 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM-based Document-level Machine Translation with Multi-Knowledge Fusion
Mar 15, 2025



Recent studies in prompting large language model (LLM) for document-level machine translation (DMT) primarily focus on the inter-sentence context by flatting the source document into a long sequence. This approach relies solely on the sequence of sentences within the document. However, the complexity of document-level sequences is greater than that of shorter sentence-level sequences, which may limit LLM's ability in DMT when only this single-source knowledge is used. In this paper, we propose an enhanced approach by incorporating multiple sources of knowledge, including both the document summarization and entity translation, to enhance the performance of LLM-based DMT. Given a source document, we first obtain its summarization and translation of entities via LLM as the additional knowledge. We then utilize LLMs to generate two translations of the source document by fusing these two single knowledge sources, respectively. Finally, recognizing that different sources of knowledge may aid or hinder the translation of different sentences, we refine and rank the translations by leveraging a multi-knowledge fusion strategy to ensure the best results. Experimental results in eight document-level translation tasks show that our approach achieves an average improvement of 0.8, 0.6, and 0.4 COMET scores over the baseline without extra knowledge for LLaMA3-8B-Instruct, Mistral-Nemo-Instruct, and GPT-4o-mini, respectively.
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025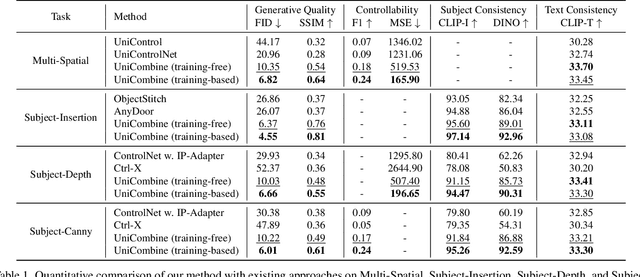
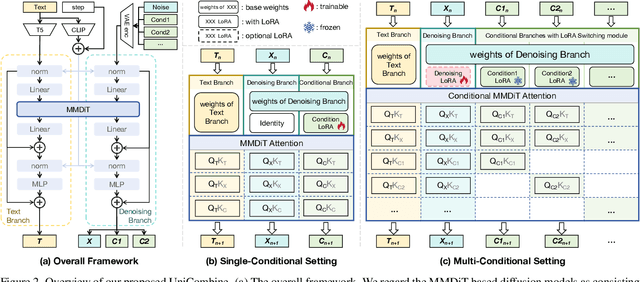
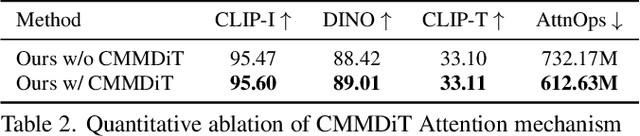
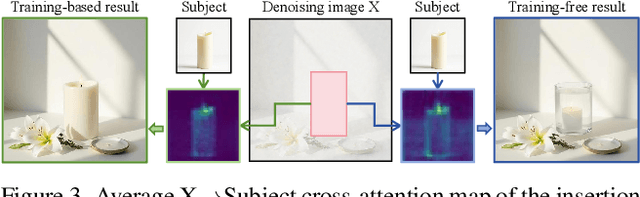
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
Raccoon: Multi-stage Diffusion Training with Coarse-to-Fine Curating Videos
Feb 28, 2025



Text-to-video generation has demonstrated promising progress with the advent of diffusion models, yet existing approaches are limited by dataset quality and computational resources. To address these limitations, this paper presents a comprehensive approach that advances both data curation and model design. We introduce CFC-VIDS-1M, a high-quality video dataset constructed through a systematic coarse-to-fine curation pipeline. The pipeline first evaluates video quality across multiple dimensions, followed by a fine-grained stage that leverages vision-language models to enhance text-video alignment and semantic richness. Building upon the curated dataset's emphasis on visual quality and temporal coherence, we develop RACCOON, a transformer-based architecture with decoupled spatial-temporal attention mechanisms. The model is trained through a progressive four-stage strategy designed to efficiently handle the complexities of video generation. Extensive experiments demonstrate that our integrated approach of high-quality data curation and efficient training strategy generates visually appealing and temporally coherent videos while maintaining computational efficiency. We will release our dataset, code, and models.
Alleviating Distribution Shift in Synthetic Data for Machine Translation Quality Estimation
Feb 28, 2025Quality Estimation (QE) models evaluate the quality of machine translations without reference translations, serving as the reward models for the translation task. Due to the data scarcity, synthetic data generation has emerged as a promising solution. However, synthetic QE data often suffers from distribution shift, which can manifest as discrepancies between pseudo and real translations, or in pseudo labels that do not align with human preferences. To tackle this issue, we introduce ADSQE, a novel framework for alleviating distribution shift in synthetic QE data. To reduce the difference between pseudo and real translations, we employ the constrained beam search algorithm and enhance translation diversity through the use of distinct generation models. ADSQE uses references, i.e., translation supervision signals, to guide both the generation and annotation processes, enhancing the quality of word-level labels. ADSE further identifies the shortest phrase covering consecutive error tokens, mimicking human annotation behavior, to assign the final phrase-level labels. Specially, we underscore that the translation model can not annotate translations of itself accurately. Extensive experiments demonstrate that ADSQE outperforms SOTA baselines like COMET in both supervised and unsupervised settings. Further analysis offers insights into synthetic data generation that could benefit reward models for other tasks.
R1-T1: Fully Incentivizing Translation Capability in LLMs via Reasoning Learning
Feb 27, 2025



Despite recent breakthroughs in reasoning-enhanced large language models (LLMs) like DeepSeek-R1, incorporating inference-time reasoning into machine translation (MT), where human translators naturally employ structured, multi-layered reasoning chain-of-thoughts (CoTs), is yet underexplored. Existing methods either design a fixed CoT tailored for a specific MT sub-task (e.g., literature translation), or rely on synthesizing CoTs unaligned with humans and supervised fine-tuning (SFT) prone to catastrophic forgetting, limiting their adaptability to diverse translation scenarios. This paper introduces R1-Translator (R1-T1), a novel framework to achieve inference-time reasoning for general MT via reinforcement learning (RL) with human-aligned CoTs comprising six common patterns. Our approach pioneers three innovations: (1) extending reasoning-based translation beyond MT sub-tasks to six languages and diverse tasks (e.g., legal/medical domain adaptation, idiom resolution); (2) formalizing six expert-curated CoT templates that mirror hybrid human strategies like context-aware paraphrasing and back translation; and (3) enabling self-evolving CoT discovery and anti-forgetting adaptation through RL with KL-constrained rewards. Experimental results indicate a steady translation performance improvement in 21 languages and 80 translation directions on Flores-101 test set, especially on the 15 languages unseen from training, with its general multilingual abilities preserved compared with plain SFT.
Chain-of-Description: What I can understand, I can put into words
Feb 22, 2025



In this paper, we propose a novel strategy defined as Chain-of-Description (CoD) Prompting, tailored for Multi-Modal Large Language Models. This approach involves having the model first provide a detailed description of the multi-modal input before generating an answer to the question. When applied to models such as Qwen2-Audio, Qwen2-VL, and Qwen2.5-VL, CoD Prompting significantly enhances performance compared to standard prompting methods. This is demonstrated by nearly a 4\% improvement in the speech category of the audio benchmark AIR-Bench-Chat and a 5.3\% improvement in the hard-level portion of the vision benchmark MMMU\_Pro. Our ablation study further validates the effectiveness of CoD Prompting.
Enhancing Speech Large Language Models with Prompt-Aware Mixture of Audio Encoders
Feb 21, 2025Connecting audio encoders with large language models (LLMs) allows the LLM to perform various audio understanding tasks, such as automatic speech recognition (ASR) and audio captioning (AC). Most research focuses on training an adapter layer to generate a unified audio feature for the LLM. However, different tasks may require distinct features that emphasize either semantic or acoustic aspects, making task-specific audio features more desirable. In this paper, we propose Prompt-aware Mixture (PaM) to enhance the Speech LLM that uses multiple audio encoders. Our approach involves using different experts to extract different features based on the prompt that indicates different tasks. Experiments demonstrate that with PaM, only one Speech LLM surpasses the best performances achieved by all single-encoder Speech LLMs on ASR, Speaker Number Verification, and AC tasks. PaM also outperforms other feature fusion baselines, such as concatenation and averaging.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
A Survey on Video Analytics in Cloud-Edge-Terminal Collaborative Systems
Feb 10, 2025


The explosive growth of video data has driven the development of distributed video analytics in cloud-edge-terminal collaborative (CETC) systems, enabling efficient video processing, real-time inference, and privacy-preserving analysis. Among multiple advantages, CETC systems can distribute video processing tasks and enable adaptive analytics across cloud, edge, and terminal devices, leading to breakthroughs in video surveillance, autonomous driving, and smart cities. In this survey, we first analyze fundamental architectural components, including hierarchical, distributed, and hybrid frameworks, alongside edge computing platforms and resource management mechanisms. Building upon these foundations, edge-centric approaches emphasize on-device processing, edge-assisted offloading, and edge intelligence, while cloud-centric methods leverage powerful computational capabilities for complex video understanding and model training. Our investigation also covers hybrid video analytics incorporating adaptive task offloading and resource-aware scheduling techniques that optimize performance across the entire system. Beyond conventional approaches, recent advances in large language models and multimodal integration reveal both opportunities and challenges in platform scalability, data protection, and system reliability. Future directions also encompass explainable systems, efficient processing mechanisms, and advanced video analytics, offering valuable insights for researchers and practitioners in this dynamic field.
Gravity Compensation of the dVRK-Si Patient Side Manipulator based on Dynamic Model Identification
Jan 31, 2025The da Vinci Research Kit (dVRK, also known as dVRK Classic) is an open-source teleoperated surgical robotic system whose hardware is obtained from the first generation da Vinci Surgical System (Intuitive, Sunnyvale, CA, USA). The dVRK has greatly facilitated research in robot-assisted surgery over the past decade and helped researchers address multiple major challenges in this domain. Recently, the dVRK-Si system, a new version of the dVRK which uses mechanical components from the da Vinci Si Surgical System, became available to the community. The major difference between the first generation da Vinci and the da Vinci Si is in the structural upgrade of the Patient Side Manipulator (PSM). Because of this upgrade, the gravity of the dVRK-Si PSM can no longer be ignored as in the dVRK Classic. The high gravity offset may lead to relatively low control accuracy and longer response time. In addition, although substantial progress has been made in addressing the dynamic model identification problem for the dVRK Classic, further research is required on model-based control for the dVRK-Si, due to differences in mechanical components and the demand for enhanced control performance. To address these problems, in this work, we present (1) a novel full kinematic model of the dVRK-Si PSM, and (2) a gravity compensation approach based on the dynamic model identification.