 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Temporal Causal Structure via Smooth Differentiable Optimization
Jun 02, 2026Causal discovery with instantaneous effects in multivariate time series is challenging, as the instantaneous structure must be acyclic. Prior methods enforce this by either separating instantaneous and lagged estimation into multi-stage pipelines or imposing algebraic acyclicity constraints via complex augmented Lagrangian optimization, both of which incur high computational cost. In this work, we propose a different approach: we learn a differentiable permutation of variables using the Gumbel--Sinkhorn operator and triangularize the instantaneous coefficient matrix of a Structural Vector Autoregressive (SVAR) model in the learned order. This converts acyclicity from a hard constraint into a parameterization and keeps it valid throughout optimization. In doing so, our method enables unified, continuous optimization with gradient-based learning, leading to improved efficiency in time--series causal discovery. Across three real-world benchmarks, our method achieves the best overall performance compared with 12 baselines in both discovery accuracy and efficiency. On the large-scale benchmark, it further demonstrates strong scalability, achieving more than a 6x speedup over competing methods.
VCDF: A Validated Consensus-Driven Framework for Time Series Causal Discovery
Feb 22, 2026Time series causal discovery is essential for understanding dynamic systems, yet many existing methods remain sensitive to noise, non-stationarity, and sampling variability. We propose the Validated Consensus-Driven Framework (VCDF), a simple and method-agnostic layer that improves robustness by evaluating the stability of causal relations across blocked temporal subsets. VCDF requires no modification to base algorithms and can be applied to methods such as VAR-LiNGAM and PCMCI. Experiments on synthetic datasets show that VCDF improves VAR-LiNGAM by approximately 0.08-0.12 in both window and summary F1 scores across diverse data characteristics, with gains most pronounced for moderate-to-long sequences. The framework also benefits from longer sequences, yielding up to 0.18 absolute improvement on time series of length 1000 and above. Evaluations on simulated fMRI data and IT-monitoring scenarios further demonstrate enhanced stability and structural accuracy under realistic noise conditions. VCDF provides an effective reliability layer for time series causal discovery without altering underlying modeling assumptions.
Grasp Like Humans: Learning Generalizable Multi-Fingered Grasping from Human Proprioceptive Sensorimotor Integration
Sep 10, 2025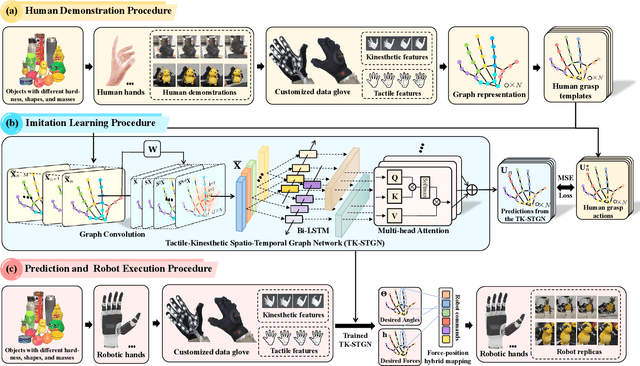
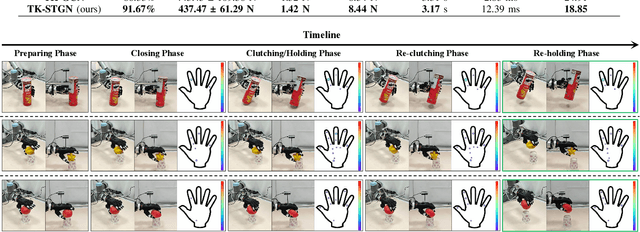

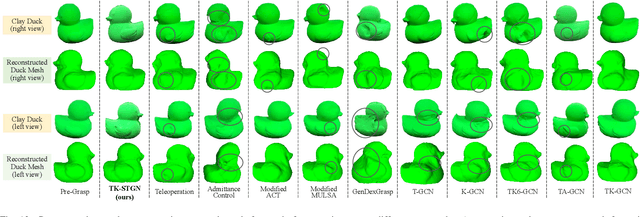
Tactile and kinesthetic perceptions are crucial for human dexterous manipulation, enabling reliable grasping of objects via proprioceptive sensorimotor integration. For robotic hands, even though acquiring such tactile and kinesthetic feedback is feasible, establishing a direct mapping from this sensory feedback to motor actions remains challenging. In this paper, we propose a novel glove-mediated tactile-kinematic perception-prediction framework for grasp skill transfer from human intuitive and natural operation to robotic execution based on imitation learning, and its effectiveness is validated through generalized grasping tasks, including those involving deformable objects. Firstly, we integrate a data glove to capture tactile and kinesthetic data at the joint level. The glove is adaptable for both human and robotic hands, allowing data collection from natural human hand demonstrations across different scenarios. It ensures consistency in the raw data format, enabling evaluation of grasping for both human and robotic hands. Secondly, we establish a unified representation of multi-modal inputs based on graph structures with polar coordinates. We explicitly integrate the morphological differences into the designed representation, enhancing the compatibility across different demonstrators and robotic hands. Furthermore, we introduce the Tactile-Kinesthetic Spatio-Temporal Graph Networks (TK-STGN), which leverage multidimensional subgraph convolutions and attention-based LSTM layers to extract spatio-temporal features from graph inputs to predict node-based states for each hand joint. These predictions are then mapped to final commands through a force-position hybrid mapping.
ASPO: Constraint-Aware Bayesian Optimization for FPGA-based Soft Processors
Jun 07, 2025Bayesian Optimization (BO) has shown promise in tuning processor design parameters. However, standard BO does not support constraints involving categorical parameters such as types of branch predictors and division circuits. In addition, optimization time of BO grows with processor complexity, which becomes increasingly significant especially for FPGA-based soft processors. This paper introduces ASPO, an approach that leverages disjunctive form to enable BO to handle constraints involving categorical parameters. Unlike existing methods that directly apply standard BO, the proposed ASPO method, for the first time, customizes the mathematical mechanism of BO to address challenges faced by soft-processor designs on FPGAs. Specifically, ASPO supports categorical parameters using a novel customized BO covariance kernel. It also accelerates the design evaluation procedure by penalizing the BO acquisition function with potential evaluation time and by reusing FPGA synthesis checkpoints from previously evaluated configurations. ASPO targets three soft processors: RocketChip, BOOM, and EL2 VeeR. The approach is evaluated based on seven RISC-V benchmarks. Results show that ASPO can reduce execution time for the ``multiply'' benchmark on the BOOM processor by up to 35\% compared to the default configuration. Furthermore, it reduces design time for the BOOM processor by up to 74\% compared to Boomerang, a state-of-the-art hardware-oriented BO approach.
* Accepted to International Conference on Field-Programmable Logic and Applications (FPL) 2025
NuExo: A Wearable Exoskeleton Covering all Upper Limb ROM for Outdoor Data Collection and Teleoperation of Humanoid Robots
Mar 13, 2025



The evolution from motion capture and teleoperation to robot skill learning has emerged as a hotspot and critical pathway for advancing embodied intelligence. However, existing systems still face a persistent gap in simultaneously achieving four objectives: accurate tracking of full upper limb movements over extended durations (Accuracy), ergonomic adaptation to human biomechanics (Comfort), versatile data collection (e.g., force data) and compatibility with humanoid robots (Versatility), and lightweight design for outdoor daily use (Convenience). We present a wearable exoskeleton system, incorporating user-friendly immersive teleoperation and multi-modal sensing collection to bridge this gap. Due to the features of a novel shoulder mechanism with synchronized linkage and timing belt transmission, this system can adapt well to compound shoulder movements and replicate 100% coverage of natural upper limb motion ranges. Weighing 5.2 kg, NuExo supports backpack-type use and can be conveniently applied in daily outdoor scenarios. Furthermore, we develop a unified intuitive teleoperation framework and a comprehensive data collection system integrating multi-modal sensing for various humanoid robots. Experiments across distinct humanoid platforms and different users validate our exoskeleton's superiority in motion range and flexibility, while confirming its stability in data collection and teleoperation accuracy in dynamic scenarios.
ResBench: Benchmarking LLM-Generated FPGA Designs with Resource Awareness
Mar 11, 2025



Field-Programmable Gate Arrays (FPGAs) are widely used in modern hardware design, yet writing Hardware Description Language (HDL) code for FPGA implementation remains labor-intensive and complex. Large Language Models (LLMs) have emerged as a promising tool for automating HDL generation, but existing benchmarks for LLM HDL code generation primarily evaluate functional correctness while overlooking the critical aspect of hardware resource efficiency. Moreover, current benchmarks lack diversity, failing to capture the broad range of real-world FPGA applications. To address these gaps, we introduce ResBench, the first resource-oriented benchmark explicitly designed to differentiate between resource-optimized and inefficient LLM-generated HDL. ResBench consists of 56 problems across 12 categories, covering applications from finite state machines to financial computing. Our evaluation framework systematically integrates FPGA resource constraints, with a primary focus on Lookup Table (LUT) usage, enabling a realistic assessment of hardware efficiency. Experimental results reveal substantial differences in resource utilization across LLMs, demonstrating ResBench's effectiveness in distinguishing models based on their ability to generate resource-optimized FPGA designs.
MetaML-Pro: Cross-Stage Design Flow Automation for Efficient Deep Learning Acceleration
Feb 09, 2025This paper presents a unified framework for codifying and automating optimization strategies to efficiently deploy deep neural networks (DNNs) on resource-constrained hardware, such as FPGAs, while maintaining high performance, accuracy, and resource efficiency. Deploying DNNs on such platforms involves addressing the significant challenge of balancing performance, resource usage (e.g., DSPs and LUTs), and inference accuracy, which often requires extensive manual effort and domain expertise. Our novel approach addresses two key issues: cross-stage co-optimization and optimization search. By seamlessly integrating programmatic DNN optimization techniques with high-level synthesis (HLS)-based metaprogramming and leveraging advanced design space exploration (DSE) strategies like Bayesian optimization, the framework automates both top-down and bottom-up design flows, reducing the need for manual intervention and domain expertise. The proposed framework introduces customizable optimization, transformation, and control blocks to enhance DNN accelerator performance and resource efficiency. Experimental results demonstrate up to a 92\% DSP and 89\% LUT usage reduction for select networks, while preserving accuracy, along with a 15.6-fold reduction in optimization time compared to grid search. These results underscore the novelty and potential of the proposed framework for automated, resource-efficient DNN accelerator designs.
Robust Time Series Causal Discovery for Agent-Based Model Validation
Oct 25, 2024Agent-Based Model (ABM) validation is crucial as it helps ensuring the reliability of simulations, and causal discovery has become a powerful tool in this context. However, current causal discovery methods often face accuracy and robustness challenges when applied to complex and noisy time series data, which is typical in ABM scenarios. This study addresses these issues by proposing a Robust Cross-Validation (RCV) approach to enhance causal structure learning for ABM validation. We develop RCV-VarLiNGAM and RCV-PCMCI, novel extensions of two prominent causal discovery algorithms. These aim to reduce the impact of noise better and give more reliable causal relation results, even with high-dimensional, time-dependent data. The proposed approach is then integrated into an enhanced ABM validation framework, which is designed to handle diverse data and model structures. The approach is evaluated using synthetic datasets and a complex simulated fMRI dataset. The results demonstrate greater reliability in causal structure identification. The study examines how various characteristics of datasets affect the performance of established causal discovery methods. These characteristics include linearity, noise distribution, stationarity, and causal structure density. This analysis is then extended to the RCV method to see how it compares in these different situations. This examination helps confirm whether the results are consistent with existing literature and also reveals the strengths and weaknesses of the novel approaches. By tackling key methodological challenges, the study aims to enhance ABM validation with a more resilient valuation framework presented. These improvements increase the reliability of model-driven decision making processes in complex systems analysis.
Optimizing VarLiNGAM for Scalable and Efficient Time Series Causal Discovery
Sep 09, 2024



Causal discovery is designed to identify causal relationships in data, a task that has become increasingly complex due to the computational demands of traditional methods such as VarLiNGAM, which combines Vector Autoregressive Model with Linear Non-Gaussian Acyclic Model for time series data. This study is dedicated to optimising causal discovery specifically for time series data, which is common in practical applications. Time series causal discovery is particularly challenging due to the need to account for temporal dependencies and potential time lag effects. By designing a specialised dataset generator and reducing the computational complexity of the VarLiNGAM model from \( O(m^3 \cdot n) \) to \( O(m^3 + m^2 \cdot n) \), this study significantly improves the feasibility of processing large datasets. The proposed methods have been validated on advanced computational platforms and tested across simulated, real-world, and large-scale datasets, showcasing enhanced efficiency and performance. The optimised algorithm achieved 7 to 13 times speedup compared with the original algorithm and around 4.5 times speedup compared with the GPU-accelerated version on large-scale datasets with feature sizes between 200 and 400. Our methods aim to push the boundaries of current causal discovery capabilities, making them more robust, scalable, and applicable to real-world scenarios, thus facilitating breakthroughs in various fields such as healthcare and finance.
MEDPNet: Achieving High-Precision Adaptive Registration for Complex Die Castings
Mar 15, 2024



Due to their complex spatial structure and diverse geometric features, achieving high-precision and robust point cloud registration for complex Die Castings has been a significant challenge in the die-casting industry. Existing point cloud registration methods primarily optimize network models using well-established high-quality datasets, often neglecting practical application in real scenarios. To address this gap, this paper proposes a high-precision adaptive registration method called Multiscale Efficient Deep Closest Point (MEDPNet) and introduces a die-casting point cloud dataset, DieCastCloud, specifically designed to tackle the challenges of point cloud registration in the die-casting industry. The MEDPNet method performs coarse die-casting point cloud data registration using the Efficient-DCP method, followed by precision registration using the Multiscale feature fusion dual-channel registration (MDR) method. We enhance the modeling capability and computational efficiency of the model by replacing the attention mechanism of the Transformer in DCP with Efficient Attention and implementing a collaborative scale mechanism through the combination of serial and parallel blocks. Additionally, we propose the MDR method, which utilizes multilayer perceptrons (MLP), Normal Distributions Transform (NDT), and Iterative Closest Point (ICP) to achieve learnable adaptive fusion, enabling high-precision, scalable, and noise-resistant global point cloud registration. Our proposed method demonstrates excellent performance compared to state-of-the-art geometric and learning-based registration methods when applied to complex die-casting point cloud data.