 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond GEMM-Centric NPUs: Enabling Efficient Diffusion LLM Sampling
Jan 28, 2026Diffusion Large Language Models (dLLMs) introduce iterative denoising to enable parallel token generation, but their sampling phase displays fundamentally different characteristics compared to GEMM-centric transformer layers. Profiling on modern GPUs reveals that sampling can account for up to 70% of total model inference latency-primarily due to substantial memory loads and writes from vocabulary-wide logits, reduction-based token selection, and iterative masked updates. These processes demand large on-chip SRAM and involve irregular memory accesses that conventional NPUs struggle to handle efficiently. To address this, we identify a set of critical instructions that an NPU architecture must specifically optimize for dLLM sampling. Our design employs lightweight non-GEMM vector primitives, in-place memory reuse strategies, and a decoupled mixed-precision memory hierarchy. Together, these optimizations deliver up to a 2.53x speedup over the NVIDIA RTX A6000 GPU under an equivalent nm technology node. We also open-source our cycle-accurate simulation and post-synthesis RTL verification code, confirming functional equivalence with current dLLM PyTorch implementations.
A Clustering Method Based on Information Entropy Payload
Sep 13, 2022
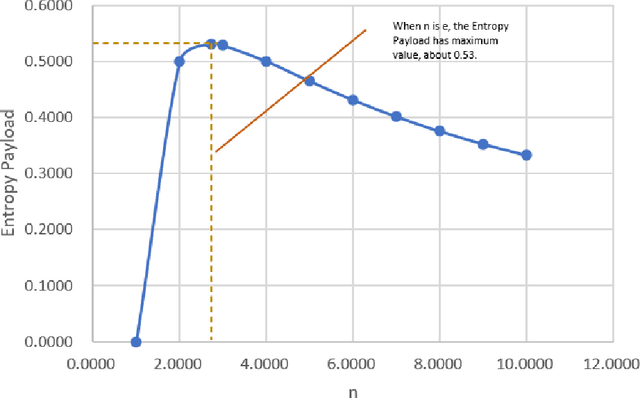

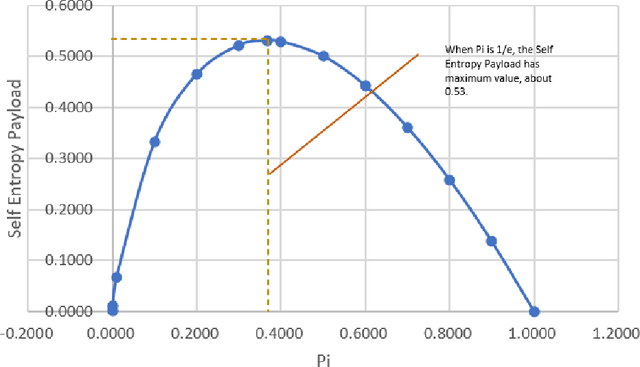
Existing clustering algorithms such as K-means often need to preset parameters such as the number of categories K, and such parameters may lead to the failure to output objective and consistent clustering results. This paper introduces a clustering method based on the information theory, by which clusters in the clustering result have maximum average information entropy (called entropy payload in this paper). This method can bring the following benefits: firstly, this method does not need to preset any super parameter such as category number or other similar thresholds, secondly, the clustering results have the maximum information expression efficiency. it can be used in image segmentation, object classification, etc., and could be the basis of unsupervised learning.