 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
May 20, 2026Multimodal large language models (MLLMs) have shown remarkable capability in bridging visual perception and textual reasoning, enabling zero-shot understanding across diverse industrial scenarios. However, their performance in open-vocabulary industrial anomaly detection (IAD) is often limited by domain-misaligned reasoning and hallucinated structural inferences. To address these challenges, we propose \textbf{IndusAgent}, a tool-augmented agentic framework for open-vocabulary IAD. Specifically, we first construct \textbf{Indus-CoT}, a structured dataset that integrates global visual observations, high-resolution local patches, and expert normalcy priors, providing supervision for fine-tuning the model on rigorous industrial inspection trajectories. Building on this, IndusAgent dynamically orchestrates a set of external tools, including dynamic region cropping, high-frequency feature enhancement, and prior retrieval, thus enabling the agent to actively resolve visual ambiguities and disentangle subtle anomalies. Furthermore, we introduce a gated reinforcement learning objective that jointly optimizes anomaly classification, localization accuracy, anomaly type reasoning, and efficient tool usage, ensuring that tool invocation occurs only when beneficial. Extensive evaluations on five industrial anomaly benchmarks, including MVTec-AD, VisA, MPDD, DTD, and SDD, demonstrate that IndusAgent achieves state-of-the-art zero-shot performance among all existing methods, validating our robustness and generalization capacity.
Exploring Time Conditioning in Diffusion Generative Models from Disjoint Noisy Data Manifolds
Apr 28, 2026Practically, training diffusion models typically requires explicit time conditioning to guide the network through the denoising sampling process. Especially in deterministic methods like DDIM, the absence of time conditioning leads to significant performance degradation. However, other deterministic sampling approaches, such as flow matching, can generate high-quality content without this conditioning, raising the question of its necessity. In this work, we revisit the role of time conditioning from a geometric perspective. We analyze the evolution of noisy data distributions under the forward diffusion process and demonstrate that, in high-dimensional spaces, these distributions concentrate on low-dimensional hyper-cylinder-like manifolds embedded within the input space. Successful generation, we argue, stems from the disentanglement of these manifolds in high-dimensional space. Based on this insight, we modify the forward process of DDIM to align the noisy data manifold with the flow-matching approach, proving that DDIM can generate high-quality content without time conditioning, provided the noisy manifold evolves according to the flow-matching method. Additionally, we extend our framework to class-conditioned generation by decoupling classes into distinct time spaces, enabling class-conditioned synthesis with a class-unconditional denoising model. Extensive experiments validate our theoretical analysis and show that high-quality generation is achievable without explicit conditional embeddings.
Unlocking the Potential of Grounding DINO in Videos: Parameter-Efficient Adaptation for Limited-Data Spatial-Temporal Localization
Apr 14, 2026Spatio-temporal video grounding (STVG) aims to localize queried objects within dynamic video segments. Prevailing fully-trained approaches are notoriously data-hungry. However, gathering large-scale STVG data is exceptionally challenging: dense frame-level bounding boxes and complex temporal language alignments are prohibitively expensive to annotate, especially for specialized video domains. Consequently, conventional models suffer from severe overfitting on these inherently limited datasets, while zero-shot foundational models lack the task-specific temporal awareness needed for precise localization. To resolve this small-data challenge, we introduce ST-GD, a data-efficient framework that adapts pre-trained 2D visual-language models (e.g., Grounding DINO) to video tasks. To avoid destroying pre-trained priors on small datasets, ST-GD keeps the base model frozen and strategically injects lightweight adapters (~10M trainable parameters) to instill spatio-temporal awareness, alongside a novel temporal decoder for boundary prediction. This design naturally counters data scarcity. Consequently, ST-GD excels in data-scarce scenarios, achieving highly competitive performance on the limited-scale HC-STVG v1/v2 benchmarks, while maintaining robust generalization on the VidSTG dataset. This validates ST-GD as a powerful paradigm for complex video understanding under strict small-data constraints.
Knowledge is Power: Advancing Few-shot Action Recognition with Multimodal Semantics from MLLMs
Mar 27, 2026Multimodal Large Language Models (MLLMs) have propelled the field of few-shot action recognition (FSAR). However, preliminary explorations in this area primarily focus on generating captions to form a suboptimal feature->caption->feature pipeline and adopt metric learning solely within the visual space. In this paper, we propose FSAR-LLaVA, the first end-to-end method to leverage MLLMs (such as Video-LLaVA) as a multimodal knowledge base for directly enhancing FSAR. First, at the feature level, we leverage the MLLM's multimodal decoder to extract spatiotemporally and semantically enriched representations, which are then decoupled and enhanced by our Multimodal Feature-Enhanced Module into distinct visual and textual features that fully exploit their semantic knowledge for FSAR. Next, we leverage the versatility of MLLMs to craft input prompts that flexibly adapt to diverse scenarios, and use their aligned outputs to drive our designed Composite Task-Oriented Prototype Construction, effectively bridging the distribution gap between meta-train and meta-test sets. Finally, to enable multimodal features to guide metric learning jointly, we introduce a training-free Multimodal Prototype Matching Metric that adaptively selects the most decisive cues and efficiently leverages the decoupled feature representations produced by MLLMs. Extensive experiments demonstrate superior performance across various tasks with minimal trainable parameters.
VAE-REPA: Variational Autoencoder Representation Alignment for Efficient Diffusion Training
Jan 25, 2026Denoising-based diffusion transformers, despite their strong generation performance, suffer from inefficient training convergence. Existing methods addressing this issue, such as REPA (relying on external representation encoders) or SRA (requiring dual-model setups), inevitably incur heavy computational overhead during training due to external dependencies. To tackle these challenges, this paper proposes \textbf{\namex}, a lightweight intrinsic guidance framework for efficient diffusion training. \name leverages off-the-shelf pre-trained Variational Autoencoder (VAE) features: their reconstruction property ensures inherent encoding of visual priors like rich texture details, structural patterns, and basic semantic information. Specifically, \name aligns the intermediate latent features of diffusion transformers with VAE features via a lightweight projection layer, supervised by a feature alignment loss. This design accelerates training without extra representation encoders or dual-model maintenance, resulting in a simple yet effective pipeline. Extensive experiments demonstrate that \name improves both generation quality and training convergence speed compared to vanilla diffusion transformers, matches or outperforms state-of-the-art acceleration methods, and incurs merely 4\% extra GFLOPs with zero additional cost for external guidance models.
BEDA: Belief Estimation as Probabilistic Constraints for Performing Strategic Dialogue Acts
Dec 31, 2025Strategic dialogue requires agents to execute distinct dialogue acts, for which belief estimation is essential. While prior work often estimates beliefs accurately, it lacks a principled mechanism to use those beliefs during generation. We bridge this gap by first formalizing two core acts Adversarial and Alignment, and by operationalizing them via probabilistic constraints on what an agent may generate. We instantiate this idea in BEDA, a framework that consists of the world set, the belief estimator for belief estimation, and the conditional generator that selects acts and realizes utterances consistent with the inferred beliefs. Across three settings, Conditional Keeper Burglar (CKBG, adversarial), Mutual Friends (MF, cooperative), and CaSiNo (negotiation), BEDA consistently outperforms strong baselines: on CKBG it improves success rate by at least 5.0 points across backbones and by 20.6 points with GPT-4.1-nano; on Mutual Friends it achieves an average improvement of 9.3 points; and on CaSiNo it achieves the optimal deal relative to all baselines. These results indicate that casting belief estimation as constraints provides a simple, general mechanism for reliable strategic dialogue.
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.
Improving Region Representation Learning from Urban Imagery with Noisy Long-Caption Supervision
Nov 10, 2025Region representation learning plays a pivotal role in urban computing by extracting meaningful features from unlabeled urban data. Analogous to how perceived facial age reflects an individual's health, the visual appearance of a city serves as its ``portrait", encapsulating latent socio-economic and environmental characteristics. Recent studies have explored leveraging Large Language Models (LLMs) to incorporate textual knowledge into imagery-based urban region representation learning. However, two major challenges remain: i)~difficulty in aligning fine-grained visual features with long captions, and ii) suboptimal knowledge incorporation due to noise in LLM-generated captions. To address these issues, we propose a novel pre-training framework called UrbanLN that improves Urban region representation learning through Long-text awareness and Noise suppression. Specifically, we introduce an information-preserved stretching interpolation strategy that aligns long captions with fine-grained visual semantics in complex urban scenes. To effectively mine knowledge from LLM-generated captions and filter out noise, we propose a dual-level optimization strategy. At the data level, a multi-model collaboration pipeline automatically generates diverse and reliable captions without human intervention. At the model level, we employ a momentum-based self-distillation mechanism to generate stable pseudo-targets, facilitating robust cross-modal learning under noisy conditions. Extensive experiments across four real-world cities and various downstream tasks demonstrate the superior performance of our UrbanLN.
Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
Jul 23, 2025
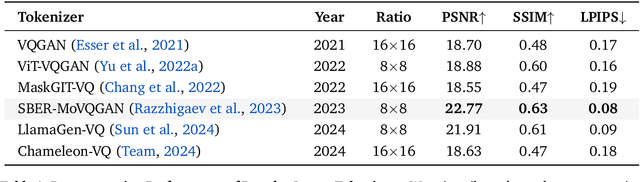
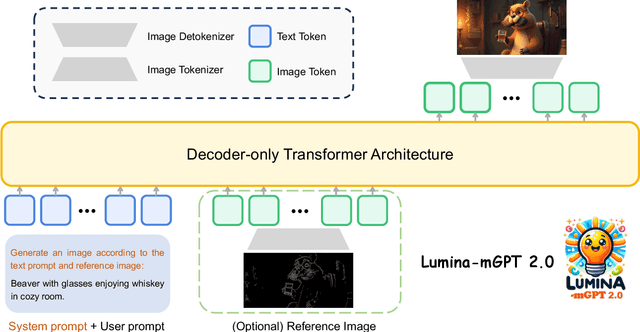

We present Lumina-mGPT 2.0, a stand-alone, decoder-only autoregressive model that revisits and revitalizes the autoregressive paradigm for high-quality image generation and beyond. Unlike existing approaches that rely on pretrained components or hybrid architectures, Lumina-mGPT 2.0 is trained entirely from scratch, enabling unrestricted architectural design and licensing freedom. It achieves generation quality on par with state-of-the-art diffusion models such as DALL-E 3 and SANA, while preserving the inherent flexibility and compositionality of autoregressive modeling. Our unified tokenization scheme allows the model to seamlessly handle a wide spectrum of tasks-including subject-driven generation, image editing, controllable synthesis, and dense prediction-within a single generative framework. To further boost usability, we incorporate efficient decoding strategies like inference-time scaling and speculative Jacobi sampling to improve quality and speed, respectively. Extensive evaluations on standard text-to-image benchmarks (e.g., GenEval, DPG) demonstrate that Lumina-mGPT 2.0 not only matches but in some cases surpasses diffusion-based models. Moreover, we confirm its multi-task capabilities on the Graph200K benchmark, with the native Lumina-mGPT 2.0 performing exceptionally well. These results position Lumina-mGPT 2.0 as a strong, flexible foundation model for unified multimodal generation. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-mGPT-2.0.
EuroCon: Benchmarking Parliament Deliberation for Political Consensus Finding
May 26, 2025Achieving political consensus is crucial yet challenging for the effective functioning of social governance. However, although frontier AI systems represented by large language models (LLMs) have developed rapidly in recent years, their capabilities on this scope are still understudied. In this paper, we introduce EuroCon, a novel benchmark constructed from 2,225 high-quality deliberation records of the European Parliament over 13 years, ranging from 2009 to 2022, to evaluate the ability of LLMs to reach political consensus among divergent party positions across diverse parliament settings. Specifically, EuroCon incorporates four factors to build each simulated parliament setting: specific political issues, political goals, participating parties, and power structures based on seat distribution. We also develop an evaluation framework for EuroCon to simulate real voting outcomes in different parliament settings, assessing whether LLM-generated resolutions meet predefined political goals. Our experimental results demonstrate that even state-of-the-art models remain undersatisfied with complex tasks like passing resolutions by a two-thirds majority and addressing security issues, while revealing some common strategies LLMs use to find consensus under different power structures, such as prioritizing the stance of the dominant party, highlighting EuroCon's promise as an effective platform for studying LLMs' ability to find political consensus.