 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation
Feb 27, 2026GPU kernel optimization is fundamental to modern deep learning but remains a highly specialized task requiring deep hardware expertise. Despite strong performance in general programming, large language models (LLMs) remain uncompetitive with compiler-based systems such as torch.compile for CUDA kernel generation. Existing CUDA code generation approaches either rely on training-free refinement or fine-tune models within fixed multi-turn execution-feedback loops, but both paradigms fail to fundamentally improve the model's intrinsic CUDA optimization ability, resulting in limited performance gains. We present CUDA Agent, a large-scale agentic reinforcement learning system that develops CUDA kernel expertise through three components: a scalable data synthesis pipeline, a skill-augmented CUDA development environment with automated verification and profiling to provide reliable reward signals, and reinforcement learning algorithmic techniques enabling stable training. CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100\%, 100\%, and 92\% faster rate over torch.compile on KernelBench Level-1, Level-2, and Level-3 splits, outperforming the strongest proprietary models such as Claude Opus 4.5 and Gemini 3 Pro by about 40\% on the hardest Level-3 setting.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
ShortListing Model: A Streamlined SimplexDiffusion for Discrete Variable Generation
Aug 24, 2025Generative modeling of discrete variables is challenging yet crucial for applications in natural language processing and biological sequence design. We introduce the Shortlisting Model (SLM), a novel simplex-based diffusion model inspired by progressive candidate pruning. SLM operates on simplex centroids, reducing generation complexity and enhancing scalability. Additionally, SLM incorporates a flexible implementation of classifier-free guidance, enhancing unconditional generation performance. Extensive experiments on DNA promoter and enhancer design, protein design, character-level and large-vocabulary language modeling demonstrate the competitive performance and strong potential of SLM. Our code can be found at https://github.com/GenSI-THUAIR/SLM
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Jul 03, 2025



Despite improvements by length extrapolation, efficient attention and memory modules, handling infinitely long documents with linear complexity without performance degradation during extrapolation remains the ultimate challenge in long-text processing. We directly optimize for long-text tasks in an end-to-end fashion and introduce a novel agent workflow, MemAgent, which reads text in segments and updates the memory using an overwrite strategy. We extend the DAPO algorithm to facilitate training via independent-context multi-conversation generation. MemAgent has demonstrated superb long-context capabilities, being able to extrapolate from an 8K context trained on 32K text to a 3.5M QA task with performance loss < 5% and achieves 95%+ in 512K RULER test.
Truncated Proximal Policy Optimization
Jun 18, 2025



Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
Enigmata: Scaling Logical Reasoning in Large Language Models with Synthetic Verifiable Puzzles
May 26, 2025



Large Language Models (LLMs), such as OpenAI's o1 and DeepSeek's R1, excel at advanced reasoning tasks like math and coding via Reinforcement Learning with Verifiable Rewards (RLVR), but still struggle with puzzles solvable by humans without domain knowledge. We introduce Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills. It includes 36 tasks across seven categories, each with 1) a generator that produces unlimited examples with controllable difficulty and 2) a rule-based verifier for automatic evaluation. This generator-verifier design supports scalable, multi-task RL training, fine-grained analysis, and seamless RLVR integration. We further propose Enigmata-Eval, a rigorous benchmark, and develop optimized multi-task RLVR strategies. Our trained model, Qwen2.5-32B-Enigmata, consistently surpasses o3-mini-high and o1 on the puzzle reasoning benchmarks like Enigmata-Eval, ARC-AGI (32.8%), and ARC-AGI 2 (0.6%). It also generalizes well to out-of-domain puzzle benchmarks and mathematical reasoning, with little multi-tasking trade-off. When trained on larger models like Seed1.5-Thinking (20B activated parameters and 200B total parameters), puzzle data from Enigmata further boosts SoTA performance on advanced math and STEM reasoning tasks such as AIME (2024-2025), BeyondAIME and GPQA (Diamond), showing nice generalization benefits of Enigmata. This work offers a unified, controllable framework for advancing logical reasoning in LLMs. Resources of this work can be found at https://seed-enigmata.github.io.
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Apr 08, 2025


We present VAPO, Value-based Augmented Proximal Policy Optimization framework for reasoning models., a novel framework tailored for reasoning models within the value-based paradigm. Benchmarked the AIME 2024 dataset, VAPO, built on the Qwen 32B pre-trained model, attains a state-of-the-art score of $\mathbf{60.4}$. In direct comparison under identical experimental settings, VAPO outperforms the previously reported results of DeepSeek-R1-Zero-Qwen-32B and DAPO by more than 10 points. The training process of VAPO stands out for its stability and efficiency. It reaches state-of-the-art performance within a mere 5,000 steps. Moreover, across multiple independent runs, no training crashes occur, underscoring its reliability. This research delves into long chain-of-thought (long-CoT) reasoning using a value-based reinforcement learning framework. We pinpoint three key challenges that plague value-based methods: value model bias, the presence of heterogeneous sequence lengths, and the sparsity of reward signals. Through systematic design, VAPO offers an integrated solution that effectively alleviates these challenges, enabling enhanced performance in long-CoT reasoning tasks.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025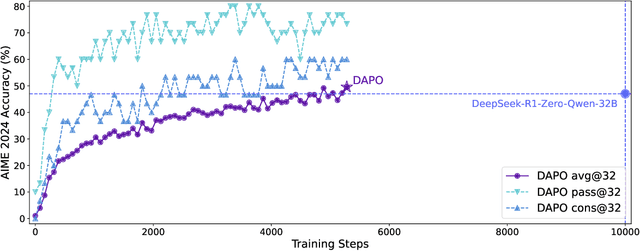

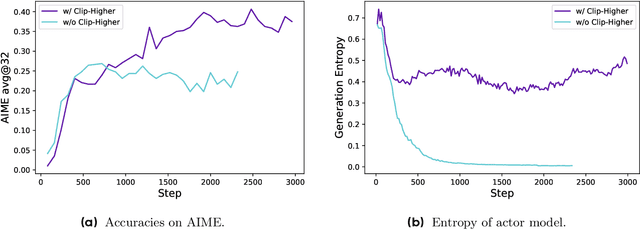

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
Emu3: Next-Token Prediction is All You Need
Sep 27, 2024



While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.
EVA-CLIP-18B: Scaling CLIP to 18 Billion Parameters
Feb 06, 2024



Scaling up contrastive language-image pretraining (CLIP) is critical for empowering both vision and multimodal models. We present EVA-CLIP-18B, the largest and most powerful open-source CLIP model to date, with 18-billion parameters. With only 6-billion training samples seen, EVA-CLIP-18B achieves an exceptional 80.7% zero-shot top-1 accuracy averaged across 27 widely recognized image classification benchmarks, outperforming its forerunner EVA-CLIP (5-billion parameters) and other open-source CLIP models by a large margin. Remarkably, we observe a consistent performance improvement with the model size scaling of EVA-CLIP, despite maintaining a constant training dataset of 2-billion image-text pairs from LAION-2B and COYO-700M. This dataset is openly available and much smaller than the in-house datasets (e.g., DFN-5B, WebLI-10B) employed in other state-of-the-art CLIP models. EVA-CLIP-18B demonstrates the potential of EVA-style weak-to-strong visual model scaling. With our model weights made publicly available, we hope to facilitate future research in vision and multimodal foundation models.