 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakerCard-1M: An Evidence-Grounded Speaker Card Corpus for In-the-Wild Speaker Verification
Jun 03, 2026Modern speaker verification (SV) systems rely on speaker embeddings that are effective but difficult to interpret or query in natural language. Most existing speech-text corpora target controllable synthesis or utterance-level captioning, and provide limited speaker-level supervision for in-the-wild speaker recognition. This paper introduces SpeakerCard-1M, a bilingual speaker-centric resource for evidence-grounded SV, derived from VoxCeleb1/2 and CN-Celeb1/2, where the "-1M" suffix refers to the 1.78M utterance-level captions contained in the release. We adopt a tool-first, LLM-last approach: ten acoustic probes produce field-level evidence, the evidence is aggregated into speaker profiles under a schema that separates relatively stable traits from utterance-level states, and bilingual Speaker Cards are rendered by a constrained LLM that sees only the structured fields. The release includes 56.7K Speaker Card records over 10.2K speakers, 1.78M utterance-level captions, and speaker-ID-disjoint hard-negative triplets. We further define two SV-oriented cross-modal protocols, bidirectional Speaker-Text Retrieval (T2S-R / S2T-R) and Attribute-Conditioned Verification (AC-Verify), and compare a dual-encoder baseline against recent audio language models under a zero-shot forced-choice setting. Joint audio-text training increases VoxCeleb1-O EER by 0.31% absolute over the audio-only baseline. Under a style-symmetric LLM-generated counterfactual protocol, eight recent audio language models (7B-30B+ parameters, both open- and closed-source) score 49-77% on pitch-level AC-Verify under two-way forced choice, compared with 88.66% reached by our dual encoder.
Learning to Collaborate via Structures: Cluster-Guided Item Alignment for Federated Recommendation
Feb 25, 2026Federated recommendation facilitates collaborative model training across distributed clients while keeping sensitive user interaction data local. Conventional approaches typically rely on synchronizing high-dimensional item representations between the server and clients. This paradigm implicitly assumes that precise geometric alignment of embedding coordinates is necessary for collaboration across clients. We posit that establishing relative semantic relationships among items is more effective than enforcing shared representations. Specifically, global semantic relations serve as structural constraints for items. Within these constraints, the framework allows item representations to vary locally on each client, which flexibility enables the model to capture fine-grained user personalization while maintaining global consistency. To this end, we propose Cluster-Guided FedRec framework (CGFedRec), a framework that transforms uploaded embeddings into compact cluster labels. In this framework, the server functions as a global structure discoverer to learn item clusters and distributes only the resulting labels. This mechanism explicitly cuts off the downstream transmission of item embeddings, relieving clients from maintaining global shared item embeddings. Consequently, CGFedRec achieves the effective injection of global collaborative signals into local item representations without transmitting full embeddings. Extensive experiments demonstrate that our approach significantly improves communication efficiency while maintaining superior recommendation accuracy across multiple datasets.
SocialMOIF: Multi-Order Intention Fusion for Pedestrian Trajectory Prediction
Apr 22, 2025The analysis and prediction of agent trajectories are crucial for decision-making processes in intelligent systems, with precise short-term trajectory forecasting being highly significant across a range of applications. Agents and their social interactions have been quantified and modeled by researchers from various perspectives; however, substantial limitations exist in the current work due to the inherent high uncertainty of agent intentions and the complex higher-order influences among neighboring groups. SocialMOIF is proposed to tackle these challenges, concentrating on the higher-order intention interactions among neighboring groups while reinforcing the primary role of first-order intention interactions between neighbors and the target agent. This method develops a multi-order intention fusion model to achieve a more comprehensive understanding of both direct and indirect intention information. Within SocialMOIF, a trajectory distribution approximator is designed to guide the trajectories toward values that align more closely with the actual data, thereby enhancing model interpretability. Furthermore, a global trajectory optimizer is introduced to enable more accurate and efficient parallel predictions. By incorporating a novel loss function that accounts for distance and direction during training, experimental results demonstrate that the model outperforms previous state-of-the-art baselines across multiple metrics in both dynamic and static datasets.
TacoDepth: Towards Efficient Radar-Camera Depth Estimation with One-stage Fusion
Apr 16, 2025



Radar-Camera depth estimation aims to predict dense and accurate metric depth by fusing input images and Radar data. Model efficiency is crucial for this task in pursuit of real-time processing on autonomous vehicles and robotic platforms. However, due to the sparsity of Radar returns, the prevailing methods adopt multi-stage frameworks with intermediate quasi-dense depth, which are time-consuming and not robust. To address these challenges, we propose TacoDepth, an efficient and accurate Radar-Camera depth estimation model with one-stage fusion. Specifically, the graph-based Radar structure extractor and the pyramid-based Radar fusion module are designed to capture and integrate the graph structures of Radar point clouds, delivering superior model efficiency and robustness without relying on the intermediate depth results. Moreover, TacoDepth can be flexible for different inference modes, providing a better balance of speed and accuracy. Extensive experiments are conducted to demonstrate the efficacy of our method. Compared with the previous state-of-the-art approach, TacoDepth improves depth accuracy and processing speed by 12.8% and 91.8%. Our work provides a new perspective on efficient Radar-Camera depth estimation.
SparseLIF: High-Performance Sparse LiDAR-Camera Fusion for 3D Object Detection
Mar 12, 2024Sparse 3D detectors have received significant attention since the query-based paradigm embraces low latency without explicit dense BEV feature construction. However, these detectors achieve worse performance than their dense counterparts. In this paper, we find the key to bridging the performance gap is to enhance the awareness of rich representations in two modalities. Here, we present a high-performance fully sparse detector for end-to-end multi-modality 3D object detection. The detector, termed SparseLIF, contains three key designs, which are (1) Perspective-Aware Query Generation (PAQG) to generate high-quality 3D queries with perspective priors, (2) RoI-Aware Sampling (RIAS) to further refine prior queries by sampling RoI features from each modality, (3) Uncertainty-Aware Fusion (UAF) to precisely quantify the uncertainty of each sensor modality and adaptively conduct final multi-modality fusion, thus achieving great robustness against sensor noises. By the time of submission (2024/03/08), SparseLIF achieves state-of-the-art performance on the nuScenes dataset, ranking 1st on both validation set and test benchmark, outperforming all state-of-the-art 3D object detectors by a notable margin. The source code will be released upon acceptance.
Rethinking Radiology Report Generation via Causal Reasoning and Counterfactual Augmentation
Dec 05, 2023



Radiology Report Generation (RRG) draws attention as an interaction between vision and language fields. Previous works inherited the ideology of vision-to-language generation tasks,aiming to generate paragraphs with high consistency as reports. However, one unique characteristic of RRG, the independence between diseases, was neglected, leading to the injection of disease co-occurrence as a confounder that effects the results through backdoor path. Unfortunately, this confounder confuses the process of report generation worse because of the biased RRG data distribution. In this paper, to rethink this issue thoroughly, we reason about its causes and effects from a novel perspective of statistics and causality, where the Joint Vision Coupling and the Conditional Sentence Coherence Coupling are two aspects prone to implicitly decrease the accuracy of reports. Then, a counterfactual augmentation strategy that contains the Counterfactual Sample Synthesis and the Counterfactual Report Reconstruction sub-methods is proposed to break these two aspects of spurious effects. Experimental results and further analyses on two widely used datasets justify our reasoning and proposed methods.
Filter and evolve: progressive pseudo label refining for semi-supervised automatic speech recognition
Oct 28, 2022



Fine tuning self supervised pretrained models using pseudo labels can effectively improve speech recognition performance. But, low quality pseudo labels can misguide decision boundaries and degrade performance. We propose a simple yet effective strategy to filter low quality pseudo labels to alleviate this problem. Specifically, pseudo-labels are produced over the entire training set and filtered via average probability scores calculated from the model output. Subsequently, an optimal percentage of utterances with high probability scores are considered reliable training data with trustworthy labels. The model is iteratively updated to correct the unreliable pseudo labels to minimize the effect of noisy labels. The process above is repeated until unreliable pseudo abels have been adequately corrected. Extensive experiments on LibriSpeech show that these filtered samples enable the refined model to yield more correct predictions, leading to better ASR performances under various experimental settings.
AdaStereo: An Efficient Domain-Adaptive Stereo Matching Approach
Dec 09, 2021
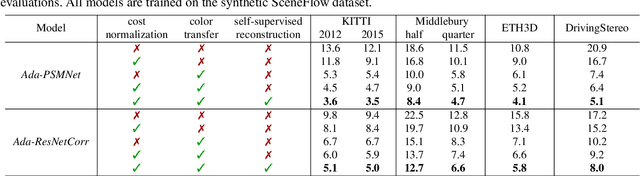
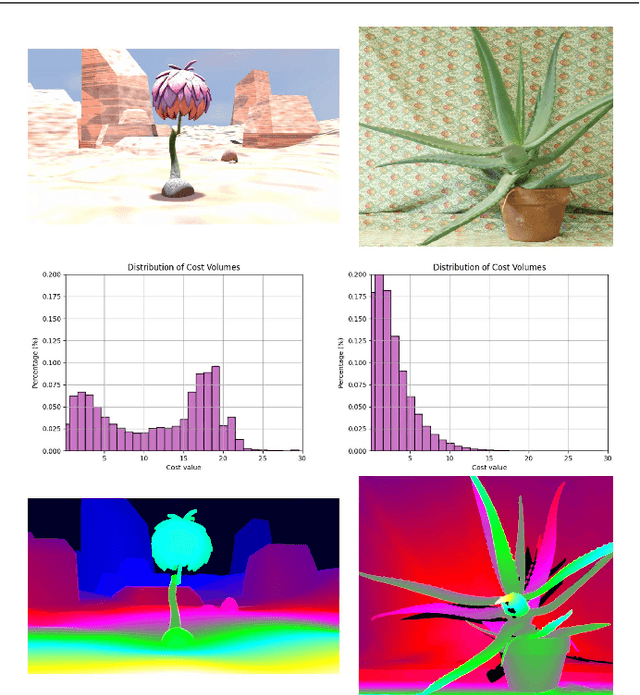
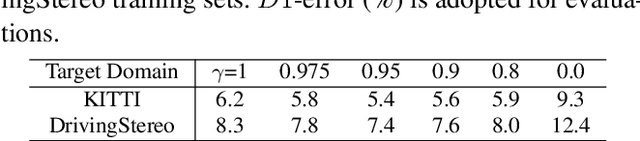
Recently, records on stereo matching benchmarks are constantly broken by end-to-end disparity networks. However, the domain adaptation ability of these deep models is quite limited. Addressing such problem, we present a novel domain-adaptive approach called AdaStereo that aims to align multi-level representations for deep stereo matching networks. Compared to previous methods, our AdaStereo realizes a more standard, complete and effective domain adaptation pipeline. Firstly, we propose a non-adversarial progressive color transfer algorithm for input image-level alignment. Secondly, we design an efficient parameter-free cost normalization layer for internal feature-level alignment. Lastly, a highly related auxiliary task, self-supervised occlusion-aware reconstruction is presented to narrow the gaps in output space. We perform intensive ablation studies and break-down comparisons to validate the effectiveness of each proposed module. With no extra inference overhead and only a slight increase in training complexity, our AdaStereo models achieve state-of-the-art cross-domain performance on multiple benchmarks, including KITTI, Middlebury, ETH3D and DrivingStereo, even outperforming some state-of-the-art disparity networks finetuned with target-domain ground-truths. Moreover, based on two additional evaluation metrics, the superiority of our domain-adaptive stereo matching pipeline is further uncovered from more perspectives. Finally, we demonstrate that our method is robust to various domain adaptation settings, and can be easily integrated into quick adaptation application scenarios and real-world deployments.
LIF-Seg: LiDAR and Camera Image Fusion for 3D LiDAR Semantic Segmentation
Aug 17, 2021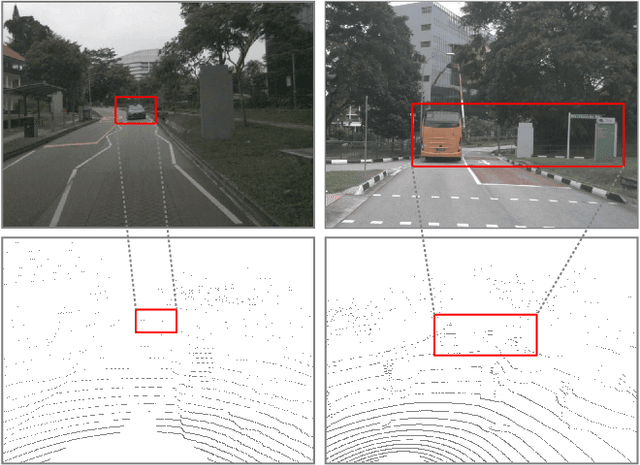

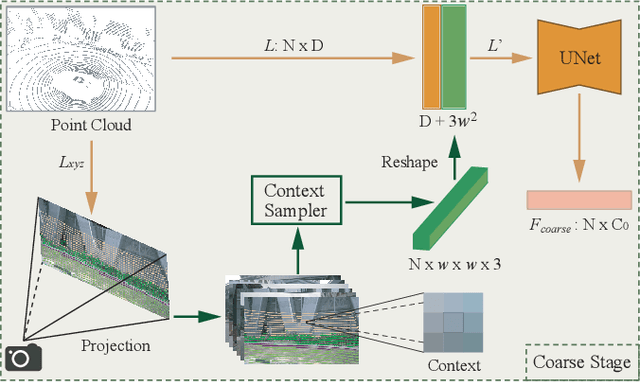
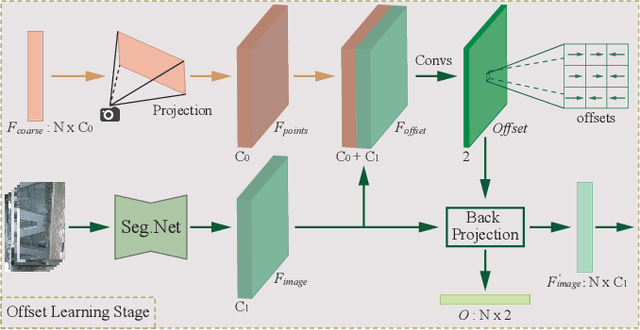
Camera and 3D LiDAR sensors have become indispensable devices in modern autonomous driving vehicles, where the camera provides the fine-grained texture, color information in 2D space and LiDAR captures more precise and farther-away distance measurements of the surrounding environments. The complementary information from these two sensors makes the two-modality fusion be a desired option. However, two major issues of the fusion between camera and LiDAR hinder its performance, \ie, how to effectively fuse these two modalities and how to precisely align them (suffering from the weak spatiotemporal synchronization problem). In this paper, we propose a coarse-to-fine LiDAR and camera fusion-based network (termed as LIF-Seg) for LiDAR segmentation. For the first issue, unlike these previous works fusing the point cloud and image information in a one-to-one manner, the proposed method fully utilizes the contextual information of images and introduces a simple but effective early-fusion strategy. Second, due to the weak spatiotemporal synchronization problem, an offset rectification approach is designed to align these two-modality features. The cooperation of these two components leads to the success of the effective camera-LiDAR fusion. Experimental results on the nuScenes dataset show the superiority of the proposed LIF-Seg over existing methods with a large margin. Ablation studies and analyses demonstrate that our proposed LIF-Seg can effectively tackle the weak spatiotemporal synchronization problem.
Temporal-Channel Transformer for 3D Lidar-Based Video Object Detection in Autonomous Driving
Nov 27, 2020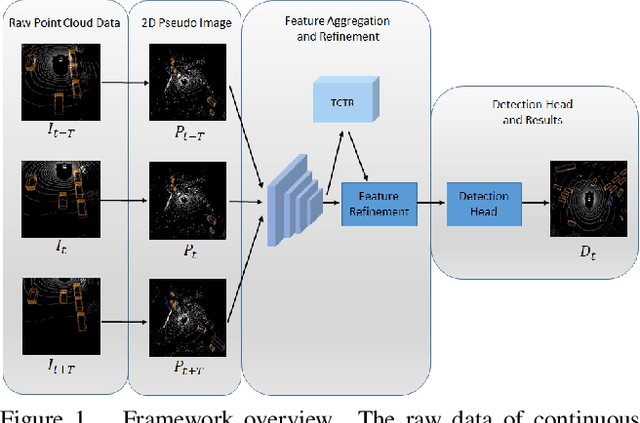
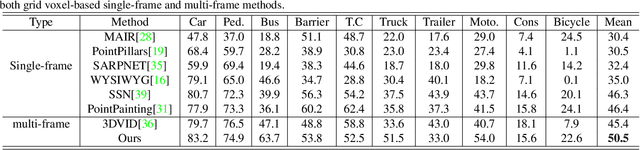
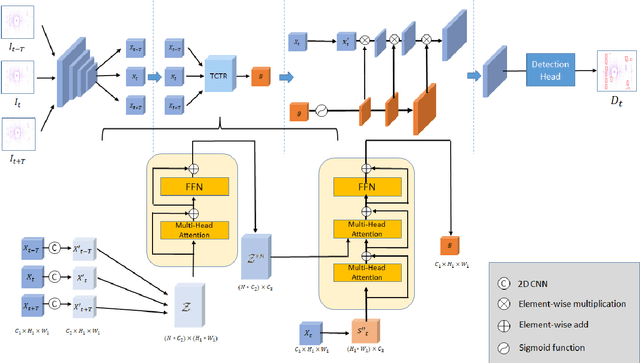
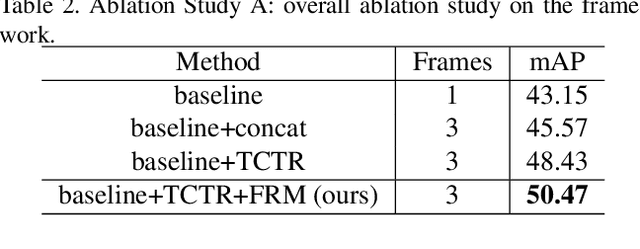
The strong demand of autonomous driving in the industry has lead to strong interest in 3D object detection and resulted in many excellent 3D object detection algorithms. However, the vast majority of algorithms only model single-frame data, ignoring the temporal information of the sequence of data. In this work, we propose a new transformer, called Temporal-Channel Transformer, to model the spatial-temporal domain and channel domain relationships for video object detecting from Lidar data. As a special design of this transformer, the information encoded in the encoder is different from that in the decoder, i.e. the encoder encodes temporal-channel information of multiple frames while the decoder decodes the spatial-channel information for the current frame in a voxel-wise manner. Specifically, the temporal-channel encoder of the transformer is designed to encode the information of different channels and frames by utilizing the correlation among features from different channels and frames. On the other hand, the spatial decoder of the transformer will decode the information for each location of the current frame. Before conducting the object detection with detection head, the gate mechanism is deployed for re-calibrating the features of current frame, which filters out the object irrelevant information by repetitively refine the representation of target frame along with the up-sampling process. Experimental results show that we achieve the state-of-the-art performance in grid voxel-based 3D object detection on the nuScenes benchmark.