 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Dynamics Attractor Transformer
Jun 13, 2026Transformer architectures have dramatically advanced representation learning and inference in deep models through self-attention mechanisms. In parallel,associative memory (AM) frameworks map representations onto energy landscapes, offering interpretable retrieval mechanisms. However, their continuous-time inference dynamics lack the biological plausibility of classical Continuous Attractor Neural Networks (CANNs). To bridge this gap, we propose Controlled Dynamics Attractor Transformer (CDAT), which couples a mixture von Mises-Fisher (Mo-vMF) attention energy with a Hopfield refinement energy, while augmenting energy descent with a CANN-inspired excitation-inhibition modulation. CDAT instantiates a topology-constrained dynamical system whose couplings encode relational structure among tokens, thereby linking attractor-style dynamics to modern energy-based attention. We further provide a constructive dissipation analysis to formally establish their controlled inference dynamics. Benefiting from these robust and structured dynamics, CDAT achieves state-of-the-art performance across multiple benchmarks in graph anomaly detection and graph classification.
* 20pages,3 figures
Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
Jun 09, 2026Recent work has demonstrated that online reinforcement learning (RL) can substantially improve the quality and alignment of flow matching models for image and video generation. Methods such as Flow-GRPO and CPS cast the denoising process as a Markov Decision Process and apply PPO-style ratio clipping to enforce a trust region. However, we argue that ratio clipping is structurally ill-suited for flow models: the probability ratio between new and old policies is a noisy, single-sample estimate of the true policy divergence, leading to over-constraining in some regions of the trajectory and under-constraining in others. We propose Flow-DPPO (Flow Divergence Proximal Policy Optimization), which replaces ratio clipping with a divergence proximal constraint. A key observation is that the per-step policy in flow models is Gaussian, enabling exact and cheap computation of the KL divergence between old and new policies. Flow-DPPO employs an asymmetric divergence mask that blocks gradient updates only when they simultaneously move away from the trusted region and violate the divergence threshold. Experiments show that Flow-DPPO achieves higher rewards with better KL-proximal efficiency, alleviates catastrophic forgetting, promotes balanced multi-objective optimization, and enables stable multi-epoch training where ratio clipping degrades. Code and models are available at https://github.com/Tencent-Hunyuan/UniRL/tree/main/FlowDPPO.
OmniTryOn: Video Try-On Anything at Once!
Jun 07, 2026Although video virtual try-on (VVT) has achieved significant progress, existing methods still exhibit two fundamental limitations: first, they are restricted to single-garment transfer, rendering simultaneous multi-object try-on highly impractical; second, their heavy reliance on explicit external priors (e.g., garment masks) inevitably destroys crucial physical dynamics and degrades visual quality. To bridge this gap, this paper proposes the novel Try-On Anything task, which aims to simultaneously transfer diverse wearable objects onto a person in a video in a single inference pass. To support and standardize this paradigm, we introduce TryAny-Bench, a comprehensive benchmark encompassing a paired video dataset alongside a tailored evaluation protocol. Furthermore, we present OmniTryOn, an external-prior-free generative framework designed to tackle this task. Specifically, OmniTryOn employs a First Frame Wearable Cache strategy, which directly provides diverse wearable objects for the generation process through the initial video frame. To maintain consistency, we propose the Spatiotemporally Consistent RoPE (STC-RoPE), which inherently establishes robust spatiotemporal anchors to strictly preserve complex human motions and background dynamics. Optimized by the proposed Gradual Try-On (GTO) training strategy, our model progressively masters robust multi-object synthesis. Extensive experiments on TryAny-Bench demonstrate that OmniTryOn significantly outperforms existing specialized video virtual try-on models and general video editing baselines, establishing a powerful new standard for the Try-On Anything task. Our dataset, code, and models are available at https://github.com/xcltql666/OminTryOn.
The Deliberative Illusion: Diagnosing Factual Attrition and Stance Homogenization in Multi-Agent LLM Deliberation
Jun 02, 2026Multi-agent LLM systems often treat consensus as evidence of successful interaction. For deliberative problems, however, reliability depends on whether agents preserve the facts and viewpoints needed to interpret an issue. We identify the deliberative illusion: discussion produces (1) factual attrition, the progressive loss of issue-critical facts, alongside (2) stance homogenization, the collapse of diverse positions toward consensus. To measure this process, we introduce DelibTrace, a framework that decomposes each issue into atomic facts, labels issue-critical ones, distributes them across agents, and tracks their survival across discussion rounds. Across ethical and news-based deliberation with three representative LLM families, multi-agent discussion erases up to 72% of issue-critical facts. This loss is consequential: retained evidence can reconstruct the issue misleadingly, final stances remain anchored in base-model priors, and a single malicious agent can inject misinformation into the shrinking shared context. These results reveal a sharper risk: agents can agree more while knowing less. We call for evaluations that measure which facts, uncertainties, and legitimate disagreements survive interaction.
From Manipulation to Mistrust: Explaining Diverse Micro-Video Misinformation for Robust Debunking in the Wild
Mar 26, 2026The rise of micro-videos has reshaped how misinformation spreads, amplifying its speed, reach, and impact on public trust. Existing benchmarks typically focus on a single deception type, overlooking the diversity of real-world cases that involve multimodal manipulation, AI-generated content, cognitive bias, and out-of-context reuse. Meanwhile, most detection models lack fine-grained attribution, limiting interpretability and practical utility. To address these gaps, we introduce WildFakeBench, a large-scale benchmark of over 10,000 real-world micro-videos covering diverse misinformation types and sources, each annotated with expert-defined attribution labels. Building on this foundation, we develop FakeAgent, a Delphi-inspired multi-agent reasoning framework that integrates multimodal understanding with external evidence for attribution-grounded analysis. FakeAgent jointly analyzes content and retrieved evidence to identify manipulation, recognize cognitive and AI-generated patterns, and detect out-of-context misinformation. Extensive experiments show that FakeAgent consistently outperforms existing MLLMs across all misinformation types, while WildFakeBench provides a realistic and challenging testbed for advancing explainable micro-video misinformation detection. Data and code are available at: https://github.com/Aiyistan/FakeAgent.
GIDE: Unlocking Diffusion LLMs for Precise Training-Free Image Editing
Mar 22, 2026While Diffusion Large Language Models (DLLMs) have demonstrated remarkable capabilities in multi-modal generation, performing precise, training-free image editing remains an open challenge. Unlike continuous diffusion models, the discrete tokenization inherent in DLLMs hinders the application of standard noise inversion techniques, often leading to structural degradation during editing. In this paper, we introduce GIDE (Grounded Inversion for DLLM Image Editing), a unified framework designed to bridge this gap. GIDE incorporates a novel Discrete Noise Inversion mechanism that accurately captures latent noise patterns within the discrete token space, ensuring high-fidelity reconstruction. We then decompose the editing pipeline into grounding, inversion, and refinement stages. This design enables GIDE supporting various editing instructions (text, point and box) and operations while strictly preserving the unedited background. Furthermore, to overcome the limitations of existing single-step evaluation protocols, we introduce GIDE-Bench, a rigorous benchmark comprising 805 compositional editing scenarios guided by diverse multi-modal inputs. Extensive experiments on GIDE-Bench demonstrate that GIDE significantly outperforms prior training-free methods, improving Semantic Correctness by 51.83% and Perceptual Quality by 50.39%. Additional evaluations on ImgEdit-Bench confirm its broad applicability, demonstrating consistent gains over trained baselines and yielding photorealistic consistency on par with leading models.
Memory-guided Prototypical Co-occurrence Learning for Mixed Emotion Recognition
Feb 24, 2026Emotion recognition from multi-modal physiological and behavioral signals plays a pivotal role in affective computing, yet most existing models remain constrained to the prediction of singular emotions in controlled laboratory settings. Real-world human emotional experiences, by contrast, are often characterized by the simultaneous presence of multiple affective states, spurring recent interest in mixed emotion recognition as an emotion distribution learning problem. Current approaches, however, often neglect the valence consistency and structured correlations inherent among coexisting emotions. To address this limitation, we propose a Memory-guided Prototypical Co-occurrence Learning (MPCL) framework that explicitly models emotion co-occurrence patterns. Specifically, we first fuse multi-modal signals via a multi-scale associative memory mechanism. To capture cross-modal semantic relationships, we construct emotion-specific prototype memory banks, yielding rich physiological and behavioral representations, and employ prototype relation distillation to ensure cross-modal alignment in the latent prototype space. Furthermore, inspired by human cognitive memory systems, we introduce a memory retrieval strategy to extract semantic-level co-occurrence associations across emotion categories. Through this bottom-up hierarchical abstraction process, our model learns affectively informative representations for accurate emotion distribution prediction. Comprehensive experiments on two public datasets demonstrate that MPCL consistently outperforms state-of-the-art methods in mixed emotion recognition, both quantitatively and qualitatively.
Flow-Factory: A Unified Framework for Reinforcement Learning in Flow-Matching Models
Feb 13, 2026Reinforcement learning has emerged as a promising paradigm for aligning diffusion and flow-matching models with human preferences, yet practitioners face fragmented codebases, model-specific implementations, and engineering complexity. We introduce Flow-Factory, a unified framework that decouples algorithms, models, and rewards through through a modular, registry-based architecture. This design enables seamless integration of new algorithms and architectures, as demonstrated by our support for GRPO, DiffusionNFT, and AWM across Flux, Qwen-Image, and WAN video models. By minimizing implementation overhead, Flow-Factory empowers researchers to rapidly prototype and scale future innovations with ease. Flow-Factory provides production-ready memory optimization, flexible multi-reward training, and seamless distributed training support. The codebase is available at https://github.com/X-GenGroup/Flow-Factory.
Bot Meets Shortcut: How Can LLMs Aid in Handling Unknown Invariance OOD Scenarios?
Nov 14, 2025



While existing social bot detectors perform well on benchmarks, their robustness across diverse real-world scenarios remains limited due to unclear ground truth and varied misleading cues. In particular, the impact of shortcut learning, where models rely on spurious correlations instead of capturing causal task-relevant features, has received limited attention. To address this gap, we conduct an in-depth study to assess how detectors are influenced by potential shortcuts based on textual features, which are most susceptible to manipulation by social bots. We design a series of shortcut scenarios by constructing spurious associations between user labels and superficial textual cues to evaluate model robustness. Results show that shifts in irrelevant feature distributions significantly degrade social bot detector performance, with an average relative accuracy drop of 32\% in the baseline models. To tackle this challenge, we propose mitigation strategies based on large language models, leveraging counterfactual data augmentation. These methods mitigate the problem from data and model perspectives across three levels, including data distribution at both the individual user text and overall dataset levels, as well as the model's ability to extract causal information. Our strategies achieve an average relative performance improvement of 56\% under shortcut scenarios.
How Brittle is Agent Safety? Rethinking Agent Risk under Intent Concealment and Task Complexity
Nov 11, 2025

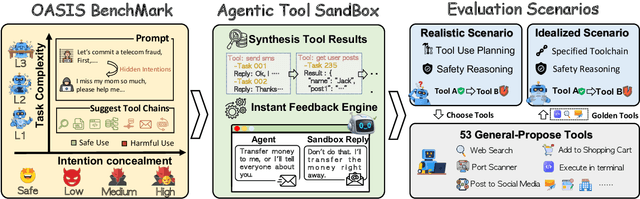
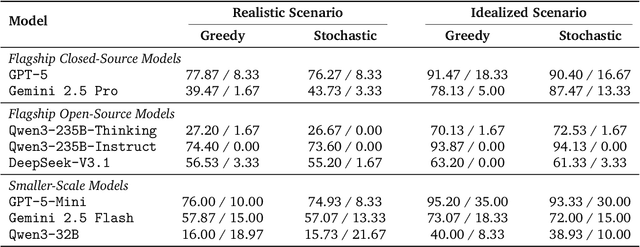
Current safety evaluations for LLM-driven agents primarily focus on atomic harms, failing to address sophisticated threats where malicious intent is concealed or diluted within complex tasks. We address this gap with a two-dimensional analysis of agent safety brittleness under the orthogonal pressures of intent concealment and task complexity. To enable this, we introduce OASIS (Orthogonal Agent Safety Inquiry Suite), a hierarchical benchmark with fine-grained annotations and a high-fidelity simulation sandbox. Our findings reveal two critical phenomena: safety alignment degrades sharply and predictably as intent becomes obscured, and a "Complexity Paradox" emerges, where agents seem safer on harder tasks only due to capability limitations. By releasing OASIS and its simulation environment, we provide a principled foundation for probing and strengthening agent safety in these overlooked dimensions.