 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiL-World: A Chunk-Wise World Model for VLA Policy-in-the-Loop Evaluation
Jun 04, 2026Vision-language-action (VLA) policies operate in a closed loop in real-world robot tasks: a robot observes the scene, executes an action chunk, and conditions its next decision on the resulting observation. However, most existing world models for robot action evaluation are limited to open-loop prediction along pre-collected action trajectories. This prevents them from supporting closed-loop VLA evaluation, where each action chunk must be conditioned on the observation generated by the previous execution. To address this gap, we propose PiL-World, a chunk-wise world model designed for policy-in-the-loop VLA evaluation. Given the current observation and the action trajectory rolled out by a VLA policy, PiL-World generates multi-view future observations that are consistent with the VLA rollout and match the image inputs required by the policy. By alternating between VLA inference and world-model prediction, PiL-World enables closed-loop evaluation without real robot execution at every step. To improve rollout fidelity, PiL-World conditions video generation on action-derived visual control from head-view robot motion and latent histories that encode task execution context, while jointly predicting complementary multi-view observations. Beyond successful teleoperated demonstrations, it also learns from failed execution trajectories, helping the imagined rollouts better match the distribution of real policy executions. We evaluate PiL-World on three real dual-arm manipulation tasks. PiL-World generates imagined rollouts that are highly consistent with real robot executions. More importantly, compared with the baseline, it reduces the error between VLA success rates measured in real-world rollouts and those estimated through closed-loop world-model evaluation from 63.2% to 12.0%.
Unsupervised Collaborative Domain Adaptation for Driving Scene Parsing
Jun 01, 2026Reliable driving scene parsing is a fundamental capability for autonomous vehicles operating in open and dynamic driving environments. However, adapting perception models to new deployment domains remains challenging because pixel-level annotations are expensive to obtain, while source-domain data are often inaccessible due to privacy, security, or ownership constraints. Existing source-free unsupervised domain adaptation methods typically rely on a single pre-trained source model, which makes the adapted perception system vulnerable to source-specific biases and limits its robustness under diverse road layouts, illumination conditions, weather patterns, and traffic conditions. This article presents an unsupervised collaborative domain adaptation (UCDA) framework for driving scene parsing in a source-free setting, which transfers complementary knowledge from multiple pre-trained source models to a unified target model without accessing any original source samples. To compare predictions from independently trained models, UCDA constructs a class-level prototype memory bank and estimates cross-model prediction reliability through prototype similarity, reducing the effect of inconsistent confidence scales across source models. Based on the resulting complementary supervision, UCDA adopts a two-stage transfer strategy: multiple source models are first refined on unlabeled target-domain driving data through collaborative optimization with positive and negative consistency constraints, and their validated expertise is then distilled into a single deployable target model. Comprehensive evaluations on public driving-scene datasets and real-world data collected from an autonomous vehicle platform demonstrate that UCDA effectively consolidates complementary multi-source knowledge, improving target-domain scene parsing reliability and generalization across diverse driving environments.
The Midas Touch for Metric Depth
May 12, 2026Recent advances have markedly improved the cross-scene generalization of relative depth estimation, yet its practical applicability remains limited by the absence of metric scale, local inconsistencies, and low computational efficiency. To address these issues, we present \emph{\textbf{M}idas \textbf{T}ouch for \textbf{D}epth} (MTD), a mathematically interpretable approach that converts relative depth into metric depth using only extremely sparse 3D data. To eliminate local scale inconsistencies, it applies a segment-wise recovery strategy via sparse graph optimization, followed by a pixel-wise refinement strategy using a discontinuity-aware geodesic cost. MTD exhibits strong generalization and achieves substantial accuracy improvements over previous depth completion and depth estimation methods. Moreover, its lightweight, plug-and-play design facilitates deployment and integration on diverse downstream 3D tasks. Project page is available at https://mias.group/MTD.
Weakly-Supervised Referring Video Object Segmentation through Text Supervision
Apr 21, 2026Referring video object segmentation (RVOS) aims to segment the target instance in a video, referred by a text expression. Conventional approaches are mostly supervised learning, requiring expensive pixel-level mask annotations. To tackle it, weakly-supervised RVOS has recently been proposed to replace mask annotations with bounding boxes or points, which are however still costly and labor-intensive. In this paper, we design a novel weakly-supervised RVOS method, namely WSRVOS, to train the model with only text expressions. Given an input video and the referring expression, we first design a contrastive referring expression augmentation scheme that leverages the captioning capabilities of a multimodal large language model to generate both positive and negative expressions. We extract visual and linguistic features from the input video and generated expressions, then perform bi-directional vision-language feature selection and interaction to enable fine-grained multimodal alignment. Next, we propose an instance-aware expression classification scheme to optimize the model in distinguishing positive from negative expressions. Also, we introduce a positive-prediction fusion strategy to generate high-quality pseudo-masks, which serve as additional supervision to the model. Last, we design a temporal segment ranking constraint such that the overlaps between mask predictions of temporally neighboring frames are required to conform to specific orders. Extensive experiments on four publicly available RVOS datasets, including A2D Sentences, J-HMDB Sentences, Ref-YouTube-VOS, and Ref-DAVIS17, demonstrate the superiority of our method. Code is available at https://github.com/viscom-tongji/WSRVOS.
An Instance-Centric Panoptic Occupancy Prediction Benchmark for Autonomous Driving
Mar 28, 2026Panoptic occupancy prediction aims to jointly infer voxel-wise semantics and instance identities within a unified 3D scene representation. Nevertheless, progress in this field remains constrained by the absence of high-quality 3D mesh resources, instance-level annotations, and physically consistent occupancy datasets. Existing benchmarks typically provide incomplete and low-resolution geometry without instance-level annotations, limiting the development of models capable of achieving precise geometric reconstruction, reliable occlusion reasoning, and holistic 3D understanding. To address these challenges, this paper presents an instance-centric benchmark for the 3D panoptic occupancy prediction task. Specifically, we introduce ADMesh, the first unified 3D mesh library tailored for autonomous driving, which integrates over 15K high-quality 3D models with diverse textures and rich semantic annotations. Building upon ADMesh, we further construct CarlaOcc, a large-scale, physically consistent panoptic occupancy dataset generated using the CARLA simulator. This dataset contains over 100K frames with fine-grained, instance-level occupancy ground truth at voxel resolutions as fine as 0.05 m. Furthermore, standardized evaluation metrics are introduced to quantify the quality of existing occupancy datasets. Finally, a systematic benchmark of representative models is established on the proposed dataset, which provides a unified platform for fair comparison and reproducible research in the field of 3D panoptic perception. Code and dataset are available at https://mias.group/CarlaOcc.
Revealing Combinatorial Reasoning of GNNs via Graph Concept Bottleneck Layer
Mar 02, 2026Despite their success in various domains, the growing dependence on GNNs raises a critical concern about the nature of the combinatorial reasoning underlying their predictions, which is often hidden within their black-box architectures. Addressing this challenge requires understanding how GNNs translate topological patterns into logical rules. However, current works only uncover the hard logical rules over graph concepts, which cannot quantify the contribution of each concept to prediction. Moreover, they are post-hoc interpretable methods that generate explanations after model training and may not accurately reflect the true combinatorial reasoning of GNNs, since they approximate it with a surrogate. In this work, we develop a graph concept bottleneck layer that can be integrated into any GNN architectures to guide them to predict the selected discriminative global graph concepts. The predicted concept scores are further projected to class labels by a sparse linear layer. It enforces the combinatorial reasoning of GNNs' predictions to fit the soft logical rule over graph concepts and thus can quantify the contribution of each concept. To further improve the quality of the concept bottleneck, we treat concepts as "graph words" and graphs as "graph sentences", and leverage language models to learn graph concept embeddings. Extensive experiments on multiple datasets show that our method GCBMs achieve state-of-the-art performance both in classification and interpretability.
Two-Stream Interactive Joint Learning of Scene Parsing and Geometric Vision Tasks
Feb 14, 2026Inspired by the human visual system, which operates on two parallel yet interactive streams for contextual and spatial understanding, this article presents Two Interactive Streams (TwInS), a novel bio-inspired joint learning framework capable of simultaneously performing scene parsing and geometric vision tasks. TwInS adopts a unified, general-purpose architecture in which multi-level contextual features from the scene parsing stream are infused into the geometric vision stream to guide its iterative refinement. In the reverse direction, decoded geometric features are projected into the contextual feature space for selective heterogeneous feature fusion via a novel cross-task adapter, which leverages rich cross-view geometric cues to enhance scene parsing. To eliminate the dependence on costly human-annotated correspondence ground truth, TwInS is further equipped with a tailored semi-supervised training strategy, which unleashes the potential of large-scale multi-view data and enables continuous self-evolution without requiring ground-truth correspondences. Extensive experiments conducted on three public datasets validate the effectiveness of TwInS's core components and demonstrate its superior performance over existing state-of-the-art approaches. The source code will be made publicly available upon publication.
Wavelet-Domain Masked Image Modeling for Color-Consistent HDR Video Reconstruction
Feb 07, 2026High Dynamic Range (HDR) video reconstruction aims to recover fine brightness, color, and details from Low Dynamic Range (LDR) videos. However, existing methods often suffer from color inaccuracies and temporal inconsistencies. To address these challenges, we propose WMNet, a novel HDR video reconstruction network that leverages Wavelet domain Masked Image Modeling (W-MIM). WMNet adopts a two-phase training strategy: In Phase I, W-MIM performs self-reconstruction pre-training by selectively masking color and detail information in the wavelet domain, enabling the network to develop robust color restoration capabilities. A curriculum learning scheme further refines the reconstruction process. Phase II fine-tunes the model using the pre-trained weights to improve the final reconstruction quality. To improve temporal consistency, we introduce the Temporal Mixture of Experts (T-MoE) module and the Dynamic Memory Module (DMM). T-MoE adaptively fuses adjacent frames to reduce flickering artifacts, while DMM captures long-range dependencies, ensuring smooth motion and preservation of fine details. Additionally, since existing HDR video datasets lack scene-based segmentation, we reorganize HDRTV4K into HDRTV4K-Scene, establishing a new benchmark for HDR video reconstruction. Extensive experiments demonstrate that WMNet achieves state-of-the-art performance across multiple evaluation metrics, significantly improving color fidelity, temporal coherence, and perceptual quality. The code is available at: https://github.com/eezkni/WMNet
Towards High-Consistency Embodied World Model with Multi-View Trajectory Videos
Nov 19, 2025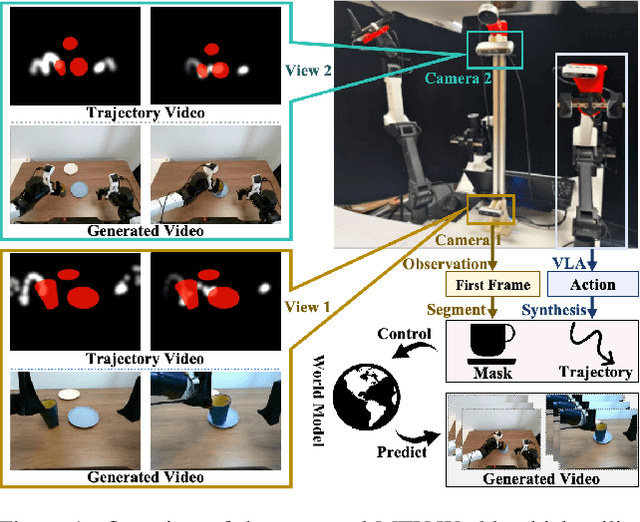

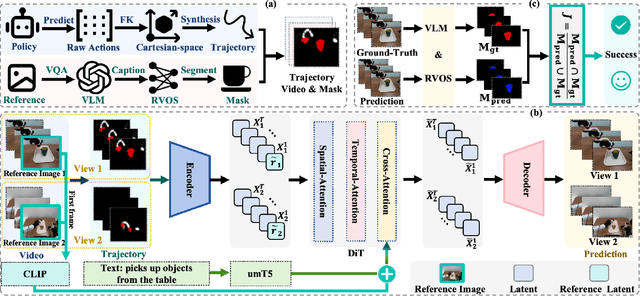
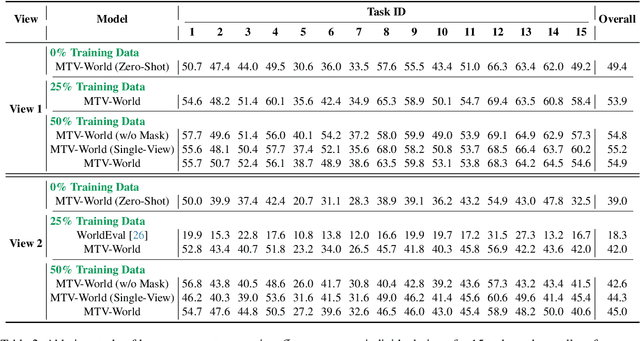
Embodied world models aim to predict and interact with the physical world through visual observations and actions. However, existing models struggle to accurately translate low-level actions (e.g., joint positions) into precise robotic movements in predicted frames, leading to inconsistencies with real-world physical interactions. To address these limitations, we propose MTV-World, an embodied world model that introduces Multi-view Trajectory-Video control for precise visuomotor prediction. Specifically, instead of directly using low-level actions for control, we employ trajectory videos obtained through camera intrinsic and extrinsic parameters and Cartesian-space transformation as control signals. However, projecting 3D raw actions onto 2D images inevitably causes a loss of spatial information, making a single view insufficient for accurate interaction modeling. To overcome this, we introduce a multi-view framework that compensates for spatial information loss and ensures high-consistency with physical world. MTV-World forecasts future frames based on multi-view trajectory videos as input and conditioning on an initial frame per view. Furthermore, to systematically evaluate both robotic motion precision and object interaction accuracy, we develop an auto-evaluation pipeline leveraging multimodal large models and referring video object segmentation models. To measure spatial consistency, we formulate it as an object location matching problem and adopt the Jaccard Index as the evaluation metric. Extensive experiments demonstrate that MTV-World achieves precise control execution and accurate physical interaction modeling in complex dual-arm scenarios.
Structural Similarity-Inspired Unfolding for Lightweight Image Super-Resolution
Jun 13, 2025Major efforts in data-driven image super-resolution (SR) primarily focus on expanding the receptive field of the model to better capture contextual information. However, these methods are typically implemented by stacking deeper networks or leveraging transformer-based attention mechanisms, which consequently increases model complexity. In contrast, model-driven methods based on the unfolding paradigm show promise in improving performance while effectively maintaining model compactness through sophisticated module design. Based on these insights, we propose a Structural Similarity-Inspired Unfolding (SSIU) method for efficient image SR. This method is designed through unfolding an SR optimization function constrained by structural similarity, aiming to combine the strengths of both data-driven and model-driven approaches. Our model operates progressively following the unfolding paradigm. Each iteration consists of multiple Mixed-Scale Gating Modules (MSGM) and an Efficient Sparse Attention Module (ESAM). The former implements comprehensive constraints on features, including a structural similarity constraint, while the latter aims to achieve sparse activation. In addition, we design a Mixture-of-Experts-based Feature Selector (MoE-FS) that fully utilizes multi-level feature information by combining features from different steps. Extensive experiments validate the efficacy and efficiency of our unfolding-inspired network. Our model outperforms current state-of-the-art models, boasting lower parameter counts and reduced memory consumption. Our code will be available at: https://github.com/eezkni/SSIU