure and error propagation problem. Approaches have been proposed to reduce the complexity by replacing motion prediction modules with implicit flow networks. Error propagation aware training strategy is also proposed to alleviate incremental reconstruction errors from previously decoded frames. Although these methods have brought some improvement, little attention has been paid to the framework itself. Inspired by the success of learned image compression through simplifying the framework with a single deep neural network, it is natural to expect a better performance in video compression via a simple yet appropriate framework. Therefore, we propose a framework to directly compress raw-pixel frames (rather than residual images), where no extra motion prediction module is required. Instead, an entropy model is used to estimate the spatiotemporal redundancy in a latent space rather than pixel level, which significantly reduces the complexity of the framework. Specifically, the whole framework is a compression module, consisting of a unified auto-encoder which produces identically distributed latents for all frames, and a spatiotemporal entropy estimation model to minimize the entropy of these latents. Experiments showed that the proposed method outperforms state-of-the-art (SOTA) performance under the metric of multiscale structural similarity (MS-SSIM) and achieves competitive results under the metric of PSNR.