 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Woofs to Words: Towards Intelligent Robotic Guide Dogs with Verbal Communication
Mar 13, 2026Assistive robotics is an important subarea of robotics that focuses on the well-being of people with disabilities. A robotic guide dog is an assistive quadruped robot that helps visually impaired people in obstacle avoidance and navigation. Enabling language capabilities for robotic guide dogs goes beyond naively adding an existing dialog system onto a mobile robot. The novel challenges include grounding language in the dynamically changing environment and improving spatial awareness for the human handler. To address those challenges, we develop a novel dialog system for robotic guide dogs that uses LLMs to verbalize both navigational plans and scenes. The goal is to enable verbal communication for collaborative decision-making within the handler-robot team. In experiments, we conducted a human study to evaluate different verbalization strategies and a simulation study to assess the efficiency and accuracy in navigation tasks.
LLM-GROP: Visually Grounded Robot Task and Motion Planning with Large Language Models
Nov 11, 2025Task planning and motion planning are two of the most important problems in robotics, where task planning methods help robots achieve high-level goals and motion planning methods maintain low-level feasibility. Task and motion planning (TAMP) methods interleave the two processes of task planning and motion planning to ensure goal achievement and motion feasibility. Within the TAMP context, we are concerned with the mobile manipulation (MoMa) of multiple objects, where it is necessary to interleave actions for navigation and manipulation. In particular, we aim to compute where and how each object should be placed given underspecified goals, such as ``set up dinner table with a fork, knife and plate.'' We leverage the rich common sense knowledge from large language models (LLMs), e.g., about how tableware is organized, to facilitate both task-level and motion-level planning. In addition, we use computer vision methods to learn a strategy for selecting base positions to facilitate MoMa behaviors, where the base position corresponds to the robot's ``footprint'' and orientation in its operating space. Altogether, this article provides a principled TAMP framework for MoMa tasks that accounts for common sense about object rearrangement and is adaptive to novel situations that include many objects that need to be moved. We performed quantitative experiments in both real-world settings and simulated environments. We evaluated the success rate and efficiency in completing long-horizon object rearrangement tasks. While the robot completed 84.4\% real-world object rearrangement trials, subjective human evaluations indicated that the robot's performance is still lower than experienced human waiters.
Fuzzy-UCS Revisited: Self-Adaptation of Rule Representations in Michigan-Style Learning Fuzzy-Classifier Systems
May 09, 2025



This paper focuses on the impact of rule representation in Michigan-style Learning Fuzzy-Classifier Systems (LFCSs) on its classification performance. A well-representation of the rules in an LFCS is crucial for improving its performance. However, conventional rule representations frequently need help addressing problems with unknown data characteristics. To address this issue, this paper proposes a supervised LFCS (i.e., Fuzzy-UCS) with a self-adaptive rule representation mechanism, entitled Adaptive-UCS. Adaptive-UCS incorporates a fuzzy indicator as a new rule parameter that sets the membership function of a rule as either rectangular (i.e., crisp) or triangular (i.e., fuzzy) shapes. The fuzzy indicator is optimized with evolutionary operators, allowing the system to search for an optimal rule representation. Results from extensive experiments conducted on continuous space problems demonstrate that Adaptive-UCS outperforms other UCSs with conventional crisp-hyperrectangular and fuzzy-hypertrapezoidal rule representations in classification accuracy. Additionally, Adaptive-UCS exhibits robustness in the case of noisy inputs and real-world problems with inherent uncertainty, such as missing values, leading to stable classification performance.
DKPROMPT: Domain Knowledge Prompting Vision-Language Models for Open-World Planning
Jun 25, 2024Vision-language models (VLMs) have been applied to robot task planning problems, where the robot receives a task in natural language and generates plans based on visual inputs. While current VLMs have demonstrated strong vision-language understanding capabilities, their performance is still far from being satisfactory in planning tasks. At the same time, although classical task planners, such as PDDL-based, are strong in planning for long-horizon tasks, they do not work well in open worlds where unforeseen situations are common. In this paper, we propose a novel task planning and execution framework, called DKPROMPT, which automates VLM prompting using domain knowledge in PDDL for classical planning in open worlds. Results from quantitative experiments show that DKPROMPT outperforms classical planning, pure VLM-based and a few other competitive baselines in task completion rate.
Guided Dyna-Q for Mobile Robot Exploration and Navigation
Apr 23, 2020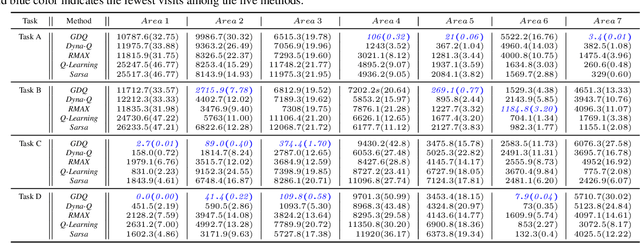
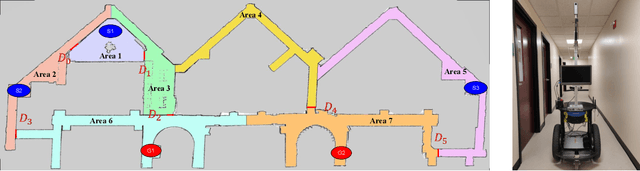
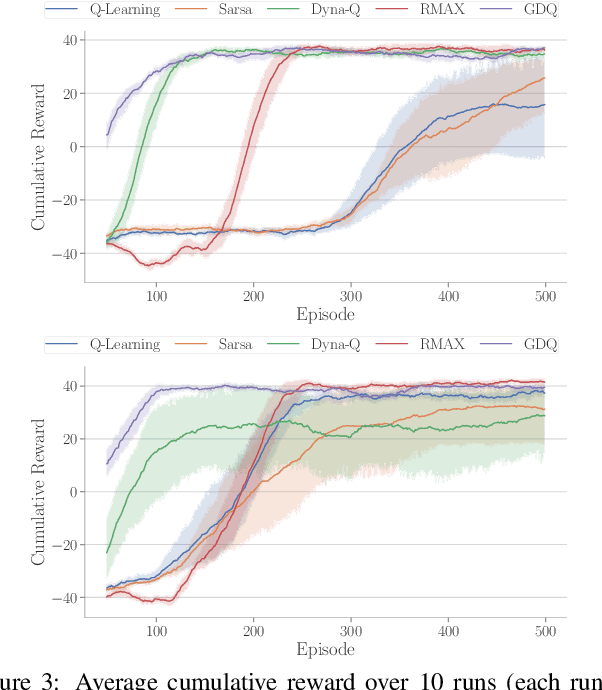
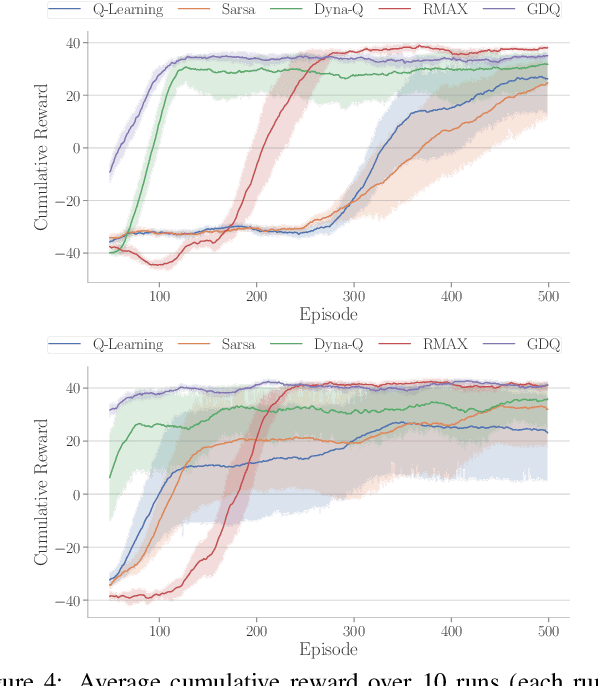
Model-based reinforcement learning (RL) enables an agent to learn world models from trial-and-error experiences toward achieving long-term goals. Automated planning, on the other hand, can be used for accomplishing tasks through reasoning with declarative action knowledge. Despite their shared goal of completing complex tasks, the development of RL and automated planning has mainly been isolated due to their different modalities of computation. Focusing on improving model-based RL agent's exploration strategy and sample efficiency, we develop Guided Dyna-Q (GDQ) to enable RL agents to reason with action knowledge to avoid exploring less-relevant states toward more efficient task accomplishment. GDQ has been evaluated in simulation and using a mobile robot conducting navigation tasks in an office environment. Results show that GDQ reduces the effort in exploration while improving the quality of learned policies.