 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration-free BEV Representation for Infrastructure Perception
Mar 07, 2023Effective BEV object detection on infrastructure can greatly improve traffic scenes understanding and vehicle-toinfrastructure (V2I) cooperative perception. However, cameras installed on infrastructure have various postures, and previous BEV detection methods rely on accurate calibration, which is difficult for practical applications due to inevitable natural factors (e.g., wind and snow). In this paper, we propose a Calibration-free BEV Representation (CBR) network, which achieves 3D detection based on BEV representation without calibration parameters and additional depth supervision. Specifically, we utilize two multi-layer perceptrons for decoupling the features from perspective view to front view and birdeye view under boxes-induced foreground supervision. Then, a cross-view feature fusion module matches features from orthogonal views according to similarity and conducts BEV feature enhancement with front view features. Experimental results on DAIR-V2X demonstrate that CBR achieves acceptable performance without any camera parameters and is naturally not affected by calibration noises. We hope CBR can serve as a baseline for future research addressing practical challenges of infrastructure perception.
Metropolis Theorem and Its Applications in Single Image Detail Enhancement
Feb 20, 2023



Traditional image detail enhancement is local filter-based or global filter-based. In both approaches, the original image is first divided into the base layer and the detail layer, and then the enhanced image is obtained by amplifying the detail layer. Our method is different, and its innovation lies in the special way to get the image detail layer. The detail layer in our method is obtained by updating the residual features, and the updating mechanism is usually based on searching and matching similar patches. However, due to the diversity of image texture features, perfect matching is often not possible. In this paper, the process of searching and matching is treated as a thermodynamic process, where the Metropolis theorem can minimize the internal energy and get the global optimal solution of this task, that is, to find a more suitable feature for a better detail enhancement performance. Extensive experiments have proven that our algorithm can achieve better results in quantitative metrics testing and visual effects evaluation. The source code can be obtained from the link.
Multimodal Federated Learning via Contrastive Representation Ensemble
Feb 17, 2023



With the increasing amount of multimedia data on modern mobile systems and IoT infrastructures, harnessing these rich multimodal data without breaching user privacy becomes a critical issue. Federated learning (FL) serves as a privacy-conscious alternative to centralized machine learning. However, existing FL methods extended to multimodal data all rely on model aggregation on single modality level, which restrains the server and clients to have identical model architecture for each modality. This limits the global model in terms of both model complexity and data capacity, not to mention task diversity. In this work, we propose Contrastive Representation Ensemble and Aggregation for Multimodal FL (CreamFL), a multimodal federated learning framework that enables training larger server models from clients with heterogeneous model architectures and data modalities, while only communicating knowledge on public dataset. To achieve better multimodal representation fusion, we design a global-local cross-modal ensemble strategy to aggregate client representations. To mitigate local model drift caused by two unprecedented heterogeneous factors stemming from multimodal discrepancy (modality gap and task gap), we further propose two inter-modal and intra-modal contrasts to regularize local training, which complements information of the absent modality for uni-modal clients and regularizes local clients to head towards global consensus. Thorough evaluations and ablation studies on image-text retrieval and visual question answering tasks showcase the superiority of CreamFL over state-of-the-art FL methods and its practical value.
Mind the Gap: Offline Policy Optimization for Imperfect Rewards
Feb 03, 2023



Reward function is essential in reinforcement learning (RL), serving as the guiding signal to incentivize agents to solve given tasks, however, is also notoriously difficult to design. In many cases, only imperfect rewards are available, which inflicts substantial performance loss for RL agents. In this study, we propose a unified offline policy optimization approach, \textit{RGM (Reward Gap Minimization)}, which can smartly handle diverse types of imperfect rewards. RGM is formulated as a bi-level optimization problem: the upper layer optimizes a reward correction term that performs visitation distribution matching w.r.t. some expert data; the lower layer solves a pessimistic RL problem with the corrected rewards. By exploiting the duality of the lower layer, we derive a tractable algorithm that enables sampled-based learning without any online interactions. Comprehensive experiments demonstrate that RGM achieves superior performance to existing methods under diverse settings of imperfect rewards. Further, RGM can effectively correct wrong or inconsistent rewards against expert preference and retrieve useful information from biased rewards.
ADAPT: Action-aware Driving Caption Transformer
Feb 01, 2023



End-to-end autonomous driving has great potential in the transportation industry. However, the lack of transparency and interpretability of the automatic decision-making process hinders its industrial adoption in practice. There have been some early attempts to use attention maps or cost volume for better model explainability which is difficult for ordinary passengers to understand. To bridge the gap, we propose an end-to-end transformer-based architecture, ADAPT (Action-aware Driving cAPtion Transformer), which provides user-friendly natural language narrations and reasoning for each decision making step of autonomous vehicular control and action. ADAPT jointly trains both the driving caption task and the vehicular control prediction task, through a shared video representation. Experiments on BDD-X (Berkeley DeepDrive eXplanation) dataset demonstrate state-of-the-art performance of the ADAPT framework on both automatic metrics and human evaluation. To illustrate the feasibility of the proposed framework in real-world applications, we build a novel deployable system that takes raw car videos as input and outputs the action narrations and reasoning in real time. The code, models and data are available at https://github.com/jxbbb/ADAPT.
Correcting the Sub-optimal Bit Allocation
Oct 10, 2022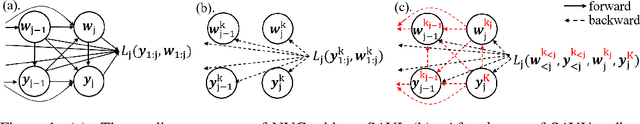
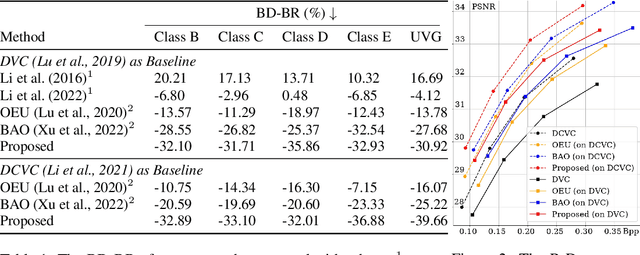
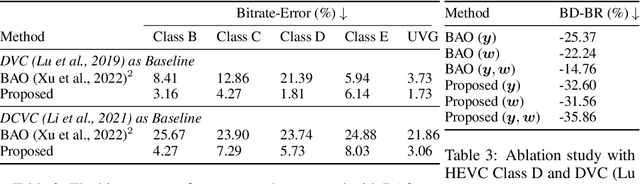
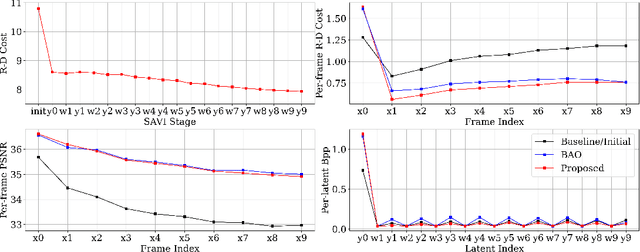
In this paper, we investigate the problem of bit allocation in Neural Video Compression (NVC). First, we reveal that a recent bit allocation approach claimed to be optimal is, in fact, sub-optimal due to its implementation. Specifically, we find that its sub-optimality lies in the improper application of semi-amortized variational inference (SAVI) on latent with non-factorized variational posterior. Then, we show that the corrected version of SAVI on non-factorized latent requires recursively applying back-propagating through gradient ascent, based on which we derive the corrected optimal bit allocation algorithm. Due to the computational in-feasibility of the corrected bit allocation, we design an efficient approximation to make it practical. Empirical results show that our proposed correction significantly improves the incorrect bit allocation in terms of R-D performance and bitrate error, and outperforms all other bit allocation methods by a large margin. The source code is provided in the supplementary material.
Adversarial Contrastive Learning via Asymmetric InfoNCE
Jul 18, 2022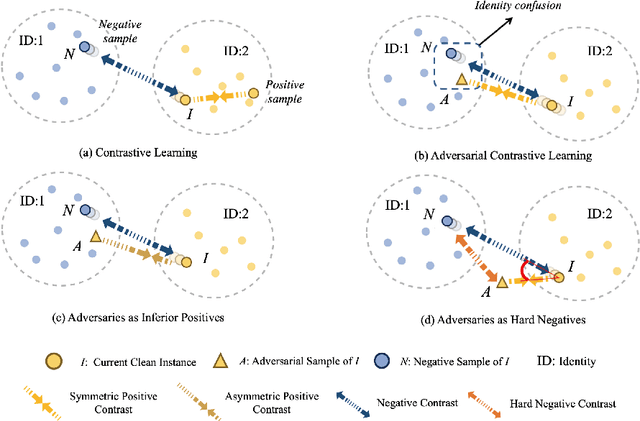
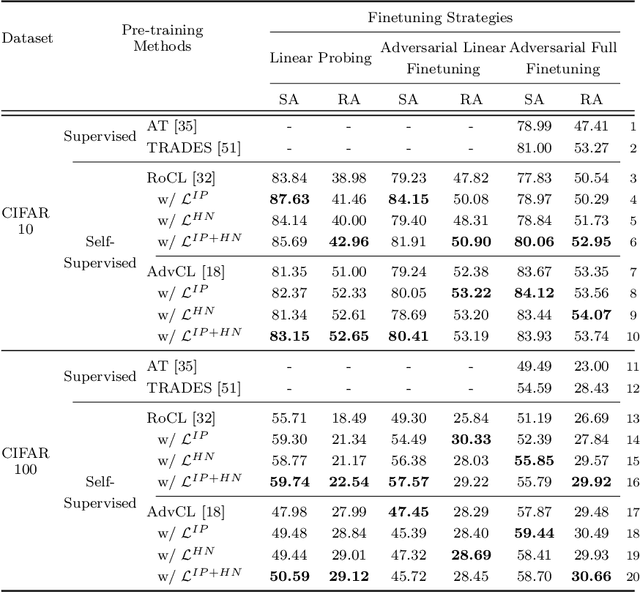
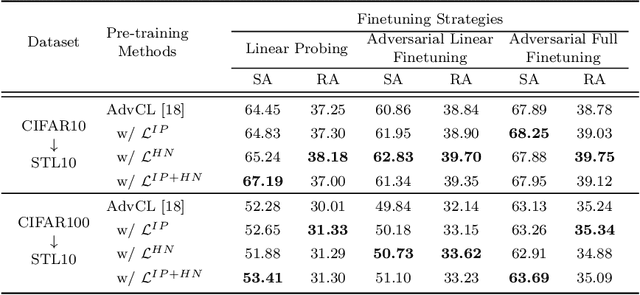
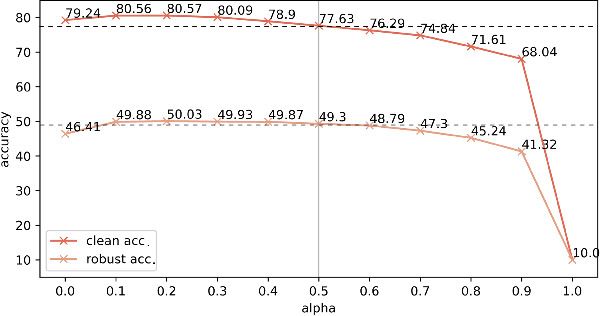
Contrastive learning (CL) has recently been applied to adversarial learning tasks. Such practice considers adversarial samples as additional positive views of an instance, and by maximizing their agreements with each other, yields better adversarial robustness. However, this mechanism can be potentially flawed, since adversarial perturbations may cause instance-level identity confusion, which can impede CL performance by pulling together different instances with separate identities. To address this issue, we propose to treat adversarial samples unequally when contrasted, with an asymmetric InfoNCE objective ($A-InfoNCE$) that allows discriminating considerations of adversarial samples. Specifically, adversaries are viewed as inferior positives that induce weaker learning signals, or as hard negatives exhibiting higher contrast to other negative samples. In the asymmetric fashion, the adverse impacts of conflicting objectives between CL and adversarial learning can be effectively mitigated. Experiments show that our approach consistently outperforms existing Adversarial CL methods across different finetuning schemes without additional computational cost. The proposed A-InfoNCE is also a generic form that can be readily extended to other CL methods. Code is available at https://github.com/yqy2001/A-InfoNCE.
Distance-Sensitive Offline Reinforcement Learning
May 23, 2022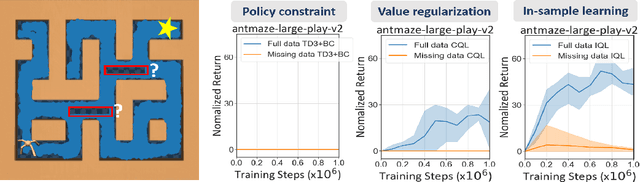
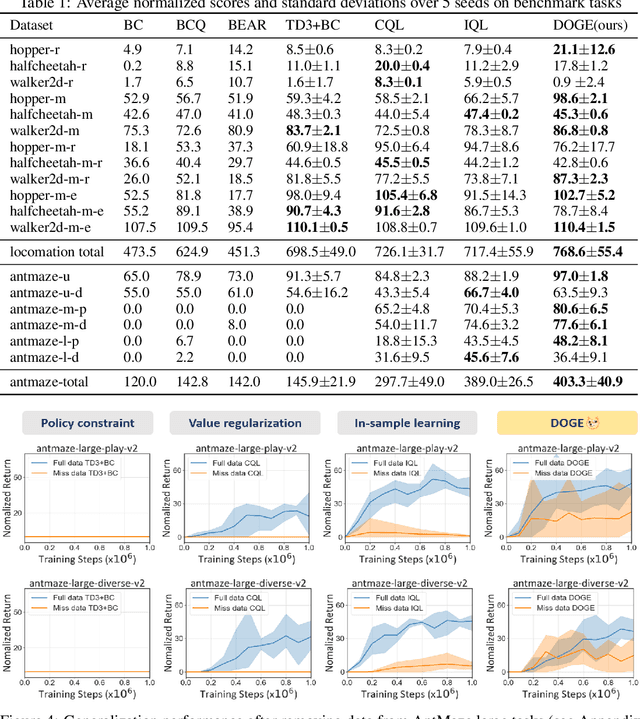

In offline reinforcement learning (RL), one detrimental issue to policy learning is the error accumulation of deep Q function in out-of-distribution (OOD) areas. Unfortunately, existing offline RL methods are often over-conservative, inevitably hurting generalization performance outside data distribution. In our study, one interesting observation is that deep Q functions approximate well inside the convex hull of training data. Inspired by this, we propose a new method, DOGE (Distance-sensitive Offline RL with better GEneralization). DOGE marries dataset geometry with deep function approximators in offline RL, and enables exploitation in generalizable OOD areas rather than strictly constraining policy within data distribution. Specifically, DOGE trains a state-conditioned distance function that can be readily plugged into standard actor-critic methods as a policy constraint. Simple yet elegant, our algorithm enjoys better generalization compared to state-of-the-art methods on D4RL benchmarks. Theoretical analysis demonstrates the superiority of our approach to existing methods that are solely based on data distribution or support constraints.
TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation
Aug 12, 2021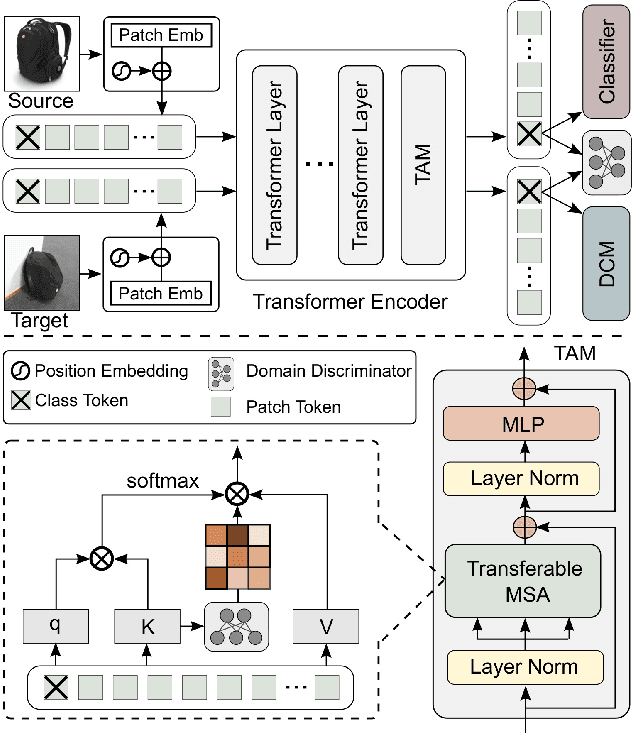
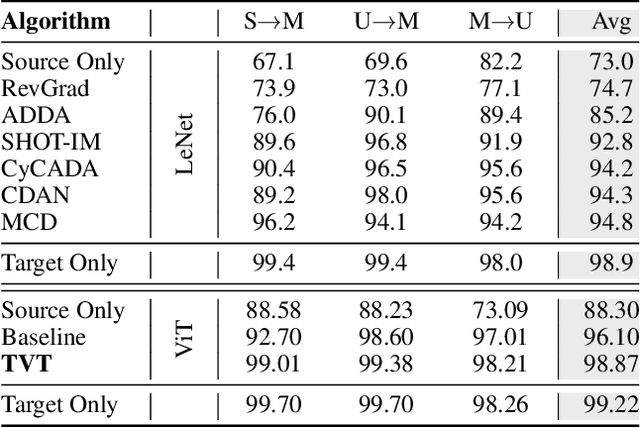
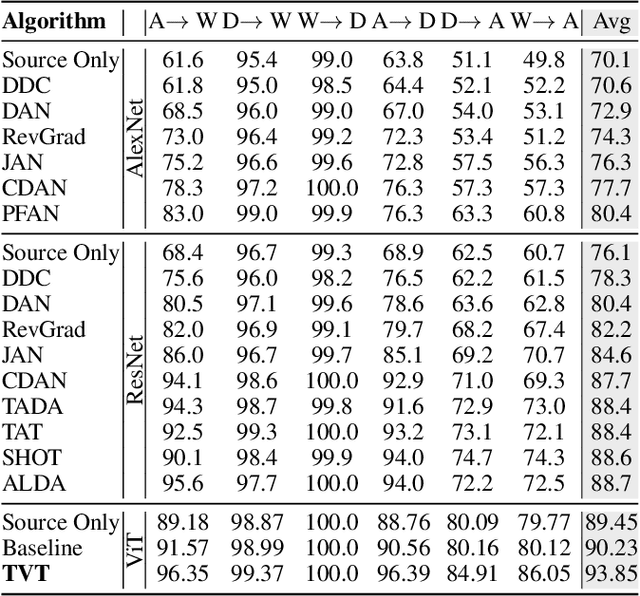

Unsupervised domain adaptation (UDA) aims to transfer the knowledge learnt from a labeled source domain to an unlabeled target domain. Previous work is mainly built upon convolutional neural networks (CNNs) to learn domain-invariant representations. With the recent exponential increase in applying Vision Transformer (ViT) to vision tasks, the capability of ViT in adapting cross-domain knowledge, however, remains unexplored in the literature. To fill this gap, this paper first comprehensively investigates the transferability of ViT on a variety of domain adaptation tasks. Surprisingly, ViT demonstrates superior transferability over its CNNs-based counterparts with a large margin, while the performance can be further improved by incorporating adversarial adaptation. Notwithstanding, directly using CNNs-based adaptation strategies fails to take the advantage of ViT's intrinsic merits (e.g., attention mechanism and sequential image representation) which play an important role in knowledge transfer. To remedy this, we propose an unified framework, namely Transferable Vision Transformer (TVT), to fully exploit the transferability of ViT for domain adaptation. Specifically, we delicately devise a novel and effective unit, which we term Transferability Adaption Module (TAM). By injecting learned transferabilities into attention blocks, TAM compels ViT focus on both transferable and discriminative features. Besides, we leverage discriminative clustering to enhance feature diversity and separation which are undermined during adversarial domain alignment. To verify its versatility, we perform extensive studies of TVT on four benchmarks and the experimental results demonstrate that TVT attains significant improvements compared to existing state-of-the-art UDA methods.
VALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation
Jun 08, 2021

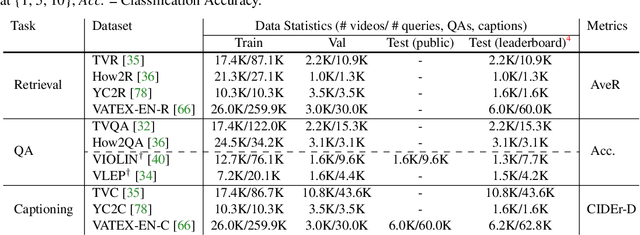
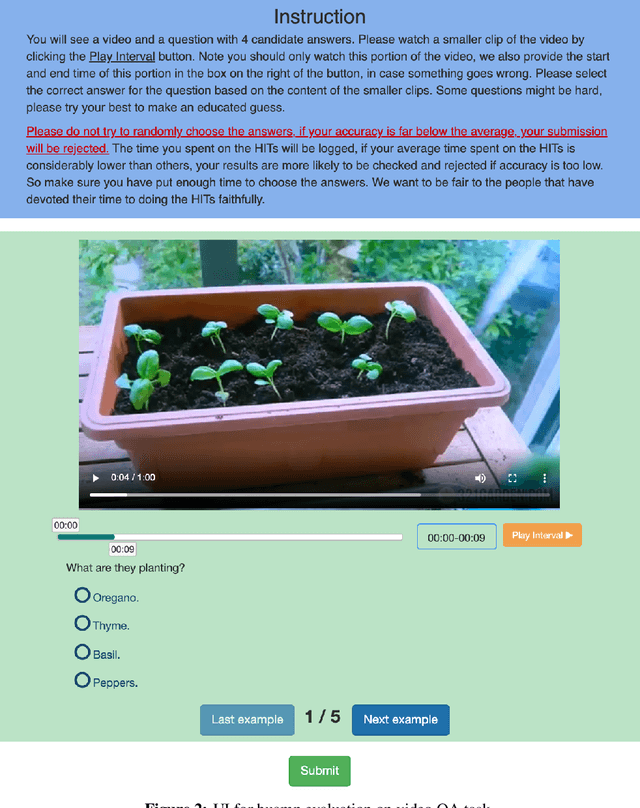
Most existing video-and-language (VidL) research focuses on a single dataset, or multiple datasets of a single task. In reality, a truly useful VidL system is expected to be easily generalizable to diverse tasks, domains, and datasets. To facilitate the evaluation of such systems, we introduce Video-And-Language Understanding Evaluation (VALUE) benchmark, an assemblage of 11 VidL datasets over 3 popular tasks: (i) text-to-video retrieval; (ii) video question answering; and (iii) video captioning. VALUE benchmark aims to cover a broad range of video genres, video lengths, data volumes, and task difficulty levels. Rather than focusing on single-channel videos with visual information only, VALUE promotes models that leverage information from both video frames and their associated subtitles, as well as models that share knowledge across multiple tasks. We evaluate various baseline methods with and without large-scale VidL pre-training, and systematically investigate the impact of video input channels, fusion methods, and different video representations. We also study the transferability between tasks, and conduct multi-task learning under different settings. The significant gap between our best model and human performance calls for future study for advanced VidL models. VALUE is available at https://value-leaderboard.github.io/.