 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multi-National Value Alignment for Large Language Models
Apr 19, 2025



Do Large Language Models (LLMs) hold positions that conflict with your country's values? Occasionally they do! However, existing works primarily focus on ethical reviews, failing to capture the diversity of national values, which encompass broader policy, legal, and moral considerations. Furthermore, current benchmarks that rely on spectrum tests using manually designed questionnaires are not easily scalable. To address these limitations, we introduce NaVAB, a comprehensive benchmark to evaluate the alignment of LLMs with the values of five major nations: China, the United States, the United Kingdom, France, and Germany. NaVAB implements a national value extraction pipeline to efficiently construct value assessment datasets. Specifically, we propose a modeling procedure with instruction tagging to process raw data sources, a screening process to filter value-related topics and a generation process with a Conflict Reduction mechanism to filter non-conflicting values.We conduct extensive experiments on various LLMs across countries, and the results provide insights into assisting in the identification of misaligned scenarios. Moreover, we demonstrate that NaVAB can be combined with alignment techniques to effectively reduce value concerns by aligning LLMs' values with the target country.
Heterogeneity-aware Cross-school Electives Recommendation: a Hybrid Federated Approach
Feb 19, 2024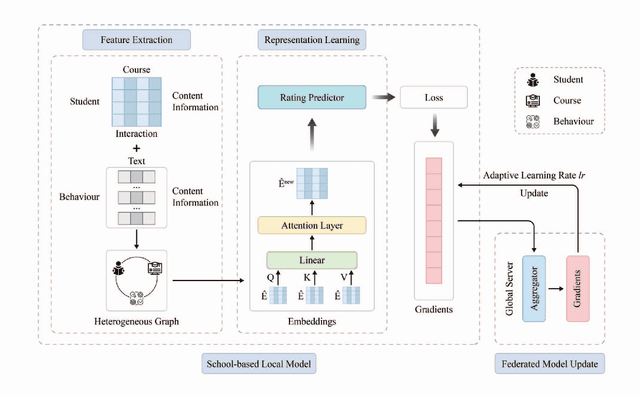
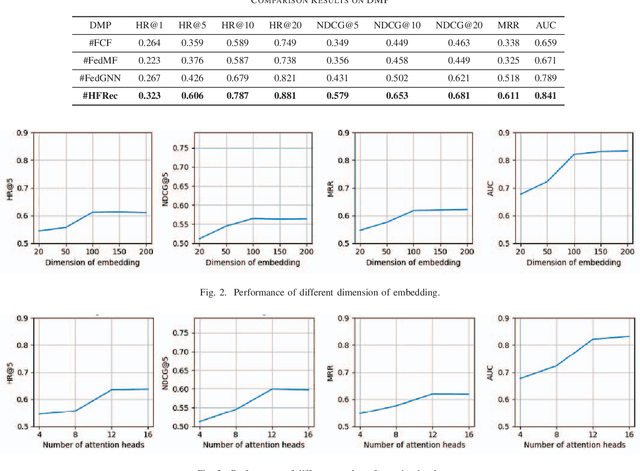
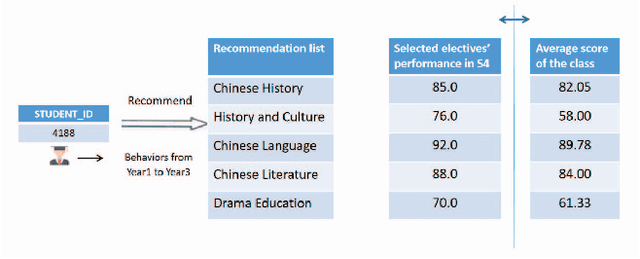
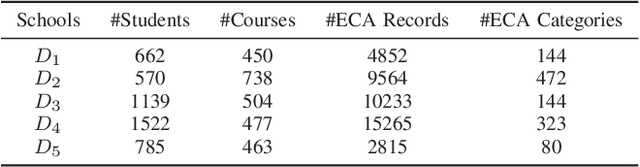
In the era of modern education, addressing cross-school learner diversity is crucial, especially in personalized recommender systems for elective course selection. However, privacy concerns often limit cross-school data sharing, which hinders existing methods' ability to model sparse data and address heterogeneity effectively, ultimately leading to suboptimal recommendations. In response, we propose HFRec, a heterogeneity-aware hybrid federated recommender system designed for cross-school elective course recommendations. The proposed model constructs heterogeneous graphs for each school, incorporating various interactions and historical behaviors between students to integrate context and content information. We design an attention mechanism to capture heterogeneity-aware representations. Moreover, under a federated scheme, we train individual school-based models with adaptive learning settings to recommend tailored electives. Our HFRec model demonstrates its effectiveness in providing personalized elective recommendations while maintaining privacy, as it outperforms state-of-the-art models on both open-source and real-world datasets.