 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSF-GNN: Self Filter for Message Lossless Propagation in Deep Graph Neural Network
Jul 03, 2024



Graph Neural Network (GNN), with the main idea of encoding graph structure information of graphs by propagation and aggregation, has developed rapidly. It achieved excellent performance in representation learning of multiple types of graphs such as homogeneous graphs, heterogeneous graphs, and more complex graphs like knowledge graphs. However, merely stacking GNN layers may not improve the model's performance and can even be detrimental. For the phenomenon of performance degradation in deep GNNs, we propose a new perspective. Unlike the popular explanations of over-smoothing or over-squashing, we think the issue arises from the interference of low-quality node representations during message propagation. We introduce a simple and general method, SF-GNN, to address this problem. In SF-GNN, we define two representations for each node, one is the node representation that represents the feature of the node itself, and the other is the message representation specifically for propagating messages to neighbor nodes. A self-filter module evaluates the quality of the node representation and decides whether to integrate it into the message propagation based on this quality assessment. Experiments on node classification tasks for both homogeneous and heterogeneous graphs, as well as link prediction tasks on knowledge graphs, demonstrate that our method can be applied to various GNN models and outperforms state-of-the-art baseline methods in addressing deep GNN degradation.
To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models
Jul 02, 2024
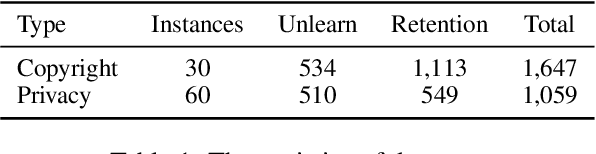
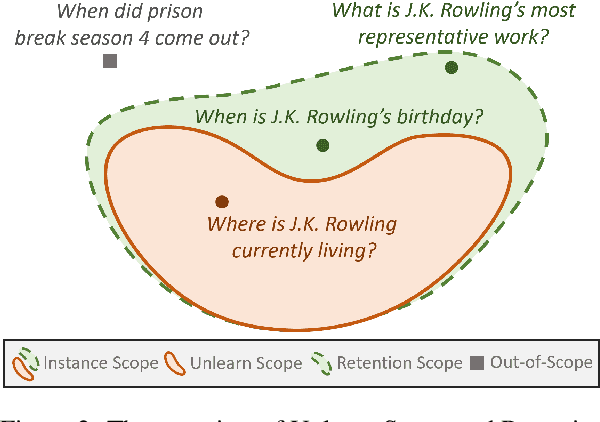
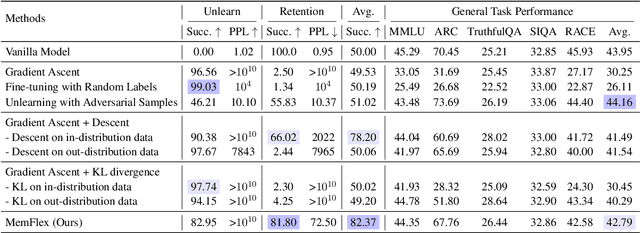
Large Language Models (LLMs) trained on extensive corpora inevitably retain sensitive data, such as personal privacy information and copyrighted material. Recent advancements in knowledge unlearning involve updating LLM parameters to erase specific knowledge. However, current unlearning paradigms are mired in vague forgetting boundaries, often erasing knowledge indiscriminately. In this work, we introduce KnowUnDo, a benchmark containing copyrighted content and user privacy domains to evaluate if the unlearning process inadvertently erases essential knowledge. Our findings indicate that existing unlearning methods often suffer from excessive unlearning. To address this, we propose a simple yet effective method, MemFlex, which utilizes gradient information to precisely target and unlearn sensitive parameters. Experimental results show that MemFlex is superior to existing methods in both precise knowledge unlearning and general knowledge retaining of LLMs. Code and dataset will be released at https://github.com/zjunlp/KnowUnDo.
TrustUQA: A Trustful Framework for Unified Structured Data Question Answering
Jun 27, 2024



Natural language question answering (QA) over structured data sources such as tables and knowledge graphs (KGs) have been widely investigated, for example with Large Language Models (LLMs). The main solutions include question to formal query parsing and retrieval-based answer generation. However, current methods of the former often suffer from weak generalization, failing to dealing with multiple sources simultaneously, while the later is limited in trustfulness. In this paper, we propose UnifiedTQA, a trustful QA framework that can simultaneously support multiple types of structured data in a unified way. To this end, it adopts an LLM-friendly and unified knowledge representation method called Condition Graph (CG), and uses an LLM and demonstration-based two-level method for CG querying. For enhancement, it is also equipped with dynamic demonstration retrieval. We have evaluated UnifiedTQA with 5 benchmarks covering 3 types of structured data. It outperforms 2 existing unified structured data QA methods and in comparison with the baselines that are specific to a data type, it achieves state-of-the-art on 2 of them. Further more, we demonstrates potential of our method for more general QA tasks, QA over mixed structured data and QA across structured data.
Symbolic Learning Enables Self-Evolving Agents
Jun 26, 2024



The AI community has been exploring a pathway to artificial general intelligence (AGI) by developing "language agents", which are complex large language models (LLMs) pipelines involving both prompting techniques and tool usage methods. While language agents have demonstrated impressive capabilities for many real-world tasks, a fundamental limitation of current language agents research is that they are model-centric, or engineering-centric. That's to say, the progress on prompts, tools, and pipelines of language agents requires substantial manual engineering efforts from human experts rather than automatically learning from data. We believe the transition from model-centric, or engineering-centric, to data-centric, i.e., the ability of language agents to autonomously learn and evolve in environments, is the key for them to possibly achieve AGI. In this work, we introduce agent symbolic learning, a systematic framework that enables language agents to optimize themselves on their own in a data-centric way using symbolic optimizers. Specifically, we consider agents as symbolic networks where learnable weights are defined by prompts, tools, and the way they are stacked together. Agent symbolic learning is designed to optimize the symbolic network within language agents by mimicking two fundamental algorithms in connectionist learning: back-propagation and gradient descent. Instead of dealing with numeric weights, agent symbolic learning works with natural language simulacrums of weights, loss, and gradients. We conduct proof-of-concept experiments on both standard benchmarks and complex real-world tasks and show that agent symbolic learning enables language agents to update themselves after being created and deployed in the wild, resulting in "self-evolving agents".
Start from Zero: Triple Set Prediction for Automatic Knowledge Graph Completion
Jun 26, 2024



Knowledge graph (KG) completion aims to find out missing triples in a KG. Some tasks, such as link prediction and instance completion, have been proposed for KG completion. They are triple-level tasks with some elements in a missing triple given to predict the missing element of the triple. However, knowing some elements of the missing triple in advance is not always a realistic setting. In this paper, we propose a novel graph-level automatic KG completion task called Triple Set Prediction (TSP) which assumes none of the elements in the missing triples is given. TSP is to predict a set of missing triples given a set of known triples. To properly and accurately evaluate this new task, we propose 4 evaluation metrics including 3 classification metrics and 1 ranking metric, considering both the partial-open-world and the closed-world assumptions. Furthermore, to tackle the huge candidate triples for prediction, we propose a novel and efficient subgraph-based method GPHT that can predict the triple set fast. To fairly compare the TSP results, we also propose two types of methods RuleTensor-TSP and KGE-TSP applying the existing rule- and embedding-based methods for TSP as baselines. During experiments, we evaluate the proposed methods on two datasets extracted from Wikidata following the relation-similarity partial-open-world assumption proposed by us, and also create a complete family data set to evaluate TSP results following the closed-world assumption. Results prove that the methods can successfully generate a set of missing triples and achieve reasonable scores on the new task, and GPHT performs better than the baselines with significantly shorter prediction time. The datasets and code for experiments are available at https://github.com/zjukg/GPHT-for-TSP.
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Jun 20, 2024



Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
InstructRL4Pix: Training Diffusion for Image Editing by Reinforcement Learning
Jun 14, 2024Instruction-based image editing has made a great process in using natural human language to manipulate the visual content of images. However, existing models are limited by the quality of the dataset and cannot accurately localize editing regions in images with complex object relationships. In this paper, we propose Reinforcement Learning Guided Image Editing Method(InstructRL4Pix) to train a diffusion model to generate images that are guided by the attention maps of the target object. Our method maximizes the output of the reward model by calculating the distance between attention maps as a reward function and fine-tuning the diffusion model using proximal policy optimization (PPO). We evaluate our model in object insertion, removal, replacement, and transformation. Experimental results show that InstructRL4Pix breaks through the limitations of traditional datasets and uses unsupervised learning to optimize editing goals and achieve accurate image editing based on natural human commands.
SciKnowEval: Evaluating Multi-level Scientific Knowledge of Large Language Models
Jun 13, 2024The burgeoning utilization of Large Language Models (LLMs) in scientific research necessitates advanced benchmarks capable of evaluating their understanding and application of scientific knowledge comprehensively. To address this need, we introduce the SciKnowEval benchmark, a novel framework that systematically evaluates LLMs across five progressive levels of scientific knowledge: studying extensively, inquiring earnestly, thinking profoundly, discerning clearly, and practicing assiduously. These levels aim to assess the breadth and depth of scientific knowledge in LLMs, including knowledge coverage, inquiry and exploration capabilities, reflection and reasoning abilities, ethic and safety considerations, as well as practice proficiency. Specifically, we take biology and chemistry as the two instances of SciKnowEval and construct a dataset encompassing 50K multi-level scientific problems and solutions. By leveraging this dataset, we benchmark 20 leading open-source and proprietary LLMs using zero-shot and few-shot prompting strategies. The results reveal that despite achieving state-of-the-art performance, the proprietary LLMs still have considerable room for improvement, particularly in addressing scientific computations and applications. We anticipate that SciKnowEval will establish a comprehensive standard for benchmarking LLMs in science research and discovery, and promote the development of LLMs that integrate scientific knowledge with strong safety awareness. The dataset and code are publicly available at https://github.com/hicai-zju/sciknoweval .
Knowledge Circuits in Pretrained Transformers
May 28, 2024



The remarkable capabilities of modern large language models are rooted in their vast repositories of knowledge encoded within their parameters, enabling them to perceive the world and engage in reasoning. The inner workings of how these models store knowledge have long been a subject of intense interest and investigation among researchers. To date, most studies have concentrated on isolated components within these models, such as the Multilayer Perceptrons and attention head. In this paper, we delve into the computation graph of the language model to uncover the knowledge circuits that are instrumental in articulating specific knowledge. The experiments, conducted with GPT2 and TinyLLAMA, has allowed us to observe how certain information heads, relation heads, and Multilayer Perceptrons collaboratively encode knowledge within the model. Moreover, we evaluate the impact of current knowledge editing techniques on these knowledge circuits, providing deeper insights into the functioning and constraints of these editing methodologies. Finally, we utilize knowledge circuits to analyze and interpret language model behaviors such as hallucinations and in-context learning. We believe the knowledge circuit holds potential for advancing our understanding of Transformers and guiding the improved design of knowledge editing. Code and data are available in https://github.com/zjunlp/KnowledgeCircuits.
Mixture of Modality Knowledge Experts for Robust Multi-modal Knowledge Graph Completion
May 27, 2024Multi-modal knowledge graph completion (MMKGC) aims to automatically discover new knowledge triples in the given multi-modal knowledge graphs (MMKGs), which is achieved by collaborative modeling the structural information concealed in massive triples and the multi-modal features of the entities. Existing methods tend to focus on crafting elegant entity-wise multi-modal fusion strategies, yet they overlook the utilization of multi-perspective features concealed within the modalities under diverse relational contexts. To address this issue, we introduce a novel MMKGC framework with Mixture of Modality Knowledge experts (MoMoK for short) to learn adaptive multi-modal embedding under intricate relational contexts. We design relation-guided modality knowledge experts to acquire relation-aware modality embeddings and integrate the predictions from multi-modalities to achieve comprehensive decisions. Additionally, we disentangle the experts by minimizing their mutual information. Experiments on four public MMKG benchmarks demonstrate the outstanding performance of MoMoK under complex scenarios.