 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
Oct 10, 2024



Recent advances in latent diffusion-based generative models for portrait image animation, such as Hallo, have achieved impressive results in short-duration video synthesis. In this paper, we present updates to Hallo, introducing several design enhancements to extend its capabilities. First, we extend the method to produce long-duration videos. To address substantial challenges such as appearance drift and temporal artifacts, we investigate augmentation strategies within the image space of conditional motion frames. Specifically, we introduce a patch-drop technique augmented with Gaussian noise to enhance visual consistency and temporal coherence over long duration. Second, we achieve 4K resolution portrait video generation. To accomplish this, we implement vector quantization of latent codes and apply temporal alignment techniques to maintain coherence across the temporal dimension. By integrating a high-quality decoder, we realize visual synthesis at 4K resolution. Third, we incorporate adjustable semantic textual labels for portrait expressions as conditional inputs. This extends beyond traditional audio cues to improve controllability and increase the diversity of the generated content. To the best of our knowledge, Hallo2, proposed in this paper, is the first method to achieve 4K resolution and generate hour-long, audio-driven portrait image animations enhanced with textual prompts. We have conducted extensive experiments to evaluate our method on publicly available datasets, including HDTF, CelebV, and our introduced "Wild" dataset. The experimental results demonstrate that our approach achieves state-of-the-art performance in long-duration portrait video animation, successfully generating rich and controllable content at 4K resolution for duration extending up to tens of minutes. Project page https://fudan-generative-vision.github.io/hallo2
MGMapNet: Multi-Granularity Representation Learning for End-to-End Vectorized HD Map Construction
Oct 10, 2024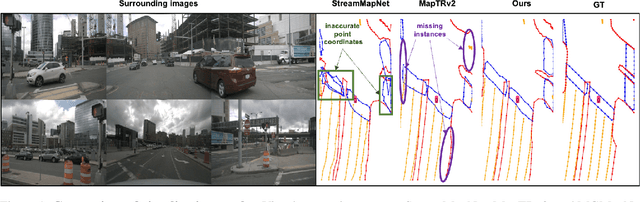
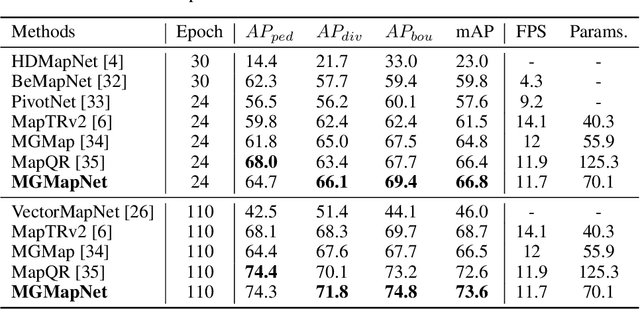
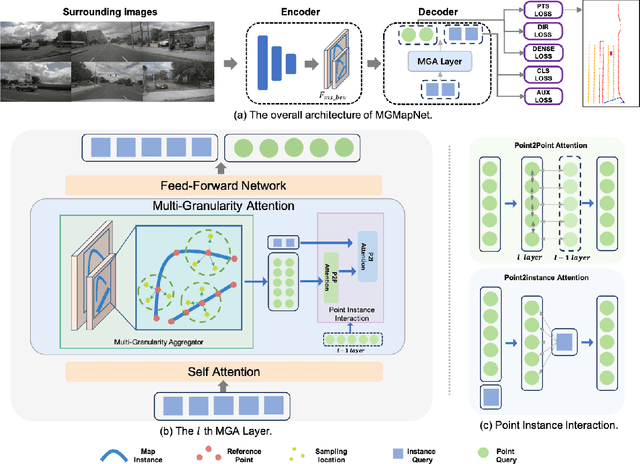

The construction of Vectorized High-Definition (HD) map typically requires capturing both category and geometry information of map elements. Current state-of-the-art methods often adopt solely either point-level or instance-level representation, overlooking the strong intrinsic relationships between points and instances. In this work, we propose a simple yet efficient framework named MGMapNet (Multi-Granularity Map Network) to model map element with a multi-granularity representation, integrating both coarse-grained instance-level and fine-grained point-level queries. Specifically, these two granularities of queries are generated from the multi-scale bird's eye view (BEV) features using a proposed Multi-Granularity Aggregator. In this module, instance-level query aggregates features over the entire scope covered by an instance, and the point-level query aggregates features locally. Furthermore, a Point Instance Interaction module is designed to encourage information exchange between instance-level and point-level queries. Experimental results demonstrate that the proposed MGMapNet achieves state-of-the-art performance, surpassing MapTRv2 by 5.3 mAP on nuScenes and 4.4 mAP on Argoverse2 respectively.
Flipped Classroom: Aligning Teacher Attention with Student in Generalized Category Discovery
Sep 29, 2024



Recent advancements have shown promise in applying traditional Semi-Supervised Learning strategies to the task of Generalized Category Discovery (GCD). Typically, this involves a teacher-student framework in which the teacher imparts knowledge to the student to classify categories, even in the absence of explicit labels. Nevertheless, GCD presents unique challenges, particularly the absence of priors for new classes, which can lead to the teacher's misguidance and unsynchronized learning with the student, culminating in suboptimal outcomes. In our work, we delve into why traditional teacher-student designs falter in open-world generalized category discovery as compared to their success in closed-world semi-supervised learning. We identify inconsistent pattern learning across attention layers as the crux of this issue and introduce FlipClass, a method that dynamically updates the teacher to align with the student's attention, instead of maintaining a static teacher reference. Our teacher-student attention alignment strategy refines the teacher's focus based on student feedback from an energy perspective, promoting consistent pattern recognition and synchronized learning across old and new classes. Extensive experiments on a spectrum of benchmarks affirm that FlipClass significantly surpasses contemporary GCD methods, establishing new standards for the field.
MonoFormer: One Transformer for Both Diffusion and Autoregression
Sep 24, 2024



Most existing multimodality methods use separate backbones for autoregression-based discrete text generation and diffusion-based continuous visual generation, or the same backbone by discretizing the visual data to use autoregression for both text and visual generation. In this paper, we propose to study a simple idea: share one transformer for both autoregression and diffusion. The feasibility comes from two main aspects: (i) Transformer is successfully applied to diffusion for visual generation, and (ii) transformer training for autoregression and diffusion is very similar, and the difference merely lies in that diffusion uses bidirectional attention mask and autoregression uses causal attention mask. Experimental results show that our approach achieves comparable image generation performance to current state-of-the-art methods as well as maintains the text generation capability. The project is publicly available at https://monoformer.github.io/.
SpotActor: Training-Free Layout-Controlled Consistent Image Generation
Sep 07, 2024



Text-to-image diffusion models significantly enhance the efficiency of artistic creation with high-fidelity image generation. However, in typical application scenarios like comic book production, they can neither place each subject into its expected spot nor maintain the consistent appearance of each subject across images. For these issues, we pioneer a novel task, Layout-to-Consistent-Image (L2CI) generation, which produces consistent and compositional images in accordance with the given layout conditions and text prompts. To accomplish this challenging task, we present a new formalization of dual energy guidance with optimization in a dual semantic-latent space and thus propose a training-free pipeline, SpotActor, which features a layout-conditioned backward update stage and a consistent forward sampling stage. In the backward stage, we innovate a nuanced layout energy function to mimic the attention activations with a sigmoid-like objective. While in the forward stage, we design Regional Interconnection Self-Attention (RISA) and Semantic Fusion Cross-Attention (SFCA) mechanisms that allow mutual interactions across images. To evaluate the performance, we present ActorBench, a specified benchmark with hundreds of reasonable prompt-box pairs stemming from object detection datasets. Comprehensive experiments are conducted to demonstrate the effectiveness of our method. The results prove that SpotActor fulfills the expectations of this task and showcases the potential for practical applications with superior layout alignment, subject consistency, prompt conformity and background diversity.
Make Your ViT-based Multi-view 3D Detectors Faster via Token Compression
Sep 01, 2024



Slow inference speed is one of the most crucial concerns for deploying multi-view 3D detectors to tasks with high real-time requirements like autonomous driving. Although many sparse query-based methods have already attempted to improve the efficiency of 3D detectors, they neglect to consider the backbone, especially when using Vision Transformers (ViT) for better performance. To tackle this problem, we explore the efficient ViT backbones for multi-view 3D detection via token compression and propose a simple yet effective method called TokenCompression3D (ToC3D). By leveraging history object queries as foreground priors of high quality, modeling 3D motion information in them, and interacting them with image tokens through the attention mechanism, ToC3D can effectively determine the magnitude of information densities of image tokens and segment the salient foreground tokens. With the introduced dynamic router design, ToC3D can weigh more computing resources to important foreground tokens while compressing the information loss, leading to a more efficient ViT-based multi-view 3D detector. Extensive results on the large-scale nuScenes dataset show that our method can nearly maintain the performance of recent SOTA with up to 30% inference speedup, and the improvements are consistent after scaling up the ViT and input resolution. The code will be made at https://github.com/DYZhang09/ToC3D.
EasyChauffeur: A Baseline Advancing Simplicity and Efficiency on Waymax
Aug 29, 2024



Recent advancements in deep-learning-based driving planners have primarily focused on elaborate network engineering, yielding limited improvements. This paper diverges from conventional approaches by exploring three fundamental yet underinvestigated aspects: training policy, data efficiency, and evaluation robustness. We introduce EasyChauffeur, a reproducible and effective planner for both imitation learning (IL) and reinforcement learning (RL) on Waymax, a GPU-accelerated simulator. Notably, our findings indicate that the incorporation of on-policy RL significantly boosts performance and data efficiency. To further enhance this efficiency, we propose SNE-Sampling, a novel method that selectively samples data from the encoder's latent space, substantially improving EasyChauffeur's performance with RL. Additionally, we identify a deficiency in current evaluation methods, which fail to accurately assess the robustness of different planners due to significant performance drops from minor changes in the ego vehicle's initial state. In response, we propose Ego-Shifting, a new evaluation setting for assessing planners' robustness. Our findings advocate for a shift from a primary focus on network architectures to adopting a holistic approach encompassing training strategies, data efficiency, and robust evaluation methods.
Disentangled Noisy Correspondence Learning
Aug 10, 2024



Cross-modal retrieval is crucial in understanding latent correspondences across modalities. However, existing methods implicitly assume well-matched training data, which is impractical as real-world data inevitably involves imperfect alignments, i.e., noisy correspondences. Although some works explore similarity-based strategies to address such noise, they suffer from sub-optimal similarity predictions influenced by modality-exclusive information (MEI), e.g., background noise in images and abstract definitions in texts. This issue arises as MEI is not shared across modalities, thus aligning it in training can markedly mislead similarity predictions. Moreover, although intuitive, directly applying previous cross-modal disentanglement methods suffers from limited noise tolerance and disentanglement efficacy. Inspired by the robustness of information bottlenecks against noise, we introduce DisNCL, a novel information-theoretic framework for feature Disentanglement in Noisy Correspondence Learning, to adaptively balance the extraction of MII and MEI with certifiable optimal cross-modal disentanglement efficacy. DisNCL then enhances similarity predictions in modality-invariant subspace, thereby greatly boosting similarity-based alleviation strategy for noisy correspondences. Furthermore, DisNCL introduces soft matching targets to model noisy many-to-many relationships inherent in multi-modal input for noise-robust and accurate cross-modal alignment. Extensive experiments confirm DisNCL's efficacy by 2% average recall improvement. Mutual information estimation and visualization results show that DisNCL learns meaningful MII/MEI subspaces, validating our theoretical analyses.
ReSyncer: Rewiring Style-based Generator for Unified Audio-Visually Synced Facial Performer
Aug 06, 2024



Lip-syncing videos with given audio is the foundation for various applications including the creation of virtual presenters or performers. While recent studies explore high-fidelity lip-sync with different techniques, their task-orientated models either require long-term videos for clip-specific training or retain visible artifacts. In this paper, we propose a unified and effective framework ReSyncer, that synchronizes generalized audio-visual facial information. The key design is revisiting and rewiring the Style-based generator to efficiently adopt 3D facial dynamics predicted by a principled style-injected Transformer. By simply re-configuring the information insertion mechanisms within the noise and style space, our framework fuses motion and appearance with unified training. Extensive experiments demonstrate that ReSyncer not only produces high-fidelity lip-synced videos according to audio, but also supports multiple appealing properties that are suitable for creating virtual presenters and performers, including fast personalized fine-tuning, video-driven lip-syncing, the transfer of speaking styles, and even face swapping. Resources can be found at https://guanjz20.github.io/projects/ReSyncer.
Add-SD: Rational Generation without Manual Reference
Jul 30, 2024



Diffusion models have exhibited remarkable prowess in visual generalization. Building on this success, we introduce an instruction-based object addition pipeline, named Add-SD, which automatically inserts objects into realistic scenes with rational sizes and positions. Different from layout-conditioned methods, Add-SD is solely conditioned on simple text prompts rather than any other human-costly references like bounding boxes. Our work contributes in three aspects: proposing a dataset containing numerous instructed image pairs; fine-tuning a diffusion model for rational generation; and generating synthetic data to boost downstream tasks. The first aspect involves creating a RemovalDataset consisting of original-edited image pairs with textual instructions, where an object has been removed from the original image while maintaining strong pixel consistency in the background. These data pairs are then used for fine-tuning the Stable Diffusion (SD) model. Subsequently, the pretrained Add-SD model allows for the insertion of expected objects into an image with good rationale. Additionally, we generate synthetic instances for downstream task datasets at scale, particularly for tail classes, to alleviate the long-tailed problem. Downstream tasks benefit from the enriched dataset with enhanced diversity and rationale. Experiments on LVIS val demonstrate that Add-SD yields an improvement of 4.3 mAP on rare classes over the baseline. Code and models are available at https://github.com/ylingfeng/Add-SD.