 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: Counterfactual-to-Interactive Reinforcement Fine-Tuning for Driving Policies
May 06, 2026Open-loop imitation learning has advanced modern autonomous driving policy architectures, but closed-loop deployment remains vulnerable to policy-induced distribution shift. Existing post-training paradigms exhibit fundamental trade-offs: closed-loop RL fine-tuning provides grounded feedback from executed actions but is constrained by the sparsity of informative events, whereas counterfactual fine-tuning provides dense supervision over candidate futures but inherits bias from imperfect future estimates. We introduce Counterfactual-to-Interactive Reinforcement Fine-Tuning (CRAFT), an on-policy framework that formulates closed-loop post-training as proxy-residual optimization. CRAFT uses group-normalized counterfactual advantages as a dense proxy for real closed-loop advantages and aligns this proxy with the closed-loop world through grounded residual correction from interaction-critical events. To stabilize adaptation, CRAFT regularizes the online policy toward an EMA teacher via asymmetric KL self-distillation. Theoretically, CRAFT decomposes the real closed-loop policy gradient into proxy and residual terms under the same visited-state distribution, reducing residual variance with an aligned proxy while mitigating proxy bias through grounded residual approximation. Empirically, CRAFT achieves the strongest closed-loop gains on Bench2Drive across hierarchical planning, vision-language-action, and vocabulary-scoring architectures. Ablations, scaling behavior, stability analyses, and transfer results further validate the complementary roles of dense counterfactual proxy and grounded residual correction. Project page: https://currychen77.github.io/CRAFT.
SparseDriveV2: Scoring is All You Need for End-to-End Autonomous Driving
Mar 31, 2026End-to-end multi-modal planning has been widely adopted to model the uncertainty of driving behavior, typically by scoring candidate trajectories and selecting the optimal one. Existing approaches generally fall into two categories: scoring a large static trajectory vocabulary, or scoring a small set of dynamically generated proposals. While static vocabularies often suffer from coarse discretization of the action space, dynamic proposals provide finer-grained precision and have shown stronger empirical performance on existing benchmarks. However, it remains unclear whether dynamic generation is fundamentally necessary, or whether static vocabularies can already achieve comparable performance when they are sufficiently dense to cover the action space. In this work, we start with a systematic scaling study of Hydra-MDP, a representative scoring-based method, revealing that performance consistently improves as trajectory anchors become denser, without exhibiting saturation before computational constraints are reached. Motivated by this observation, we propose SparseDriveV2 to push the performance boundary of scoring-based planning through two complementary innovations: (1) a scalable vocabulary representation with a factorized structure that decomposes trajectories into geometric paths and velocity profiles, enabling combinatorial coverage of the action space, and (2) a scalable scoring strategy with coarse factorized scoring over paths and velocity profiles followed by fine-grained scoring on a small set of composed trajectories. By combining these two techniques, SparseDriveV2 achieves 92.0 PDMS and 90.1 EPDMS on NAVSIM, with 89.15 Driving Score and 70.00 Success Rate on Bench2Drive with a lightweight ResNet-34 as backbone. Code and model are released at https://github.com/swc-17/SparseDriveV2.
ForSim: Stepwise Forward Simulation for Traffic Policy Fine-Tuning
Feb 02, 2026As the foundation of closed-loop training and evaluation in autonomous driving, traffic simulation still faces two fundamental challenges: covariate shift introduced by open-loop imitation learning and limited capacity to reflect the multimodal behaviors observed in real-world traffic. Although recent frameworks such as RIFT have partially addressed these issues through group-relative optimization, their forward simulation procedures remain largely non-reactive, leading to unrealistic agent interactions within the virtual domain and ultimately limiting simulation fidelity. To address these issues, we propose ForSim, a stepwise closed-loop forward simulation paradigm. At each virtual timestep, the traffic agent propagates the virtual candidate trajectory that best spatiotemporally matches the reference trajectory through physically grounded motion dynamics, thereby preserving multimodal behavioral diversity while ensuring intra-modality consistency. Other agents are updated with stepwise predictions, yielding coherent and interaction-aware evolution. When incorporated into the RIFT traffic simulation framework, ForSim operates in conjunction with group-relative optimization to fine-tune traffic policy. Extensive experiments confirm that this integration consistently improves safety while maintaining efficiency, realism, and comfort. These results underscore the importance of modeling closed-loop multimodal interactions within forward simulation and enhance the fidelity and reliability of traffic simulation for autonomous driving. Project Page: https://currychen77.github.io/ForSim/
COME: Adding Scene-Centric Forecasting Control to Occupancy World Model
Jun 16, 2025World models are critical for autonomous driving to simulate environmental dynamics and generate synthetic data. Existing methods struggle to disentangle ego-vehicle motion (perspective shifts) from scene evolvement (agent interactions), leading to suboptimal predictions. Instead, we propose to separate environmental changes from ego-motion by leveraging the scene-centric coordinate systems. In this paper, we introduce COME: a framework that integrates scene-centric forecasting Control into the Occupancy world ModEl. Specifically, COME first generates ego-irrelevant, spatially consistent future features through a scene-centric prediction branch, which are then converted into scene condition using a tailored ControlNet. These condition features are subsequently injected into the occupancy world model, enabling more accurate and controllable future occupancy predictions. Experimental results on the nuScenes-Occ3D dataset show that COME achieves consistent and significant improvements over state-of-the-art (SOTA) methods across diverse configurations, including different input sources (ground-truth, camera-based, fusion-based occupancy) and prediction horizons (3s and 8s). For example, under the same settings, COME achieves 26.3% better mIoU metric than DOME and 23.7% better mIoU metric than UniScene. These results highlight the efficacy of disentangled representation learning in enhancing spatio-temporal prediction fidelity for world models. Code and videos will be available at https://github.com/synsin0/COME.
DriveCamSim: Generalizable Camera Simulation via Explicit Camera Modeling for Autonomous Driving
May 26, 2025Camera sensor simulation serves as a critical role for autonomous driving (AD), e.g. evaluating vision-based AD algorithms. While existing approaches have leveraged generative models for controllable image/video generation, they remain constrained to generating multi-view video sequences with fixed camera viewpoints and video frequency, significantly limiting their downstream applications. To address this, we present a generalizable camera simulation framework DriveCamSim, whose core innovation lies in the proposed Explicit Camera Modeling (ECM) mechanism. Instead of implicit interaction through vanilla attention, ECM establishes explicit pixel-wise correspondences across multi-view and multi-frame dimensions, decoupling the model from overfitting to the specific camera configurations (intrinsic/extrinsic parameters, number of views) and temporal sampling rates presented in the training data. For controllable generation, we identify the issue of information loss inherent in existing conditional encoding and injection pipelines, proposing an information-preserving control mechanism. This control mechanism not only improves conditional controllability, but also can be extended to be identity-aware to enhance temporal consistency in foreground object rendering. With above designs, our model demonstrates superior performance in both visual quality and controllability, as well as generalization capability across spatial-level (camera parameters variations) and temporal-level (video frame rate variations), enabling flexible user-customizable camera simulation tailored to diverse application scenarios. Code will be avaliable at https://github.com/swc-17/DriveCamSim for facilitating future research.
RIFT: Closed-Loop RL Fine-Tuning for Realistic and Controllable Traffic Simulation
May 06, 2025



Achieving both realism and controllability in interactive closed-loop traffic simulation remains a key challenge in autonomous driving. Data-driven simulation methods reproduce realistic trajectories but suffer from covariate shift in closed-loop deployment, compounded by simplified dynamics models that further reduce reliability. Conversely, physics-based simulation methods enhance reliable and controllable closed-loop interactions but often lack expert demonstrations, compromising realism. To address these challenges, we introduce a dual-stage AV-centered simulation framework that conducts open-loop imitation learning pre-training in a data-driven simulator to capture trajectory-level realism and multimodality, followed by closed-loop reinforcement learning fine-tuning in a physics-based simulator to enhance controllability and mitigate covariate shift. In the fine-tuning stage, we propose RIFT, a simple yet effective closed-loop RL fine-tuning strategy that preserves the trajectory-level multimodality through a GRPO-style group-relative advantage formulation, while enhancing controllability and training stability by replacing KL regularization with the dual-clip mechanism. Extensive experiments demonstrate that RIFT significantly improves the realism and controllability of generated traffic scenarios, providing a robust platform for evaluating autonomous vehicle performance in diverse and interactive scenarios.
FREA: Feasibility-Guided Generation of Safety-Critical Scenarios with Reasonable Adversariality
Jun 05, 2024



Generating safety-critical scenarios, which are essential yet difficult to collect at scale, offers an effective method to evaluate the robustness of autonomous vehicles (AVs). Existing methods focus on optimizing adversariality while preserving the naturalness of scenarios, aiming to achieve a balance through data-driven approaches. However, without an appropriate upper bound for adversariality, the scenarios might exhibit excessive adversariality, potentially leading to unavoidable collisions. In this paper, we introduce FREA, a novel safety-critical scenarios generation method that incorporates the Largest Feasible Region (LFR) of AV as guidance to ensure the reasonableness of the adversarial scenarios. Concretely, FREA initially pre-calculates the LFR of AV from offline datasets. Subsequently, it learns a reasonable adversarial policy that controls critical background vehicles (CBVs) in the scene to generate adversarial yet AV-feasible scenarios by maximizing a novel feasibility-dependent objective function. Extensive experiments illustrate that FREA can effectively generate safety-critical scenarios, yielding considerable near-miss events while ensuring AV's feasibility. Generalization analysis also confirms the robustness of FREA in AV testing across various surrogate AV methods and traffic environments.
SparseDrive: End-to-End Autonomous Driving via Sparse Scene Representation
May 31, 2024



The well-established modular autonomous driving system is decoupled into different standalone tasks, e.g. perception, prediction and planning, suffering from information loss and error accumulation across modules. In contrast, end-to-end paradigms unify multi-tasks into a fully differentiable framework, allowing for optimization in a planning-oriented spirit. Despite the great potential of end-to-end paradigms, both the performance and efficiency of existing methods are not satisfactory, particularly in terms of planning safety. We attribute this to the computationally expensive BEV (bird's eye view) features and the straightforward design for prediction and planning. To this end, we explore the sparse representation and review the task design for end-to-end autonomous driving, proposing a new paradigm named SparseDrive. Concretely, SparseDrive consists of a symmetric sparse perception module and a parallel motion planner. The sparse perception module unifies detection, tracking and online mapping with a symmetric model architecture, learning a fully sparse representation of the driving scene. For motion prediction and planning, we review the great similarity between these two tasks, leading to a parallel design for motion planner. Based on this parallel design, which models planning as a multi-modal problem, we propose a hierarchical planning selection strategy , which incorporates a collision-aware rescore module, to select a rational and safe trajectory as the final planning output. With such effective designs, SparseDrive surpasses previous state-of-the-arts by a large margin in performance of all tasks, while achieving much higher training and inference efficiency. Code will be avaliable at https://github.com/swc-17/SparseDrive for facilitating future research.
Neural Radiance Field in Autonomous Driving: A Survey
Apr 26, 2024



Neural Radiance Field (NeRF) has garnered significant attention from both academia and industry due to its intrinsic advantages, particularly its implicit representation and novel view synthesis capabilities. With the rapid advancements in deep learning, a multitude of methods have emerged to explore the potential applications of NeRF in the domain of Autonomous Driving (AD). However, a conspicuous void is apparent within the current literature. To bridge this gap, this paper conducts a comprehensive survey of NeRF's applications in the context of AD. Our survey is structured to categorize NeRF's applications in Autonomous Driving (AD), specifically encompassing perception, 3D reconstruction, simultaneous localization and mapping (SLAM), and simulation. We delve into in-depth analysis and summarize the findings for each application category, and conclude by providing insights and discussions on future directions in this field. We hope this paper serves as a comprehensive reference for researchers in this domain. To the best of our knowledge, this is the first survey specifically focused on the applications of NeRF in the Autonomous Driving domain.
Learn Zero-Constraint-Violation Policy in Model-Free Constrained Reinforcement Learning
Nov 25, 2021

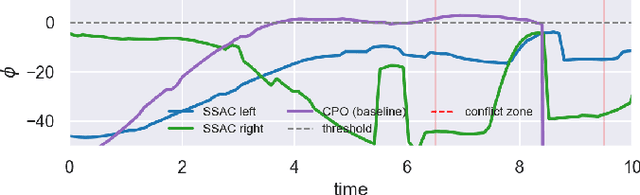
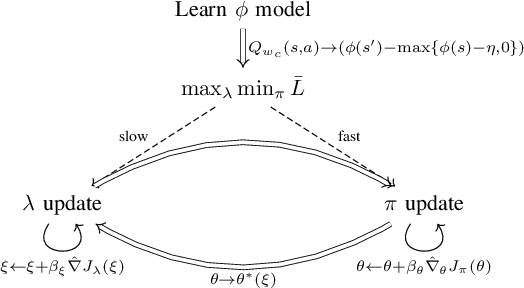
In the trial-and-error mechanism of reinforcement learning (RL), a notorious contradiction arises when we expect to learn a safe policy: how to learn a safe policy without enough data and prior model about the dangerous region? Existing methods mostly use the posterior penalty for dangerous actions, which means that the agent is not penalized until experiencing danger. This fact causes that the agent cannot learn a zero-violation policy even after convergence. Otherwise, it would not receive any penalty and lose the knowledge about danger. In this paper, we propose the safe set actor-critic (SSAC) algorithm, which confines the policy update using safety-oriented energy functions, or the safety indexes. The safety index is designed to increase rapidly for potentially dangerous actions, which allows us to locate the safe set on the action space, or the control safe set. Therefore, we can identify the dangerous actions prior to taking them, and further obtain a zero constraint-violation policy after convergence.We claim that we can learn the energy function in a model-free manner similar to learning a value function. By using the energy function transition as the constraint objective, we formulate a constrained RL problem. We prove that our Lagrangian-based solutions make sure that the learned policy will converge to the constrained optimum under some assumptions. The proposed algorithm is evaluated on both the complex simulation environments and a hardware-in-loop (HIL) experiment with a real controller from the autonomous vehicle. Experimental results suggest that the converged policy in all environments achieves zero constraint violation and comparable performance with model-based baselines.