 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMajorization-Guided Test-Time Adaptation for Vision-Language Models under Modality-Specific Shift
Apr 27, 2026Vision-language models transfer well in zero-shot settings, but at deployment the visual and textual branches often shift asymmetrically. Under this condition, entropy-based test-time adaptation can sharpen the fused posterior while increasing error, because an unreliable modality may still dominate fusion. We study this failure mode through a majorization view of multimodal posteriors and cast adaptation as a constrained de-mixing problem on the fused prediction. Based on this view, we propose MG-MTTA, which keeps the backbone frozen and updates only a lightweight gate or adapter. The objective combines fused-posterior entropy minimization with a reliability-aware gate prior built from anchor-based modality consistency and cross-modal conflict. Our analysis gives conditions under which entropy reduction preserves the correct ranking and a threshold that characterizes modality-dominance failure. On the ImageNet-based benchmark, MG-MTTA improves top-1 accuracy from 57.97 to 66.51 under semantics-preserving textual shift and from 21.68 to 26.27 under joint visual-textual shift, while remaining competitive in the visual-only benchmark. These results show that multimodal test-time adaptation should control modality reliability, not just prediction entropy.
TransSplat: Unbalanced Semantic Transport for Language-Driven 3DGS Editing
Apr 21, 2026Language-driven 3D Gaussian Splatting (3DGS) editing provides a more convenient approach for modifying complex scenes in VR/AR. Standard pipelines typically adopt a two-stage strategy: first editing multiple 2D views, and then optimizing the 3D representation to match these edited observations. Existing methods mainly improve view consistency through multi-view feature fusion, attention filtering, or iterative recalibration. However, they fail to explicitly address a more fundamental issue: the semantic correspondence between edited 2D evidence and 3D Gaussians. To tackle this problem, we propose TransSplat, which formulates language-driven 3DGS editing as a multi-view unbalanced semantic transport problem. Specifically, our method establishes correspondences between visible Gaussians and view-specific editing prototypes, thereby explicitly characterizing the semantic relationship between edited 2D evidence and 3D Gaussians. It further recovers a cross-view shared canonical 3D edit field to guide unified 3D appearance updates. In addition, we use transport residuals to suppress erroneous edits in non-target regions, mitigating edit leakage and improving local control precision. Qualitative and quantitative results show that, compared with existing 3D editing methods centered on enhancing view consistency, TransSplat achieves superior performance in local editing accuracy and structural consistency.
3DAffordSplat: Efficient Affordance Reasoning with 3D Gaussians
Apr 16, 20253D affordance reasoning is essential in associating human instructions with the functional regions of 3D objects, facilitating precise, task-oriented manipulations in embodied AI. However, current methods, which predominantly depend on sparse 3D point clouds, exhibit limited generalizability and robustness due to their sensitivity to coordinate variations and the inherent sparsity of the data. By contrast, 3D Gaussian Splatting (3DGS) delivers high-fidelity, real-time rendering with minimal computational overhead by representing scenes as dense, continuous distributions. This positions 3DGS as a highly effective approach for capturing fine-grained affordance details and improving recognition accuracy. Nevertheless, its full potential remains largely untapped due to the absence of large-scale, 3DGS-specific affordance datasets. To overcome these limitations, we present 3DAffordSplat, the first large-scale, multi-modal dataset tailored for 3DGS-based affordance reasoning. This dataset includes 23,677 Gaussian instances, 8,354 point cloud instances, and 6,631 manually annotated affordance labels, encompassing 21 object categories and 18 affordance types. Building upon this dataset, we introduce AffordSplatNet, a novel model specifically designed for affordance reasoning using 3DGS representations. AffordSplatNet features an innovative cross-modal structure alignment module that exploits structural consistency priors to align 3D point cloud and 3DGS representations, resulting in enhanced affordance recognition accuracy. Extensive experiments demonstrate that the 3DAffordSplat dataset significantly advances affordance learning within the 3DGS domain, while AffordSplatNet consistently outperforms existing methods across both seen and unseen settings, highlighting its robust generalization capabilities.
Aligning Cyber Space with Physical World: A Comprehensive Survey on Embodied AI
Jul 09, 2024



Embodied Artificial Intelligence (Embodied AI) is crucial for achieving Artificial General Intelligence (AGI) and serves as a foundation for various applications that bridge cyberspace and the physical world. Recently, the emergence of Multi-modal Large Models (MLMs) and World Models (WMs) have attracted significant attention due to their remarkable perception, interaction, and reasoning capabilities, making them a promising architecture for the brain of embodied agents. However, there is no comprehensive survey for Embodied AI in the era of MLMs. In this survey, we give a comprehensive exploration of the latest advancements in Embodied AI. Our analysis firstly navigates through the forefront of representative works of embodied robots and simulators, to fully understand the research focuses and their limitations. Then, we analyze four main research targets: 1) embodied perception, 2) embodied interaction, 3) embodied agent, and 4) sim-to-real adaptation, covering the state-of-the-art methods, essential paradigms, and comprehensive datasets. Additionally, we explore the complexities of MLMs in virtual and real embodied agents, highlighting their significance in facilitating interactions in dynamic digital and physical environments. Finally, we summarize the challenges and limitations of embodied AI and discuss their potential future directions. We hope this survey will serve as a foundational reference for the research community and inspire continued innovation. The associated project can be found at https://github.com/HCPLab-SYSU/Embodied_AI_Paper_List.
Robust Self-Supervised LiDAR Odometry via Representative Structure Discovery and 3D Inherent Error Modeling
Feb 27, 2022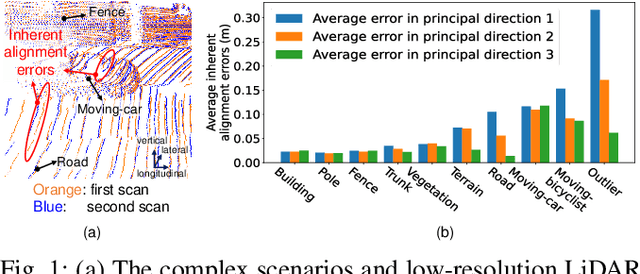
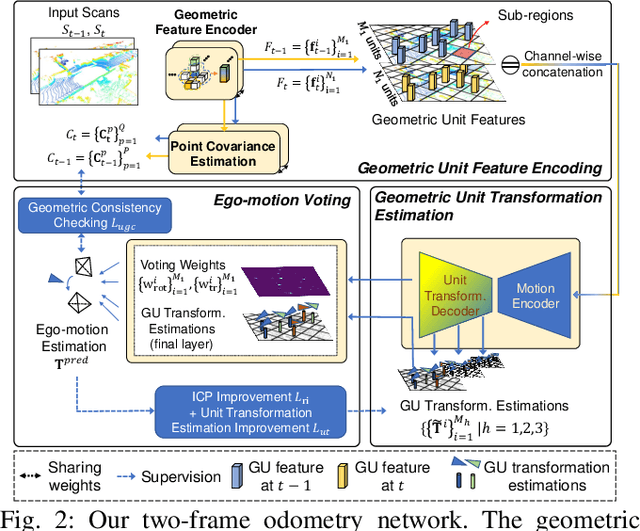

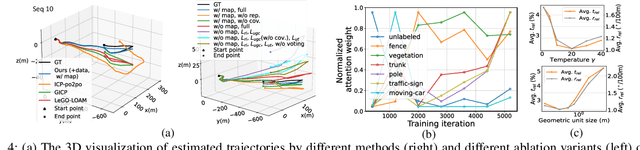
The correct ego-motion estimation basically relies on the understanding of correspondences between adjacent LiDAR scans. However, given the complex scenarios and the low-resolution LiDAR, finding reliable structures for identifying correspondences can be challenging. In this paper, we delve into structure reliability for accurate self-supervised ego-motion estimation and aim to alleviate the influence of unreliable structures in training, inference and mapping phases. We improve the self-supervised LiDAR odometry substantially from three aspects: 1) A two-stage odometry estimation network is developed, where we obtain the ego-motion by estimating a set of sub-region transformations and averaging them with a motion voting mechanism, to encourage the network focusing on representative structures. 2) The inherent alignment errors, which cannot be eliminated via ego-motion optimization, are down-weighted in losses based on the 3D point covariance estimations. 3) The discovered representative structures and learned point covariances are incorporated in the mapping module to improve the robustness of map construction. Our two-frame odometry outperforms the previous state of the arts by 16%/12% in terms of translational/rotational errors on the KITTI dataset and performs consistently well on the Apollo-Southbay datasets. We can even rival the fully supervised counterparts with our mapping module and more unlabeled training data.