 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPS3D: End-to-End Feed-Forward 3D Panoptic Segmentation
Jun 08, 2026This paper introduces EPS3D, a new end-to-end feed-forward framework for open-vocabulary 3D panoptic segmentation. Unlike existing methods relying on additional preprocessing, we design an end-to-end architecture, with a distillation-based training strategy on diverse 3D scenes to predict 3D-aware semantic and instance features from multi-view images, improving 3D consistency and avoiding error accumulation. We further propose a mutual enhancement module to enforce inherent semantic-instance consistency. By aligning semantics within instances (Ins2Sem) and refining instance features with semantic guidance (Sem2Ins), we achieve more coherent 3D scene understanding. Ultimately, EPS3D outperforms SOTA baselines on two benchmarks (e.g., +13% mIoU for semantics on Replica) with high efficiency (e.g., 1s per scene), supporting tasks like robotic manipulation and 3D scene editing.
The GaoYao Benchmark: A Comprehensive Framework for Evaluating Multilingual and Multicultural Abilities of Large Language Models
Apr 22, 2026Evaluating the multilingual and multicultural capabilities of Large Language Models (LLMs) is essential for their global utility. However, current benchmarks face three critical limitations: (1) fragmented evaluation dimensions that often neglect deep cultural nuances; (2) insufficient language coverage in subjective tasks relying on low-quality machine translation; and (3) shallow analysis that lacks diagnostic depth beyond simple rankings. To address these, we introduce GaoYao, a comprehensive benchmark with 182.3k samples, 26 languages and 51 nations/areas. First, GaoYao proposes a unified framework categorizing evaluation tasks into three cultural layers (General Multilingual, Cross-cultural, Monocultural) and nine cognitive sub-layers. Second, we achieve native-quality expansion by leveraging experts to rigorously localize subjective benchmarks into 19 languages and synthesizing cross-cultural test sets for 34 cultures, surpassing prior coverage by up to 111%. Third, we conduct an in-depth diagnostic analysis on 20+ flagship and compact LLMs. Our findings reveal significant geographical performance disparities and distinct gaps between tasks, offering a reliable map for future work. We release the benchmark (https://github.com/lunyiliu/GaoYao).
Surg$Σ$: A Spectrum of Large-Scale Multimodal Data and Foundation Models for Surgical Intelligence
Mar 17, 2026Surgical intelligence has the potential to improve the safety and consistency of surgical care, yet most existing surgical AI frameworks remain task-specific and struggle to generalize across procedures and institutions. Although multimodal foundation models, particularly multimodal large language models, have demonstrated strong cross-task capabilities across various medical domains, their advancement in surgery remains constrained by the lack of large-scale, systematically curated multimodal data. To address this challenge, we introduce Surg$Σ$, a spectrum of large-scale multimodal data and foundation models for surgical intelligence. At the core of this framework lies Surg$Σ$-DB, a large-scale multimodal data foundation designed to support diverse surgical tasks. Surg$Σ$-DB consolidates heterogeneous surgical data sources (including open-source datasets, curated in-house clinical collections and web-source data) into a unified schema, aiming to improve label consistency and data standardization across heterogeneous datasets. Surg$Σ$-DB spans 6 clinical specialties and diverse surgical types, providing rich image- and video-level annotations across 18 practical surgical tasks covering understanding, reasoning, planning, and generation, at an unprecedented scale (over 5.98M conversations). Beyond conventional multimodal conversations, Surg$Σ$-DB incorporates hierarchical reasoning annotations, providing richer semantic cues to support deeper contextual understanding in complex surgical scenarios. We further provide empirical evidence through recently developed surgical foundation models built upon Surg$Σ$-DB, illustrating the practical benefits of large-scale multimodal annotations, unified semantic design, and structured reasoning annotations for improving cross-task generalization and interpretability.
Mem-T: Densifying Rewards for Long-Horizon Memory Agents
Jan 30, 2026Memory agents, which depart from predefined memory-processing pipelines by endogenously managing the processing, storage, and retrieval of memories, have garnered increasing attention for their autonomy and adaptability. However, existing training paradigms remain constrained: agents often traverse long-horizon sequences of memory operations before receiving sparse and delayed rewards, which hinders truly end-to-end optimization of memory management policies. To address this limitation, we introduce Mem-T, an autonomous memory agent that interfaces with a lightweight hierarchical memory database to perform dynamic updates and multi-turn retrieval over streaming inputs. To effectively train long-horizon memory management capabilities, we further propose MoT-GRPO, a tree-guided reinforcement learning framework that transforms sparse terminal feedback into dense, step-wise supervision via memory operation tree backpropagation and hindsight credit assignment, thereby enabling the joint optimization of memory construction and retrieval. Extensive experiments demonstrate that Mem-T is (1) high-performing, surpassing frameworks such as A-Mem and Mem0 by up to $14.92\%$, and (2) economical, operating on a favorable accuracy-efficiency Pareto frontier and reducing inference tokens per query by $\sim24.45\%$ relative to GAM without sacrificing performance.
Memory in the Age of AI Agents
Dec 15, 2025Memory has emerged, and will continue to remain, a core capability of foundation model-based agents. As research on agent memory rapidly expands and attracts unprecedented attention, the field has also become increasingly fragmented. Existing works that fall under the umbrella of agent memory often differ substantially in their motivations, implementations, and evaluation protocols, while the proliferation of loosely defined memory terminologies has further obscured conceptual clarity. Traditional taxonomies such as long/short-term memory have proven insufficient to capture the diversity of contemporary agent memory systems. This work aims to provide an up-to-date landscape of current agent memory research. We begin by clearly delineating the scope of agent memory and distinguishing it from related concepts such as LLM memory, retrieval augmented generation (RAG), and context engineering. We then examine agent memory through the unified lenses of forms, functions, and dynamics. From the perspective of forms, we identify three dominant realizations of agent memory, namely token-level, parametric, and latent memory. From the perspective of functions, we propose a finer-grained taxonomy that distinguishes factual, experiential, and working memory. From the perspective of dynamics, we analyze how memory is formed, evolved, and retrieved over time. To support practical development, we compile a comprehensive summary of memory benchmarks and open-source frameworks. Beyond consolidation, we articulate a forward-looking perspective on emerging research frontiers, including memory automation, reinforcement learning integration, multimodal memory, multi-agent memory, and trustworthiness issues. We hope this survey serves not only as a reference for existing work, but also as a conceptual foundation for rethinking memory as a first-class primitive in the design of future agentic intelligence.
EndoWave: Rational-Wavelet 4D Gaussian Splatting for Endoscopic Reconstruction
Oct 27, 2025In robot-assisted minimally invasive surgery, accurate 3D reconstruction from endoscopic video is vital for downstream tasks and improved outcomes. However, endoscopic scenarios present unique challenges, including photometric inconsistencies, non-rigid tissue motion, and view-dependent highlights. Most 3DGS-based methods that rely solely on appearance constraints for optimizing 3DGS are often insufficient in this context, as these dynamic visual artifacts can mislead the optimization process and lead to inaccurate reconstructions. To address these limitations, we present EndoWave, a unified spatio-temporal Gaussian Splatting framework by incorporating an optical flow-based geometric constraint and a multi-resolution rational wavelet supervision. First, we adopt a unified spatio-temporal Gaussian representation that directly optimizes primitives in a 4D domain. Second, we propose a geometric constraint derived from optical flow to enhance temporal coherence and effectively constrain the 3D structure of the scene. Third, we propose a multi-resolution rational orthogonal wavelet as a constraint, which can effectively separate the details of the endoscope and enhance the rendering performance. Extensive evaluations on two real surgical datasets, EndoNeRF and StereoMIS, demonstrate that our method EndoWave achieves state-of-the-art reconstruction quality and visual accuracy compared to the baseline method.
Align-then-Slide: A complete evaluation framework for Ultra-Long Document-Level Machine Translation
Sep 04, 2025



Large language models (LLMs) have ushered in a new era for document-level machine translation (\textit{doc}-mt), yet their whole-document outputs challenge existing evaluation methods that assume sentence-by-sentence alignment. We introduce \textit{\textbf{Align-then-Slide}}, a complete evaluation framework for ultra-long doc-mt. In the Align stage, we automatically infer sentence-level source-target correspondences and rebuild the target to match the source sentence number, resolving omissions and many-to-one/one-to-many mappings. In the n-Chunk Sliding Evaluate stage, we calculate averaged metric scores under 1-, 2-, 3- and 4-chunk for multi-granularity assessment. Experiments on the WMT benchmark show a Pearson correlation of 0.929 between our method with expert MQM rankings. On a newly curated real-world test set, our method again aligns closely with human judgments. Furthermore, preference data produced by Align-then-Slide enables effective CPO training and its direct use as a reward model for GRPO, both yielding translations preferred over a vanilla SFT baseline. The results validate our framework as an accurate, robust, and actionable evaluation tool for doc-mt systems.
Generative Annotation for ASR Named Entity Correction
Aug 28, 2025

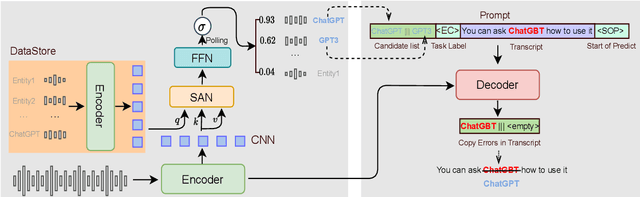
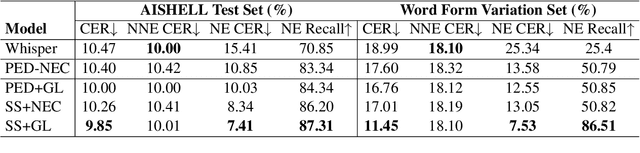
End-to-end automatic speech recognition systems often fail to transcribe domain-specific named entities, causing catastrophic failures in downstream tasks. Numerous fast and lightweight named entity correction (NEC) models have been proposed in recent years. These models, mainly leveraging phonetic-level edit distance algorithms, have shown impressive performances. However, when the forms of the wrongly-transcribed words(s) and the ground-truth entity are significantly different, these methods often fail to locate the wrongly transcribed words in hypothesis, thus limiting their usage. We propose a novel NEC method that utilizes speech sound features to retrieve candidate entities. With speech sound features and candidate entities, we inovatively design a generative method to annotate entity errors in ASR transcripts and replace the text with correct entities. This method is effective in scenarios of word form difference. We test our method using open-source and self-constructed test sets. The results demonstrate that our NEC method can bring significant improvement to entity accuracy. We will open source our self-constructed test set and training data.
OmniDepth: Bridging Monocular and Stereo Reasoning with Latent Alignment
Aug 06, 2025Monocular and stereo depth estimation offer complementary strengths: monocular methods capture rich contextual priors but lack geometric precision, while stereo approaches leverage epipolar geometry yet struggle with ambiguities such as reflective or textureless surfaces. Despite post-hoc synergies, these paradigms remain largely disjoint in practice. We introduce OmniDepth, a unified framework that bridges both through iterative bidirectional alignment of their latent representations. At its core, a novel cross-attentive alignment mechanism dynamically synchronizes monocular contextual cues with stereo hypothesis representations during stereo reasoning. This mutual alignment resolves stereo ambiguities (e.g., specular surfaces) by injecting monocular structure priors while refining monocular depth with stereo geometry within a single network. Extensive experiments demonstrate state-of-the-art results: \textbf{OmniDepth reduces zero-shot generalization error by $\!>\!40\%$ on Middlebury and ETH3D}, while addressing longstanding failures on transparent and reflective surfaces. By harmonizing multi-view geometry with monocular context, OmniDepth enables robust 3D perception that transcends modality-specific limitations. Codes available at https://github.com/aeolusguan/OmniDepth.
MGVQ: Could VQ-VAE Beat VAE? A Generalizable Tokenizer with Multi-group Quantization
Jul 10, 2025



Vector Quantized Variational Autoencoders (VQ-VAEs) are fundamental models that compress continuous visual data into discrete tokens. Existing methods have tried to improve the quantization strategy for better reconstruction quality, however, there still exists a large gap between VQ-VAEs and VAEs. To narrow this gap, we propose \NickName, a novel method to augment the representation capability of discrete codebooks, facilitating easier optimization for codebooks and minimizing information loss, thereby enhancing reconstruction quality. Specifically, we propose to retain the latent dimension to preserve encoded features and incorporate a set of sub-codebooks for quantization. Furthermore, we construct comprehensive zero-shot benchmarks featuring resolutions of 512p and 2k to evaluate the reconstruction performance of existing methods rigorously. \NickName~achieves the \textbf{state-of-the-art performance on both ImageNet and $8$ zero-shot benchmarks} across all VQ-VAEs. Notably, compared with SD-VAE, we outperform them on ImageNet significantly, with rFID $\textbf{0.49}$ v.s. $\textbf{0.91}$, and achieve superior PSNR on all zero-shot benchmarks. These results highlight the superiority of \NickName~in reconstruction and pave the way for preserving fidelity in HD image processing tasks. Code will be publicly available at https://github.com/MKJia/MGVQ.