 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Explorative Policy Optimization for Multimodal Agentic Reasoning
May 27, 2026Vision-language models with extended reasoning succeed on complex problems, but many real-world problems require external tools that internal reasoning alone often cannot resolve. Agentic reasoning therefore interleaves two behaviors with a structural asymmetry: thinking (the self-contained default) and tool use (a high-variance auxiliary acting). We refer to this asymmetry as the Thinking-Acting Gap. Under standard RL recipes like GRPO, the gap manifests as two diagnostic symptoms during training: tool use is attempted on only ~30% of rollouts, and when attempted, the tool-using rollouts within a group are all-wrong on ~40% of questions, suppressing the learning signal at the tool calls that needed it. We propose AXPO (Agent eXplorative Policy Optimization): for each all-wrong tool-using subgroup, AXPO fixes the thinking prefix and resamples the tool call and its continuation, paired with uncertainty-based prefix selection. Across nine multimodal benchmarks and three scales of Qwen3-VL-Thinking, SFT+AXPO outperforms SFT+GRPO at average (+1.8pp Pass@1 and +1.8pp Pass@4 at 8B on average) and 8B with SFT+AXPO surpasses the 32B Base on Pass@4 with 4 times fewer parameters.
Recursive Multi-Agent Systems
Apr 28, 2026Recursive or looped language models have recently emerged as a new scaling axis by iteratively refining the same model computation over latent states to deepen reasoning. We extend such scaling principle from a single model to multi-agent systems, and ask: Can agent collaboration itself be scaled through recursion? To this end, we introduce RecursiveMAS, a recursive multi-agent framework that casts the entire system as a unified latent-space recursive computation. RecursiveMAS connects heterogeneous agents as a collaboration loop through the lightweight RecursiveLink module, enabling in-distribution latent thoughts generation and cross-agent latent state transfer. To optimize our framework, we develop an inner-outer loop learning algorithm for iterative whole-system co-optimization through shared gradient-based credit assignment across recursion rounds. Theoretical analyses of runtime complexity and learning dynamics establish that RecursiveMAS is more efficient than standard text-based MAS and maintains stable gradients during recursive training. Empirically, we instantiate RecursiveMAS under 4 representative agent collaboration patterns and evaluate across 9 benchmarks spanning mathematics, science, medicine, search, and code generation. In comparison with advanced single/multi-agent and recursive computation baselines, RecursiveMAS consistently delivers an average accuracy improvement of 8.3%, together with 1.2$\times$-2.4$\times$ end-to-end inference speedup, and 34.6%-75.6% token usage reduction. Code and Data are provided in https://recursivemas.github.io.
ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
Mar 19, 2026Multi-turn LLM agents are increasingly important for solving complex, interactive tasks, and reinforcement learning (RL) is a key ingredient for improving their long-horizon behavior. However, RL training requires generating large numbers of sandboxed rollout trajectories, and existing infrastructures often couple rollout orchestration with the training loop, making systems hard to migrate and maintain. Under the rollout-as-a-service philosophy, we present ProRL Agent , a scalable infrastructure that serves the full agentic rollout lifecycle through an API service. ProRL Agent also provides standardized and extensible sandbox environments that support diverse agentic tasks in rootless HPC settings. We validate ProRL Agent through RL training on software engineering, math, STEM, and coding tasks. ProRL Agent is open-sourced and integrated as part of NVIDIA NeMo Gym.
Progressive Residual Warmup for Language Model Pretraining
Mar 05, 2026Transformer architectures serve as the backbone for most modern Large Language Models, therefore their pretraining stability and convergence speed are of central concern. Motivated by the logical dependency of sequentially stacked layers, we propose Progressive Residual Warmup (ProRes) for language model pretraining. ProRes implements an "early layer learns first" philosophy by multiplying each layer's residual with a scalar that gradually warms up from 0 to 1, with deeper layers taking longer warmup steps. In this way, deeper layers wait for early layers to settle into a more stable regime before contributing to learning. We demonstrate the effectiveness of ProRes through pretraining experiments across various model scales, as well as normalization and initialization schemes. Comprehensive analysis shows that ProRes not only stabilizes pretraining but also introduces a unique optimization trajectory, leading to faster convergence, stronger generalization and better downstream performance. Our code is available at https://github.com/dandingsky/ProRes.
Golden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
Speech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
Efficient-DLM: From Autoregressive to Diffusion Language Models, and Beyond in Speed
Dec 16, 2025



Diffusion language models (dLMs) have emerged as a promising paradigm that enables parallel, non-autoregressive generation, but their learning efficiency lags behind that of autoregressive (AR) language models when trained from scratch. To this end, we study AR-to-dLM conversion to transform pretrained AR models into efficient dLMs that excel in speed while preserving AR models' task accuracy. We achieve this by identifying limitations in the attention patterns and objectives of existing AR-to-dLM methods and then proposing principles and methodologies for more effective AR-to-dLM conversion. Specifically, we first systematically compare different attention patterns and find that maintaining pretrained AR weight distributions is critical for effective AR-to-dLM conversion. As such, we introduce a continuous pretraining scheme with a block-wise attention pattern, which remains causal across blocks while enabling bidirectional modeling within each block. We find that this approach can better preserve pretrained AR models' weight distributions than fully bidirectional modeling, in addition to its known benefit of enabling KV caching, and leads to a win-win in accuracy and efficiency. Second, to mitigate the training-test gap in mask token distributions (uniform vs. highly left-to-right), we propose a position-dependent token masking strategy that assigns higher masking probabilities to later tokens during training to better mimic test-time behavior. Leveraging this framework, we conduct extensive studies of dLMs' attention patterns, training dynamics, and other design choices, providing actionable insights into scalable AR-to-dLM conversion. These studies lead to the Efficient-DLM family, which outperforms state-of-the-art AR models and dLMs, e.g., our Efficient-DLM 8B achieves +5.4%/+2.7% higher accuracy with 4.5x/2.7x higher throughput compared to Dream 7B and Qwen3 4B, respectively.
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Oct 21, 2025

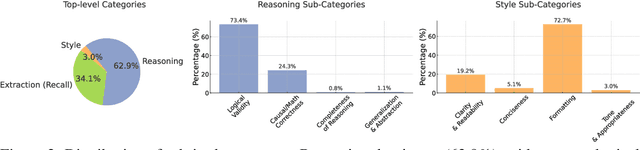
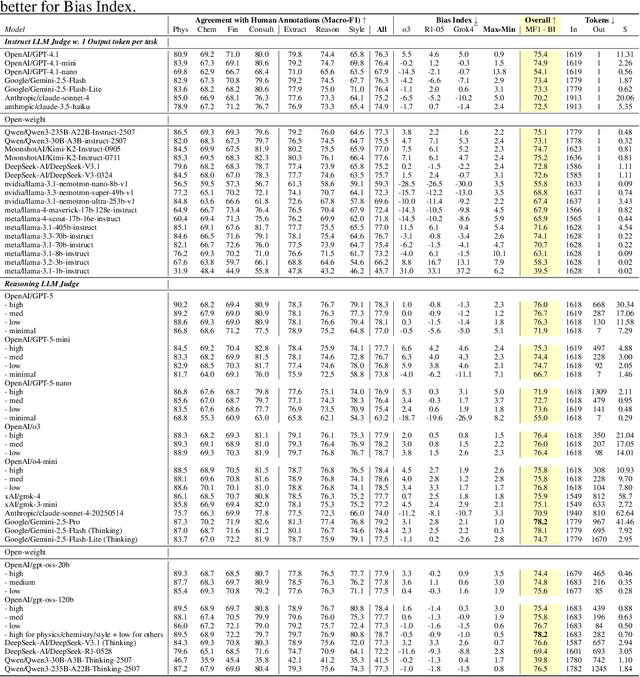
Evaluating progress in large language models (LLMs) is often constrained by the challenge of verifying responses, limiting assessments to tasks like mathematics, programming, and short-form question-answering. However, many real-world applications require evaluating LLMs in processing professional documents, synthesizing information, and generating comprehensive reports in response to user queries. We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias and reducing the cost of evaluation by 2-3 orders of magnitude, to make it fair and accessible to the broader community. Our findings reveal that ProfBench poses significant challenges even for state-of-the-art LLMs, with top-performing models like GPT-5-high achieving only 65.9\% overall performance. Furthermore, we identify notable performance disparities between proprietary and open-weight models and provide insights into the role that extended thinking plays in addressing complex, professional-domain tasks. Data: https://huggingface.co/datasets/nvidia/ProfBench and Code: https://github.com/NVlabs/ProfBench
Generalizable Geometric Image Caption Synthesis
Sep 18, 2025Multimodal large language models have various practical applications that demand strong reasoning abilities. Despite recent advancements, these models still struggle to solve complex geometric problems. A key challenge stems from the lack of high-quality image-text pair datasets for understanding geometric images. Furthermore, most template-based data synthesis pipelines typically fail to generalize to questions beyond their predefined templates. In this paper, we bridge this gap by introducing a complementary process of Reinforcement Learning with Verifiable Rewards (RLVR) into the data generation pipeline. By adopting RLVR to refine captions for geometric images synthesized from 50 basic geometric relations and using reward signals derived from mathematical problem-solving tasks, our pipeline successfully captures the key features of geometry problem-solving. This enables better task generalization and yields non-trivial improvements. Furthermore, even in out-of-distribution scenarios, the generated dataset enhances the general reasoning capabilities of multimodal large language models, yielding accuracy improvements of $2.8\%\text{-}4.8\%$ in statistics, arithmetic, algebraic, and numerical tasks with non-geometric input images of MathVista and MathVerse, along with $2.4\%\text{-}3.9\%$ improvements in Art, Design, Tech, and Engineering tasks in MMMU.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.