 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStart from Zero: Triple Set Prediction for Automatic Knowledge Graph Completion
Jun 26, 2024



Knowledge graph (KG) completion aims to find out missing triples in a KG. Some tasks, such as link prediction and instance completion, have been proposed for KG completion. They are triple-level tasks with some elements in a missing triple given to predict the missing element of the triple. However, knowing some elements of the missing triple in advance is not always a realistic setting. In this paper, we propose a novel graph-level automatic KG completion task called Triple Set Prediction (TSP) which assumes none of the elements in the missing triples is given. TSP is to predict a set of missing triples given a set of known triples. To properly and accurately evaluate this new task, we propose 4 evaluation metrics including 3 classification metrics and 1 ranking metric, considering both the partial-open-world and the closed-world assumptions. Furthermore, to tackle the huge candidate triples for prediction, we propose a novel and efficient subgraph-based method GPHT that can predict the triple set fast. To fairly compare the TSP results, we also propose two types of methods RuleTensor-TSP and KGE-TSP applying the existing rule- and embedding-based methods for TSP as baselines. During experiments, we evaluate the proposed methods on two datasets extracted from Wikidata following the relation-similarity partial-open-world assumption proposed by us, and also create a complete family data set to evaluate TSP results following the closed-world assumption. Results prove that the methods can successfully generate a set of missing triples and achieve reasonable scores on the new task, and GPHT performs better than the baselines with significantly shorter prediction time. The datasets and code for experiments are available at https://github.com/zjukg/GPHT-for-TSP.
Prompt-fused framework for Inductive Logical Query Answering
Mar 19, 2024



Answering logical queries on knowledge graphs (KG) poses a significant challenge for machine reasoning. The primary obstacle in this task stems from the inherent incompleteness of KGs. Existing research has predominantly focused on addressing the issue of missing edges in KGs, thereby neglecting another aspect of incompleteness: the emergence of new entities. Furthermore, most of the existing methods tend to reason over each logical operator separately, rather than comprehensively analyzing the query as a whole during the reasoning process. In this paper, we propose a query-aware prompt-fused framework named Pro-QE, which could incorporate existing query embedding methods and address the embedding of emerging entities through contextual information aggregation. Additionally, a query prompt, which is generated by encoding the symbolic query, is introduced to gather information relevant to the query from a holistic perspective. To evaluate the efficacy of our model in the inductive setting, we introduce two new challenging benchmarks. Experimental results demonstrate that our model successfully handles the issue of unseen entities in logical queries. Furthermore, the ablation study confirms the efficacy of the aggregator and prompt components.
InBox: Recommendation with Knowledge Graph using Interest Box Embedding
Mar 19, 2024



Knowledge graphs (KGs) have become vitally important in modern recommender systems, effectively improving performance and interpretability. Fundamentally, recommender systems aim to identify user interests based on historical interactions and recommend suitable items. However, existing works overlook two key challenges: (1) an interest corresponds to a potentially large set of related items, and (2) the lack of explicit, fine-grained exploitation of KG information and interest connectivity. This leads to an inability to reflect distinctions between entities and interests when modeling them in a single way. Additionally, the granularity of concepts in the knowledge graphs used for recommendations tends to be coarse, failing to match the fine-grained nature of user interests. This homogenization limits the precise exploitation of knowledge graph data and interest connectivity. To address these limitations, we introduce a novel embedding-based model called InBox. Specifically, various knowledge graph entities and relations are embedded as points or boxes, while user interests are modeled as boxes encompassing interaction history. Representing interests as boxes enables containing collections of item points related to that interest. We further propose that an interest comprises diverse basic concepts, and box intersection naturally supports concept combination. Across three training steps, InBox significantly outperforms state-of-the-art methods like HAKG and KGIN on recommendation tasks. Further analysis provides meaningful insights into the variable value of different KG data for recommendations. In summary, InBox advances recommender systems through box-based interest and concept modeling for sophisticated knowledge graph exploitation.
Generalizing to Unseen Elements: A Survey on Knowledge Extrapolation for Knowledge Graphs
Feb 03, 2023


Knowledge graphs (KGs) have become effective knowledge resources in diverse applications, and knowledge graph embedding (KGE) methods have attracted increasing attention in recent years. However, it's still challenging for conventional KGE methods to handle unseen entities or relations during the model test. Much effort has been made in various fields of KGs to address this problem. In this paper, we use a set of general terminologies to unify these methods and refer to them as Knowledge Extrapolation. We comprehensively summarize these methods classified by our proposed taxonomy and describe their correlations. Next, we introduce the benchmarks and provide comparisons of these methods from aspects that are not reflected by the taxonomy. Finally, we suggest some potential directions for future research.
Neural-Symbolic Entangled Framework for Complex Query Answering
Sep 19, 2022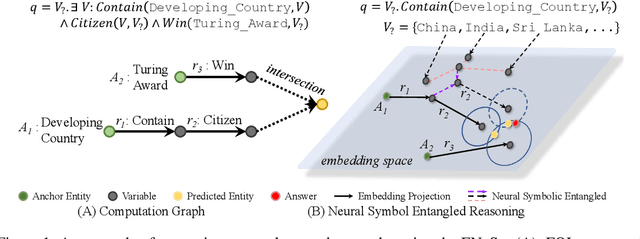
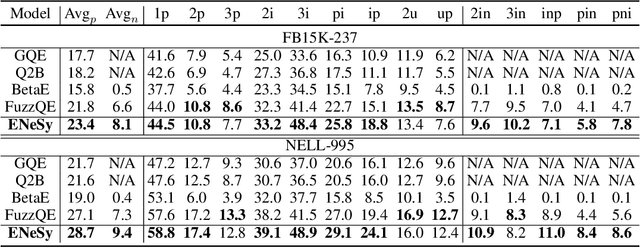
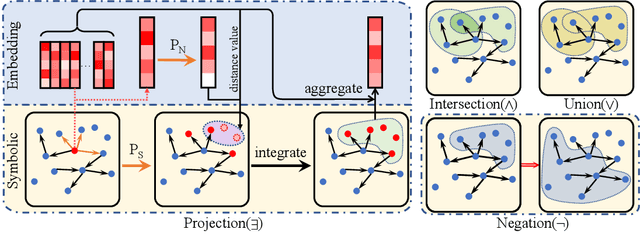
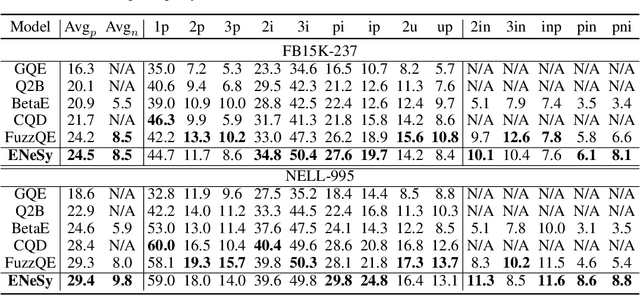
Answering complex queries over knowledge graphs (KG) is an important yet challenging task because of the KG incompleteness issue and cascading errors during reasoning. Recent query embedding (QE) approaches to embed the entities and relations in a KG and the first-order logic (FOL) queries into a low dimensional space, answering queries by dense similarity search. However, previous works mainly concentrate on the target answers, ignoring intermediate entities' usefulness, which is essential for relieving the cascading error problem in logical query answering. In addition, these methods are usually designed with their own geometric or distributional embeddings to handle logical operators like union, intersection, and negation, with the sacrifice of the accuracy of the basic operator - projection, and they could not absorb other embedding methods to their models. In this work, we propose a Neural and Symbolic Entangled framework (ENeSy) for complex query answering, which enables the neural and symbolic reasoning to enhance each other to alleviate the cascading error and KG incompleteness. The projection operator in ENeSy could be any embedding method with the capability of link prediction, and the other FOL operators are handled without parameters. With both neural and symbolic reasoning results contained, ENeSy answers queries in ensembles. ENeSy achieves the SOTA performance on several benchmarks, especially in the setting of the training model only with the link prediction task.
Commonsense Knowledge Salience Evaluation with a Benchmark Dataset in E-commerce
May 22, 2022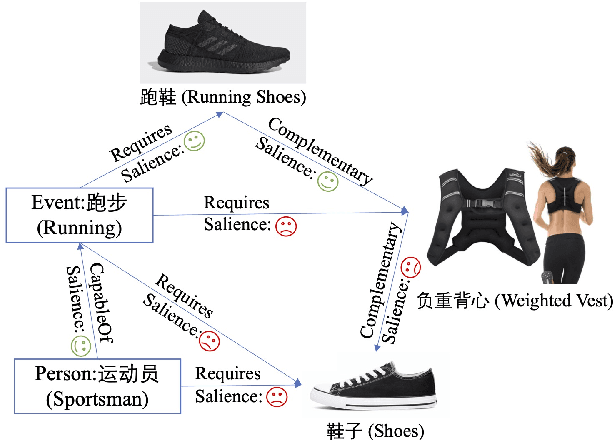


In e-commerce, the salience of commonsense knowledge (CSK) is beneficial for widespread applications such as product search and recommendation. For example, when users search for "running" in e-commerce, they would like to find items highly related to running, such as "running shoes" rather than "shoes". However, many existing CSK collections rank statements solely by confidence scores, and there is no information about which ones are salient from a human perspective. In this work, we define the task of supervised salience evaluation, where given a CSK triple, the model is required to learn whether the triple is salient or not. In addition to formulating the new task, we also release a new Benchmark dataset of Salience Evaluation in E-commerce (BSEE) and hope to promote related research on commonsense knowledge salience evaluation. We conduct experiments in the dataset with several representative baseline models. The experimental results show that salience evaluation is a hard task where models perform poorly on our evaluation set. We further propose a simple but effective approach, PMI-tuning, which shows promise for solving this novel problem.
NeuralKG: An Open Source Library for Diverse Representation Learning of Knowledge Graphs
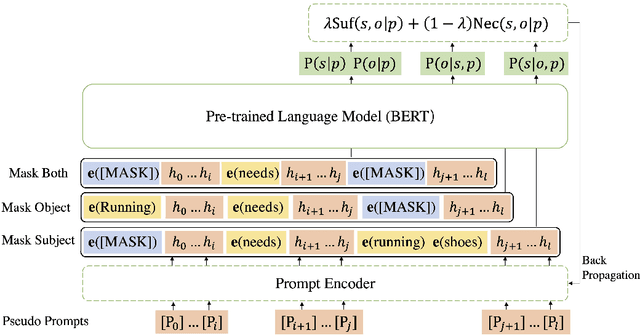
Feb 25, 2022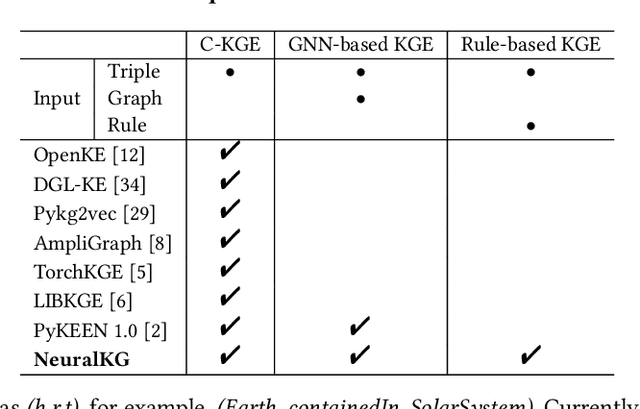
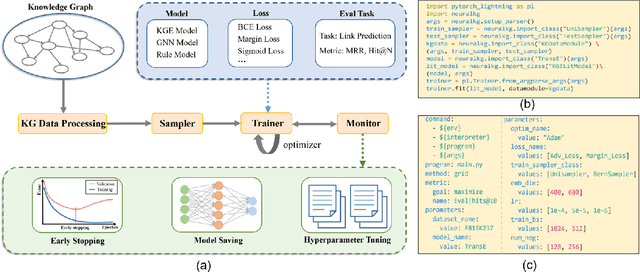
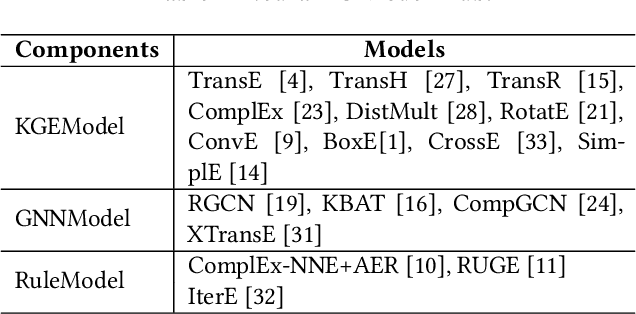
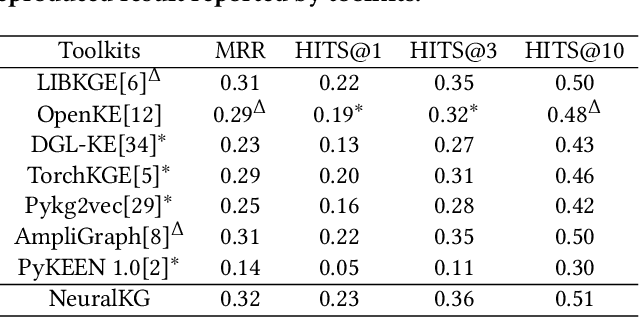
NeuralKG is an open-source Python-based library for diverse representation learning of knowledge graphs. It implements three different series of Knowledge Graph Embedding (KGE) methods, including conventional KGEs, GNN-based KGEs, and Rule-based KGEs. With a unified framework, NeuralKG successfully reproduces link prediction results of these methods on benchmarks, freeing users from the laborious task of reimplementing them, especially for some methods originally written in non-python programming languages. Besides, NeuralKG is highly configurable and extensible. It provides various decoupled modules that can be mixed and adapted to each other. Thus with NeuralKG, developers and researchers can quickly implement their own designed models and obtain the optimal training methods to achieve the best performance efficiently. We built an website in http://neuralkg.zjukg.cn to organize an open and shared KG representation learning community. The source code is all publicly released at https://github.com/zjukg/NeuralKG.
Knowledge Graph Reasoning with Logics and Embeddings: Survey and Perspective
Feb 15, 2022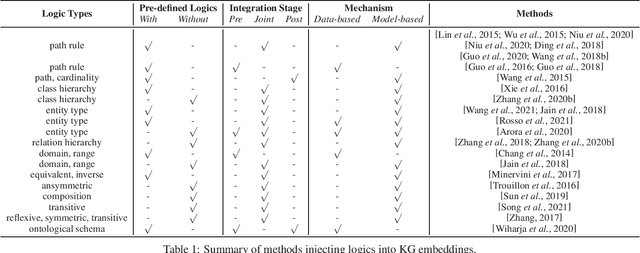
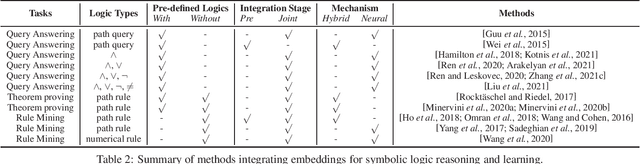
Knowledge graph (KG) reasoning is becoming increasingly popular in both academia and industry. Conventional KG reasoning based on symbolic logic is deterministic, with reasoning results being explainable, while modern embedding-based reasoning can deal with uncertainty and predict plausible knowledge, often with high efficiency via vector computation. A promising direction is to integrate both logic-based and embedding-based methods, with the vision to have advantages of both. It has attracted wide research attention with more and more works published in recent years. In this paper, we comprehensively survey these works, focusing on how logics and embeddings are integrated. We first briefly introduce preliminaries, then systematically categorize and discuss works of logic and embedding-aware KG reasoning from different perspectives, and finally conclude and discuss the challenges and further directions.