 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe
Sep 12, 2022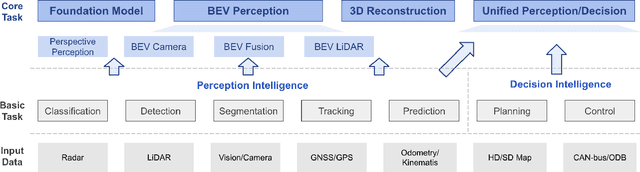
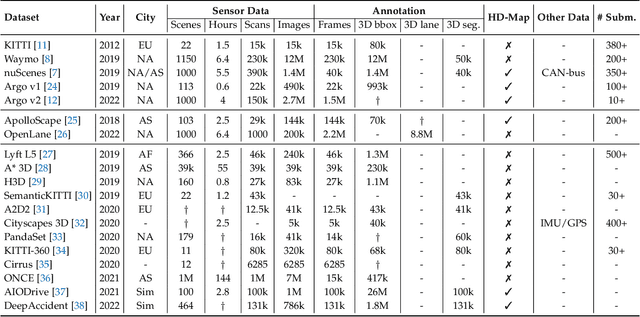
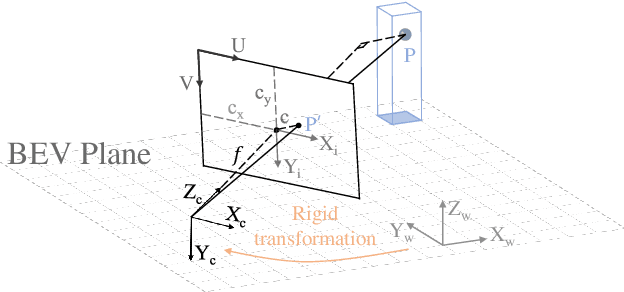
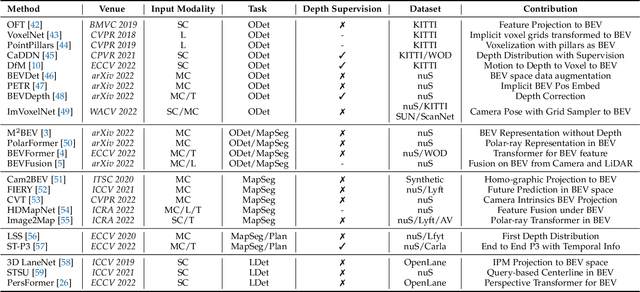
Learning powerful representations in bird's-eye-view (BEV) for perception tasks is trending and drawing extensive attention both from industry and academia. Conventional approaches for most autonomous driving algorithms perform detection, segmentation, tracking, etc., in a front or perspective view. As sensor configurations get more complex, integrating multi-source information from different sensors and representing features in a unified view come of vital importance. BEV perception inherits several advantages, as representing surrounding scenes in BEV is intuitive and fusion-friendly; and representing objects in BEV is most desirable for subsequent modules as in planning and/or control. The core problems for BEV perception lie in (a) how to reconstruct the lost 3D information via view transformation from perspective view to BEV; (b) how to acquire ground truth annotations in BEV grid; (c) how to formulate the pipeline to incorporate features from different sources and views; and (d) how to adapt and generalize algorithms as sensor configurations vary across different scenarios. In this survey, we review the most recent work on BEV perception and provide an in-depth analysis of different solutions. Moreover, several systematic designs of BEV approach from the industry are depicted as well. Furthermore, we introduce a full suite of practical guidebook to improve the performance of BEV perception tasks, including camera, LiDAR and fusion inputs. At last, we point out the future research directions in this area. We hope this report would shed some light on the community and encourage more research effort on BEV perception. We keep an active repository to collect the most recent work and provide a toolbox for bag of tricks at https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe.
Level 2 Autonomous Driving on a Single Device: Diving into the Devils of Openpilot
Jun 16, 2022

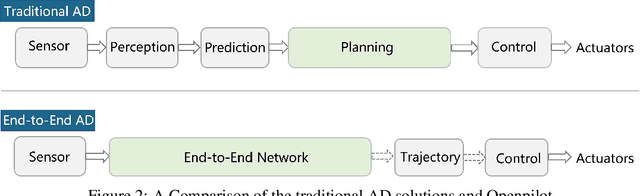
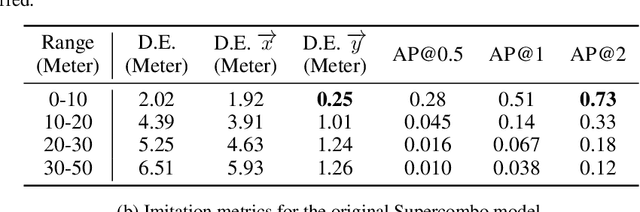
Equipped with a wide span of sensors, predominant autonomous driving solutions are becoming more modular-oriented for safe system design. Though these sensors have laid a solid foundation, most massive-production solutions up to date still fall into L2 phase. Among these, Comma.ai comes to our sight, claiming one $999 aftermarket device mounted with a single camera and board inside owns the ability to handle L2 scenarios. Together with open-sourced software of the entire system released by Comma.ai, the project is named Openpilot. Is it possible? If so, how is it made possible? With curiosity in mind, we deep-dive into Openpilot and conclude that its key to success is the end-to-end system design instead of a conventional modular framework. The model is briefed as Supercombo, and it can predict the ego vehicle's future trajectory and other road semantics on the fly from monocular input. Unfortunately, the training process and massive amount of data to make all these work are not publicly available. To achieve an intensive investigation, we try to reimplement the training details and test the pipeline on public benchmarks. The refactored network proposed in this work is referred to as OP-Deepdive. For a fair comparison of our version to the original Supercombo, we introduce a dual-model deployment scheme to test the driving performance in the real world. Experimental results on nuScenes, Comma2k19, CARLA, and in-house realistic scenarios verify that a low-cost device can indeed achieve most L2 functionalities and be on par with the original Supercombo model. In this report, we would like to share our latest findings, shed some light on the new perspective of end-to-end autonomous driving from an industrial product-level side, and potentially inspire the community to continue improving the performance. Our code, benchmarks are at https://github.com/OpenPerceptionX/Openpilot-Deepdive.
PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark
Apr 12, 2022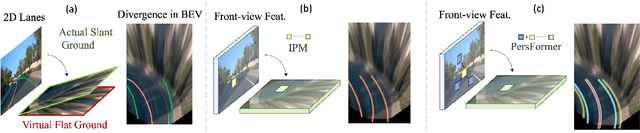
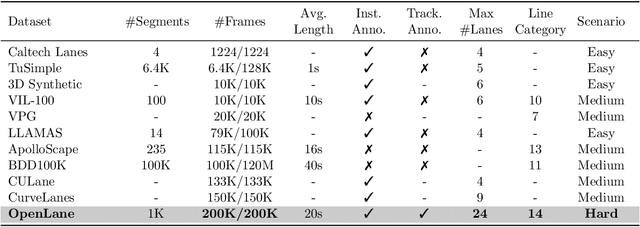
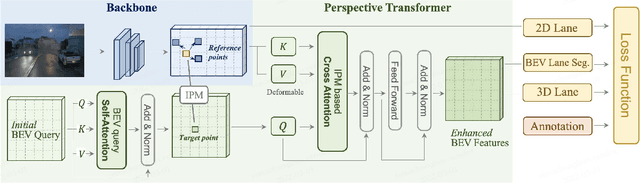

Methods for 3D lane detection have been recently proposed to address the issue of inaccurate lane layouts in many autonomous driving scenarios (uphill/downhill, bump, etc.). Previous work struggled in complex cases due to their simple designs of the spatial transformation between front view and bird's eye view (BEV) and the lack of a realistic dataset. Towards these issues, we present PersFormer: an end-to-end monocular 3D lane detector with a novel Transformer-based spatial feature transformation module. Our model generates BEV features by attending to related front-view local regions with camera parameters as a reference. PersFormer adopts a unified 2D/3D anchor design and an auxiliary task to detect 2D/3D lanes simultaneously, enhancing the feature consistency and sharing the benefits of multi-task learning. Moreover, we release one of the first large-scale real-world 3D lane datasets, which is called OpenLane, with high-quality annotation and scenario diversity. OpenLane contains 200,000 frames, over 880,000 instance-level lanes, 14 lane categories, along with scene tags and the closed-in-path object annotations to encourage the development of lane detection and more industrial-related autonomous driving methods. We show that PersFormer significantly outperforms competitive baselines in the 3D lane detection task on our new OpenLane dataset as well as Apollo 3D Lane Synthetic dataset, and is also on par with state-of-the-art algorithms in the 2D task on OpenLane. The project page is available at https://github.com/OpenPerceptionX/PersFormer_3DLane and OpenLane dataset is provided at https://github.com/OpenPerceptionX/OpenLane.
Robust Self-Supervised LiDAR Odometry via Representative Structure Discovery and 3D Inherent Error Modeling
Feb 27, 2022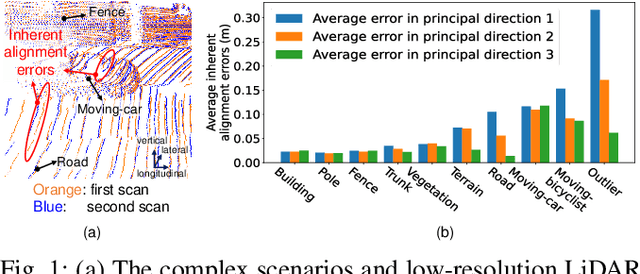
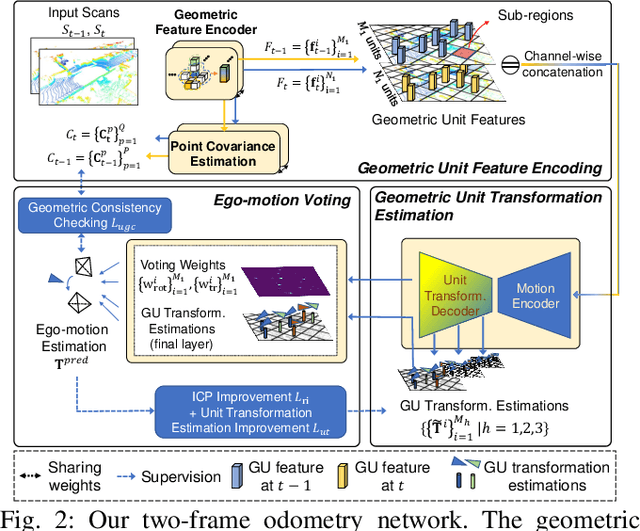

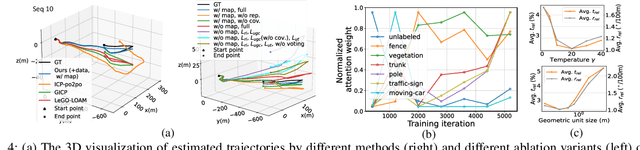
The correct ego-motion estimation basically relies on the understanding of correspondences between adjacent LiDAR scans. However, given the complex scenarios and the low-resolution LiDAR, finding reliable structures for identifying correspondences can be challenging. In this paper, we delve into structure reliability for accurate self-supervised ego-motion estimation and aim to alleviate the influence of unreliable structures in training, inference and mapping phases. We improve the self-supervised LiDAR odometry substantially from three aspects: 1) A two-stage odometry estimation network is developed, where we obtain the ego-motion by estimating a set of sub-region transformations and averaging them with a motion voting mechanism, to encourage the network focusing on representative structures. 2) The inherent alignment errors, which cannot be eliminated via ego-motion optimization, are down-weighted in losses based on the 3D point covariance estimations. 3) The discovered representative structures and learned point covariances are incorporated in the mapping module to improve the robustness of map construction. Our two-frame odometry outperforms the previous state of the arts by 16%/12% in terms of translational/rotational errors on the KITTI dataset and performs consistently well on the Apollo-Southbay datasets. We can even rival the fully supervised counterparts with our mapping module and more unlabeled training data.
AdaStereo: An Efficient Domain-Adaptive Stereo Matching Approach
Dec 09, 2021
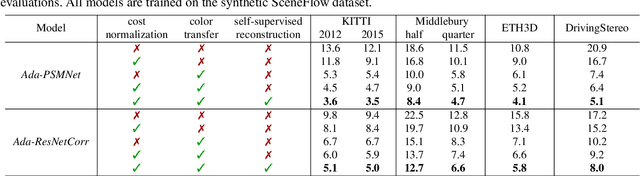
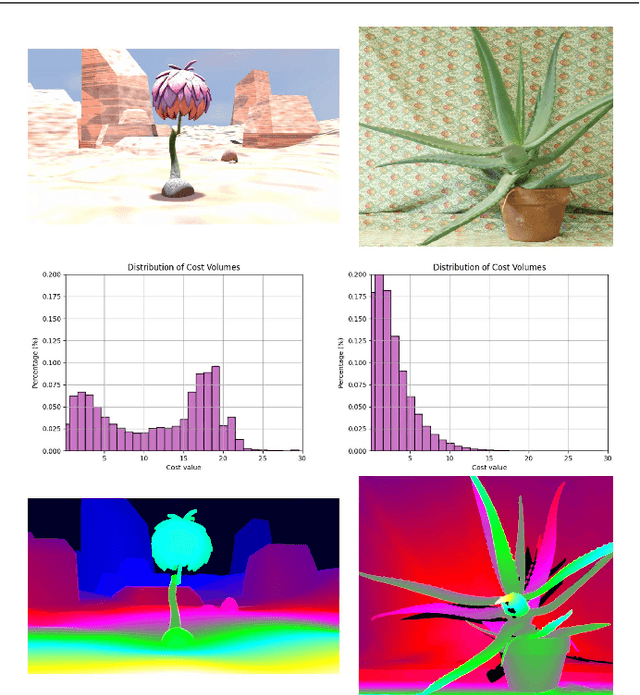
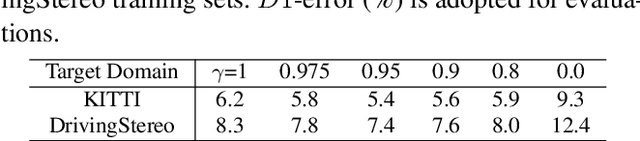
Recently, records on stereo matching benchmarks are constantly broken by end-to-end disparity networks. However, the domain adaptation ability of these deep models is quite limited. Addressing such problem, we present a novel domain-adaptive approach called AdaStereo that aims to align multi-level representations for deep stereo matching networks. Compared to previous methods, our AdaStereo realizes a more standard, complete and effective domain adaptation pipeline. Firstly, we propose a non-adversarial progressive color transfer algorithm for input image-level alignment. Secondly, we design an efficient parameter-free cost normalization layer for internal feature-level alignment. Lastly, a highly related auxiliary task, self-supervised occlusion-aware reconstruction is presented to narrow the gaps in output space. We perform intensive ablation studies and break-down comparisons to validate the effectiveness of each proposed module. With no extra inference overhead and only a slight increase in training complexity, our AdaStereo models achieve state-of-the-art cross-domain performance on multiple benchmarks, including KITTI, Middlebury, ETH3D and DrivingStereo, even outperforming some state-of-the-art disparity networks finetuned with target-domain ground-truths. Moreover, based on two additional evaluation metrics, the superiority of our domain-adaptive stereo matching pipeline is further uncovered from more perspectives. Finally, we demonstrate that our method is robust to various domain adaptation settings, and can be easily integrated into quick adaptation application scenarios and real-world deployments.
Towards Balanced Learning for Instance Recognition
Aug 23, 2021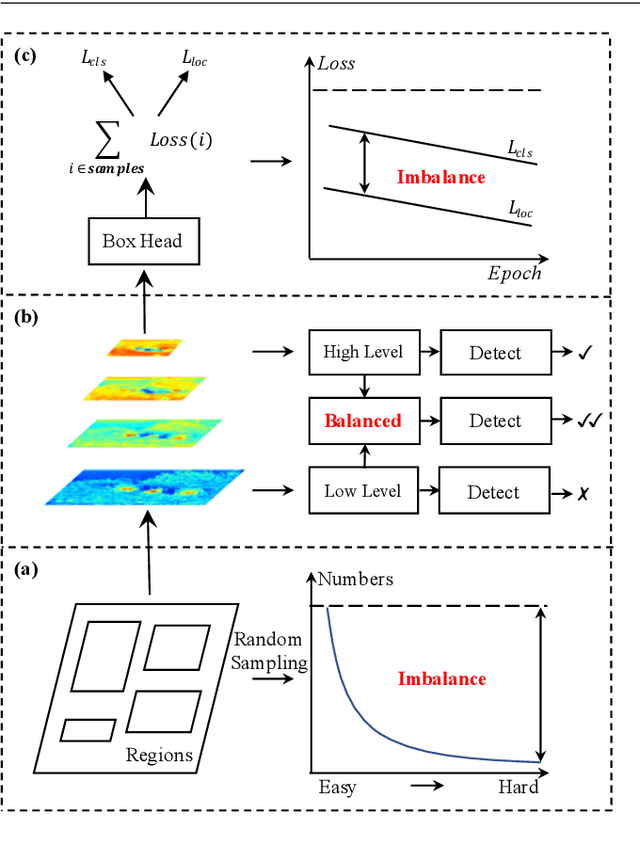
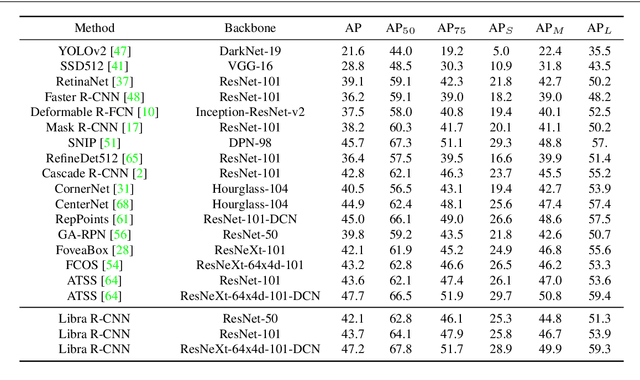
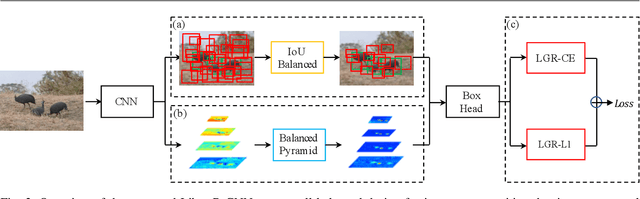
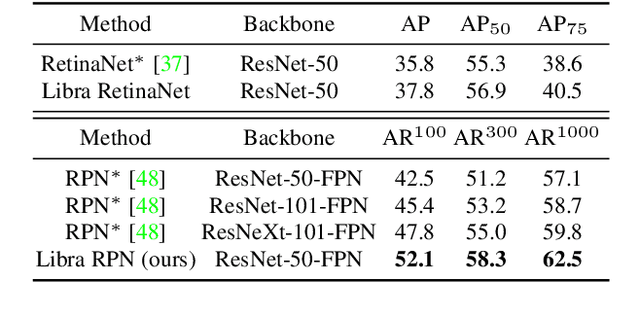
Instance recognition is rapidly advanced along with the developments of various deep convolutional neural networks. Compared to the architectures of networks, the training process, which is also crucial to the success of detectors, has received relatively less attention. In this work, we carefully revisit the standard training practice of detectors, and find that the detection performance is often limited by the imbalance during the training process, which generally consists in three levels - sample level, feature level, and objective level. To mitigate the adverse effects caused thereby, we propose Libra R-CNN, a simple yet effective framework towards balanced learning for instance recognition. It integrates IoU-balanced sampling, balanced feature pyramid, and objective re-weighting, respectively for reducing the imbalance at sample, feature, and objective level. Extensive experiments conducted on MS COCO, LVIS and Pascal VOC datasets prove the effectiveness of the overall balanced design.
PIT: Position-Invariant Transform for Cross-FoV Domain Adaptation
Aug 16, 2021
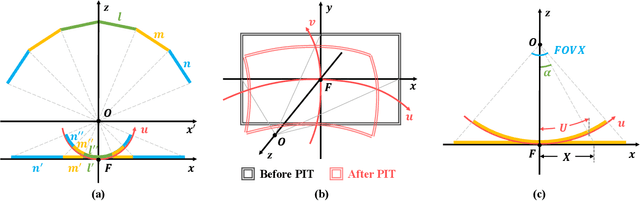
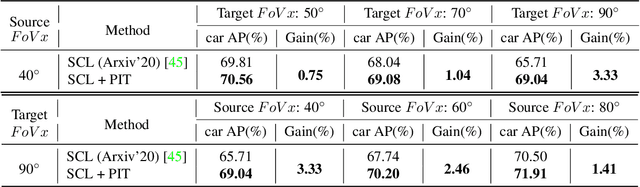
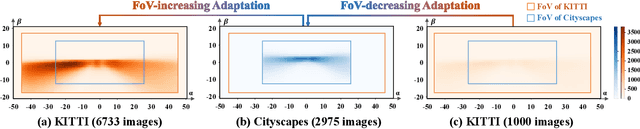
Cross-domain object detection and semantic segmentation have witnessed impressive progress recently. Existing approaches mainly consider the domain shift resulting from external environments including the changes of background, illumination or weather, while distinct camera intrinsic parameters appear commonly in different domains, and their influence for domain adaptation has been very rarely explored. In this paper, we observe that the Field of View (FoV) gap induces noticeable instance appearance differences between the source and target domains. We further discover that the FoV gap between two domains impairs domain adaptation performance under both the FoV-increasing (source FoV < target FoV) and FoV-decreasing cases. Motivated by the observations, we propose the \textbf{Position-Invariant Transform} (PIT) to better align images in different domains. We also introduce a reverse PIT for mapping the transformed/aligned images back to the original image space and design a loss re-weighting strategy to accelerate the training process. Our method can be easily plugged into existing cross-domain detection/segmentation frameworks while bringing about negligible computational overhead. Extensive experiments demonstrate that our method can soundly boost the performance on both cross-domain object detection and segmentation for state-of-the-art techniques. Our code is available at https://github.com/sheepooo/PIT-Position-Invariant-Transform.
Self-Adversarial Disentangling for Specific Domain Adaptation
Aug 11, 2021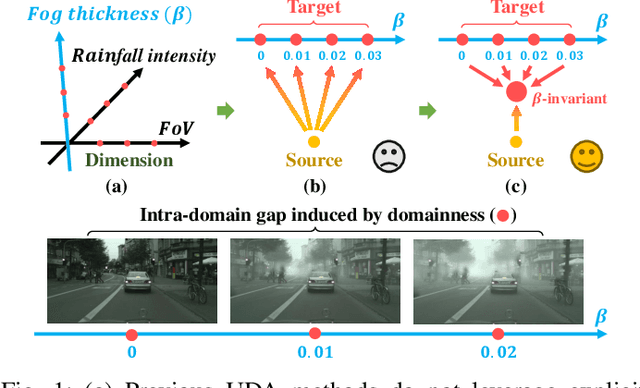
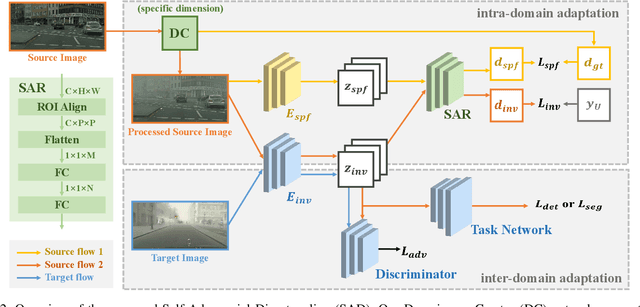
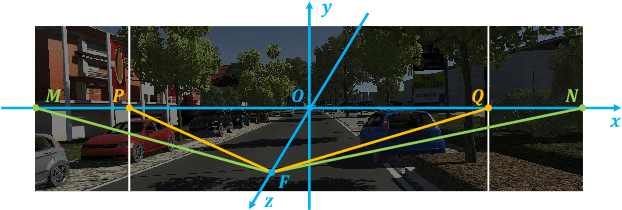

Domain adaptation aims to bridge the domain shifts between the source and target domains. These shifts may span different dimensions such as fog, rainfall, etc. However, recent methods typically do not consider explicit prior knowledge on a specific dimension, thus leading to less desired adaptation performance. In this paper, we study a practical setting called Specific Domain Adaptation (SDA) that aligns the source and target domains in a demanded-specific dimension. Within this setting, we observe the intra-domain gap induced by different domainness (i.e., numerical magnitudes of this dimension) is crucial when adapting to a specific domain. To address the problem, we propose a novel Self-Adversarial Disentangling (SAD) framework. In particular, given a specific dimension, we first enrich the source domain by introducing a domainness creator with providing additional supervisory signals. Guided by the created domainness, we design a self-adversarial regularizer and two loss functions to jointly disentangle the latent representations into domainness-specific and domainness-invariant features, thus mitigating the intra-domain gap. Our method can be easily taken as a plug-and-play framework and does not introduce any extra costs in the inference time. We achieve consistent improvements over state-of-the-art methods in both object detection and semantic segmentation tasks.
Context-Aware Mixup for Domain Adaptive Semantic Segmentation
Aug 11, 2021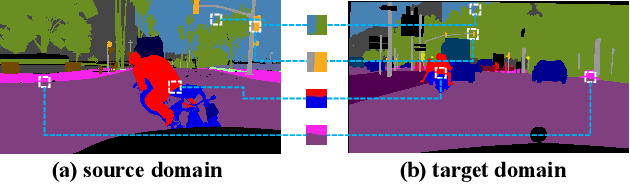
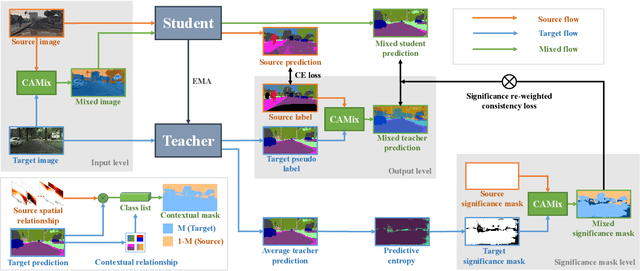

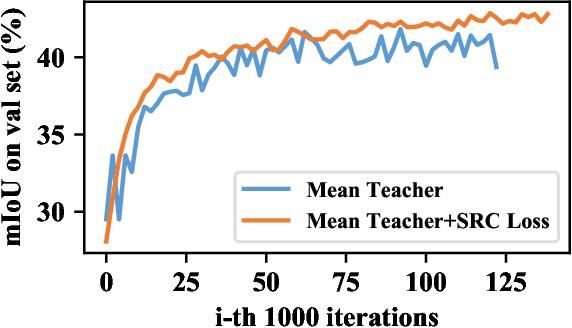
Unsupervised domain adaptation (UDA) aims to adapt a model of the labeled source domain to an unlabeled target domain. Although the domain shifts may exist in various dimensions such as appearance, textures, etc, the contextual dependency, which is generally shared across different domains, is neglected by recent methods. In this paper, we utilize this important clue as explicit prior knowledge and propose end-to-end Context-Aware Mixup (CAMix) for domain adaptive semantic segmentation. Firstly, we design a contextual mask generation strategy by leveraging accumulated spatial distributions and contextual relationships. The generated contextual mask is critical in this work and will guide the domain mixup. In addition, we define the significance mask to indicate where the pixels are credible. To alleviate the over-alignment (e.g., early performance degradation), the source and target significance masks are mixed based on the contextual mask into the mixed significance mask, and we introduce a significance-reweighted consistency loss on it. Experimental results show that the proposed method outperforms the state-of-the-art methods by a large margin on two widely-used domain adaptation benchmarks, i.e., GTAV $\rightarrow $ Cityscapes and SYNTHIA $\rightarrow $ Cityscapes.
Improving Video Instance Segmentation via Temporal Pyramid Routing
Jul 28, 2021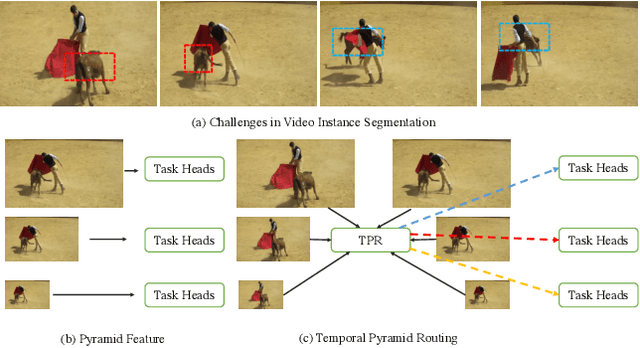
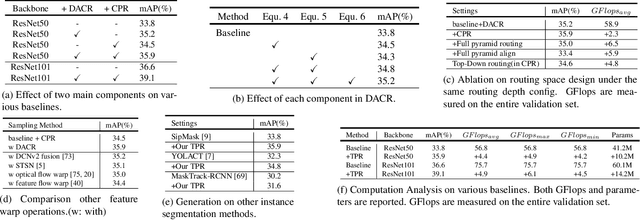
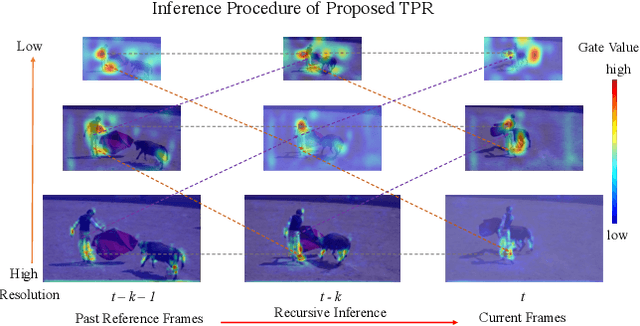
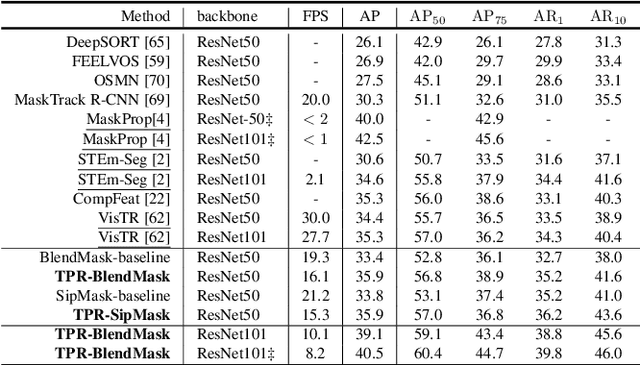
Video Instance Segmentation (VIS) is a new and inherently multi-task problem, which aims to detect, segment and track each instance in a video sequence. Existing approaches are mainly based on single-frame features or single-scale features of multiple frames, where temporal information or multi-scale information is ignored. To incorporate both temporal and scale information, we propose a Temporal Pyramid Routing (TPR) strategy to conditionally align and conduct pixel-level aggregation from a feature pyramid pair of two adjacent frames. Specifically, TPR contains two novel components, including Dynamic Aligned Cell Routing (DACR) and Cross Pyramid Routing (CPR), where DACR is designed for aligning and gating pyramid features across temporal dimension, while CPR transfers temporally aggregated features across scale dimension. Moreover, our approach is a plug-and-play module and can be easily applied to existing instance segmentation methods. Extensive experiments on YouTube-VIS dataset demonstrate the effectiveness and efficiency of the proposed approach on several state-of-the-art instance segmentation methods. Codes and trained models will be publicly available to facilitate future research.(\url{https://github.com/lxtGH/TemporalPyramidRouting}).