 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond GEMM-Centric NPUs: Enabling Efficient Diffusion LLM Sampling
Jan 28, 2026Diffusion Large Language Models (dLLMs) introduce iterative denoising to enable parallel token generation, but their sampling phase displays fundamentally different characteristics compared to GEMM-centric transformer layers. Profiling on modern GPUs reveals that sampling can account for up to 70% of total model inference latency-primarily due to substantial memory loads and writes from vocabulary-wide logits, reduction-based token selection, and iterative masked updates. These processes demand large on-chip SRAM and involve irregular memory accesses that conventional NPUs struggle to handle efficiently. To address this, we identify a set of critical instructions that an NPU architecture must specifically optimize for dLLM sampling. Our design employs lightweight non-GEMM vector primitives, in-place memory reuse strategies, and a decoupled mixed-precision memory hierarchy. Together, these optimizations deliver up to a 2.53x speedup over the NVIDIA RTX A6000 GPU under an equivalent nm technology node. We also open-source our cycle-accurate simulation and post-synthesis RTL verification code, confirming functional equivalence with current dLLM PyTorch implementations.
Speech-Aware Long Context Pruning and Integration for Contextualized Automatic Speech Recognition
Nov 14, 2025Automatic speech recognition (ASR) systems have achieved remarkable performance in common conditions but often struggle to leverage long-context information in contextualized scenarios that require domain-specific knowledge, such as conference presentations. This challenge arises primarily due to constrained model context windows and the sparsity of relevant information within extensive contextual noise. To solve this, we propose the SAP$^{2}$ method, a novel framework that dynamically prunes and integrates relevant contextual keywords in two stages. Specifically, each stage leverages our proposed Speech-Driven Attention-based Pooling mechanism, enabling efficient compression of context embeddings while preserving speech-salient information. Experimental results demonstrate state-of-the-art performance of SAP$^{2}$ on the SlideSpeech and LibriSpeech datasets, achieving word error rates (WER) of 7.71% and 1.12%, respectively. On SlideSpeech, our method notably reduces biased keyword error rates (B-WER) by 41.1% compared to non-contextual baselines. SAP$^{2}$ also exhibits robust scalability, consistently maintaining performance under extensive contextual input conditions on both datasets.
ASPO: Constraint-Aware Bayesian Optimization for FPGA-based Soft Processors
Jun 07, 2025Bayesian Optimization (BO) has shown promise in tuning processor design parameters. However, standard BO does not support constraints involving categorical parameters such as types of branch predictors and division circuits. In addition, optimization time of BO grows with processor complexity, which becomes increasingly significant especially for FPGA-based soft processors. This paper introduces ASPO, an approach that leverages disjunctive form to enable BO to handle constraints involving categorical parameters. Unlike existing methods that directly apply standard BO, the proposed ASPO method, for the first time, customizes the mathematical mechanism of BO to address challenges faced by soft-processor designs on FPGAs. Specifically, ASPO supports categorical parameters using a novel customized BO covariance kernel. It also accelerates the design evaluation procedure by penalizing the BO acquisition function with potential evaluation time and by reusing FPGA synthesis checkpoints from previously evaluated configurations. ASPO targets three soft processors: RocketChip, BOOM, and EL2 VeeR. The approach is evaluated based on seven RISC-V benchmarks. Results show that ASPO can reduce execution time for the ``multiply'' benchmark on the BOOM processor by up to 35\% compared to the default configuration. Furthermore, it reduces design time for the BOOM processor by up to 74\% compared to Boomerang, a state-of-the-art hardware-oriented BO approach.
* Accepted to International Conference on Field-Programmable Logic and Applications (FPL) 2025
DeepSelective: Feature Gating and Representation Matching for Interpretable Clinical Prediction
Apr 15, 2025



The rapid accumulation of Electronic Health Records (EHRs) has transformed healthcare by providing valuable data that enhance clinical predictions and diagnoses. While conventional machine learning models have proven effective, they often lack robust representation learning and depend heavily on expert-crafted features. Although deep learning offers powerful solutions, it is often criticized for its lack of interpretability. To address these challenges, we propose DeepSelective, a novel end to end deep learning framework for predicting patient prognosis using EHR data, with a strong emphasis on enhancing model interpretability. DeepSelective combines data compression techniques with an innovative feature selection approach, integrating custom-designed modules that work together to improve both accuracy and interpretability. Our experiments demonstrate that DeepSelective not only enhances predictive accuracy but also significantly improves interpretability, making it a valuable tool for clinical decision-making. The source code is freely available at http://www.healthinformaticslab.org/supp/resources.php .
LVC: A Lightweight Compression Framework for Enhancing VLMs in Long Video Understanding
Apr 09, 2025Long video understanding is a complex task that requires both spatial detail and temporal awareness. While Vision-Language Models (VLMs) obtain frame-level understanding capabilities through multi-frame input, they suffer from information loss due to the sparse sampling strategy. In contrast, Video Large Language Models (Video-LLMs) capture temporal relationships within visual features but are limited by the scarcity of high-quality video-text datasets. To transfer long video understanding capabilities to VLMs with minimal data and computational cost, we propose Lightweight Video Compression (LVC), a novel method featuring the Query-Attention Video Compression mechanism, which effectively tackles the sparse sampling problem in VLMs. By training only the alignment layer with 10k short video-text pairs, LVC significantly enhances the temporal reasoning abilities of VLMs. Extensive experiments show that LVC provides consistent performance improvements across various models, including the InternVL2 series and Phi-3.5-Vision. Notably, the InternVL2-40B-LVC achieves scores of 68.2 and 65.9 on the long video understanding benchmarks MLVU and Video-MME, respectively, with relative improvements of 14.6% and 7.7%. The enhanced models and code will be publicly available soon.
FREA: Feasibility-Guided Generation of Safety-Critical Scenarios with Reasonable Adversariality
Jun 05, 2024



Generating safety-critical scenarios, which are essential yet difficult to collect at scale, offers an effective method to evaluate the robustness of autonomous vehicles (AVs). Existing methods focus on optimizing adversariality while preserving the naturalness of scenarios, aiming to achieve a balance through data-driven approaches. However, without an appropriate upper bound for adversariality, the scenarios might exhibit excessive adversariality, potentially leading to unavoidable collisions. In this paper, we introduce FREA, a novel safety-critical scenarios generation method that incorporates the Largest Feasible Region (LFR) of AV as guidance to ensure the reasonableness of the adversarial scenarios. Concretely, FREA initially pre-calculates the LFR of AV from offline datasets. Subsequently, it learns a reasonable adversarial policy that controls critical background vehicles (CBVs) in the scene to generate adversarial yet AV-feasible scenarios by maximizing a novel feasibility-dependent objective function. Extensive experiments illustrate that FREA can effectively generate safety-critical scenarios, yielding considerable near-miss events while ensuring AV's feasibility. Generalization analysis also confirms the robustness of FREA in AV testing across various surrogate AV methods and traffic environments.
SparseDrive: End-to-End Autonomous Driving via Sparse Scene Representation
May 31, 2024



The well-established modular autonomous driving system is decoupled into different standalone tasks, e.g. perception, prediction and planning, suffering from information loss and error accumulation across modules. In contrast, end-to-end paradigms unify multi-tasks into a fully differentiable framework, allowing for optimization in a planning-oriented spirit. Despite the great potential of end-to-end paradigms, both the performance and efficiency of existing methods are not satisfactory, particularly in terms of planning safety. We attribute this to the computationally expensive BEV (bird's eye view) features and the straightforward design for prediction and planning. To this end, we explore the sparse representation and review the task design for end-to-end autonomous driving, proposing a new paradigm named SparseDrive. Concretely, SparseDrive consists of a symmetric sparse perception module and a parallel motion planner. The sparse perception module unifies detection, tracking and online mapping with a symmetric model architecture, learning a fully sparse representation of the driving scene. For motion prediction and planning, we review the great similarity between these two tasks, leading to a parallel design for motion planner. Based on this parallel design, which models planning as a multi-modal problem, we propose a hierarchical planning selection strategy , which incorporates a collision-aware rescore module, to select a rational and safe trajectory as the final planning output. With such effective designs, SparseDrive surpasses previous state-of-the-arts by a large margin in performance of all tasks, while achieving much higher training and inference efficiency. Code will be avaliable at https://github.com/swc-17/SparseDrive for facilitating future research.
AccidentBlip2: Accident Detection With Multi-View MotionBlip2
Apr 19, 2024



Multimodal Large Language Models (MLLMs) have shown outstanding capabilities in many areas of multimodal reasoning. Therefore, we use the reasoning ability of Multimodal Large Language Models for environment description and scene understanding in complex transportation environments. In this paper, we propose AccidentBlip2, a multimodal large language model that can predict in real time whether an accident risk will occur. Our approach involves feature extraction based on the temporal scene of the six-view surround view graphs and temporal inference using the temporal blip framework through the vision transformer. We then input the generated temporal token into the MLLMs for inference to determine whether an accident will occur or not. Since AccidentBlip2 does not rely on any BEV images and LiDAR, the number of inference parameters and the inference cost of MLLMs can be significantly reduced, and it also does not incur a large training overhead during training. AccidentBlip2 outperforms existing solutions on the DeepAccident dataset and can also provide a reference solution for end-to-end automated driving accident prediction.
PepHarmony: A Multi-View Contrastive Learning Framework for Integrated Sequence and Structure-Based Peptide Encoding
Jan 21, 2024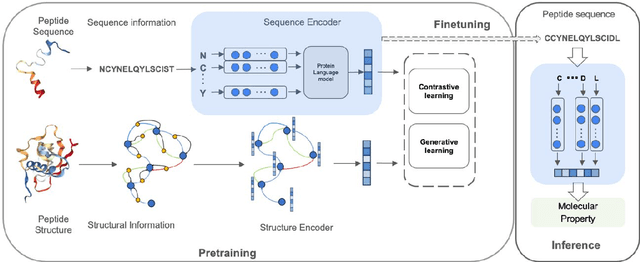

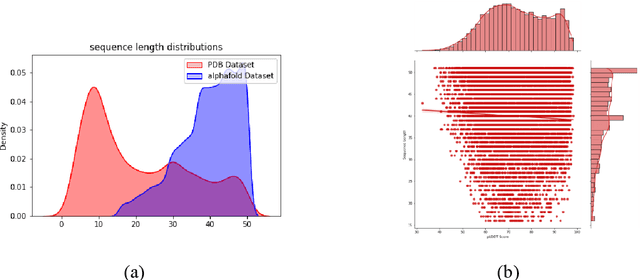

Recent advances in protein language models have catalyzed significant progress in peptide sequence representation. Despite extensive exploration in this field, pre-trained models tailored for peptide-specific needs remain largely unaddressed due to the difficulty in capturing the complex and sometimes unstable structures of peptides. This study introduces a novel multi-view contrastive learning framework PepHarmony for the sequence-based peptide encoding task. PepHarmony innovatively combines both sequence- and structure-level information into a sequence-level encoding module through contrastive learning. We carefully select datasets from the Protein Data Bank (PDB) and AlphaFold database to encompass a broad spectrum of peptide sequences and structures. The experimental data highlights PepHarmony's exceptional capability in capturing the intricate relationship between peptide sequences and structures compared with the baseline and fine-tuned models. The robustness of our model is confirmed through extensive ablation studies, which emphasize the crucial roles of contrastive loss and strategic data sorting in enhancing predictive performance. The proposed PepHarmony framework serves as a notable contribution to peptide representations, and offers valuable insights for future applications in peptide drug discovery and peptide engineering. We have made all the source code utilized in this study publicly accessible via GitHub at https://github.com/zhangruochi/PepHarmony or http://www.healthinformaticslab.org/supp/.
FedNS: A Fast Sketching Newton-Type Algorithm for Federated Learning
Jan 05, 2024Recent Newton-type federated learning algorithms have demonstrated linear convergence with respect to the communication rounds. However, communicating Hessian matrices is often unfeasible due to their quadratic communication complexity. In this paper, we introduce a novel approach to tackle this issue while still achieving fast convergence rates. Our proposed method, named as Federated Newton Sketch methods (FedNS), approximates the centralized Newton's method by communicating the sketched square-root Hessian instead of the exact Hessian. To enhance communication efficiency, we reduce the sketch size to match the effective dimension of the Hessian matrix. We provide convergence analysis based on statistical learning for the federated Newton sketch approaches. Specifically, our approaches reach super-linear convergence rates w.r.t. the communication rounds for the first time. We validate the effectiveness of our algorithms through various experiments, which coincide with our theoretical findings.