 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarSkip-Collective: Unhobbling Blocking Communication in Mixture of Experts Models
Nov 14, 2025



Blocking communication presents a major hurdle in running MoEs efficiently in distributed settings. To address this, we present FarSkip-Collective which modifies the architecture of modern models to enable overlapping of their computation with communication. Our approach modifies the architecture to skip connections in the model and it is unclear a priori whether the modified model architecture can remain as capable, especially for large state-of-the-art models and while modifying all of the model layers. We answer this question in the affirmative and fully convert a series of state-of-the-art models varying from 16B to 109B parameters to enable overlapping of their communication while achieving accuracy on par with their original open-source releases. For example, we convert Llama 4 Scout (109B) via self-distillation and achieve average accuracy within 1% of its instruction tuned release averaged across a wide range of downstream evaluations. In addition to demonstrating retained accuracy of the large modified models, we realize the benefits of FarSkip-Collective through optimized implementations that explicitly overlap communication with computation, accelerating both training and inference in existing frameworks.
NAVERO: Unlocking Fine-Grained Semantics for Video-Language Compositionality
Aug 18, 2024



We study the capability of Video-Language (VidL) models in understanding compositions between objects, attributes, actions and their relations. Composition understanding becomes particularly challenging for video data since the compositional relations rapidly change over time in videos. We first build a benchmark named AARO to evaluate composition understanding related to actions on top of spatial concepts. The benchmark is constructed by generating negative texts with incorrect action descriptions for a given video and the model is expected to pair a positive text with its corresponding video. Furthermore, we propose a training method called NAVERO which utilizes video-text data augmented with negative texts to enhance composition understanding. We also develop a negative-augmented visual-language matching loss which is used explicitly to benefit from the generated negative text. We compare NAVERO with other state-of-the-art methods in terms of compositional understanding as well as video-text retrieval performance. NAVERO achieves significant improvement over other methods for both video-language and image-language composition understanding, while maintaining strong performance on traditional text-video retrieval tasks.
B'MOJO: Hybrid State Space Realizations of Foundation Models with Eidetic and Fading Memory
Jul 08, 2024We describe a family of architectures to support transductive inference by allowing memory to grow to a finite but a-priori unknown bound while making efficient use of finite resources for inference. Current architectures use such resources to represent data either eidetically over a finite span ("context" in Transformers), or fading over an infinite span (in State Space Models, or SSMs). Recent hybrid architectures have combined eidetic and fading memory, but with limitations that do not allow the designer or the learning process to seamlessly modulate the two, nor to extend the eidetic memory span. We leverage ideas from Stochastic Realization Theory to develop a class of models called B'MOJO to seamlessly combine eidetic and fading memory within an elementary composable module. The overall architecture can be used to implement models that can access short-term eidetic memory "in-context," permanent structural memory "in-weights," fading memory "in-state," and long-term eidetic memory "in-storage" by natively incorporating retrieval from an asynchronously updated memory. We show that Transformers, existing SSMs such as Mamba, and hybrid architectures such as Jamba are special cases of B'MOJO and describe a basic implementation, to be open sourced, that can be stacked and scaled efficiently in hardware. We test B'MOJO on transductive inference tasks, such as associative recall, where it outperforms existing SSMs and Hybrid models; as a baseline, we test ordinary language modeling where B'MOJO achieves perplexity comparable to similarly-sized Transformers and SSMs up to 1.4B parameters, while being up to 10% faster to train. Finally, we show that B'MOJO's ability to modulate eidetic and fading memory results in better inference on longer sequences tested up to 32K tokens, four-fold the length of the longest sequences seen during training.
THRONE: An Object-based Hallucination Benchmark for the Free-form Generations of Large Vision-Language Models
May 08, 2024Mitigating hallucinations in large vision-language models (LVLMs) remains an open problem. Recent benchmarks do not address hallucinations in open-ended free-form responses, which we term "Type I hallucinations". Instead, they focus on hallucinations responding to very specific question formats -- typically a multiple-choice response regarding a particular object or attribute -- which we term "Type II hallucinations". Additionally, such benchmarks often require external API calls to models which are subject to change. In practice, we observe that a reduction in Type II hallucinations does not lead to a reduction in Type I hallucinations but rather that the two forms of hallucinations are often anti-correlated. To address this, we propose THRONE, a novel object-based automatic framework for quantitatively evaluating Type I hallucinations in LVLM free-form outputs. We use public language models (LMs) to identify hallucinations in LVLM responses and compute informative metrics. By evaluating a large selection of recent LVLMs using public datasets, we show that an improvement in existing metrics do not lead to a reduction in Type I hallucinations, and that established benchmarks for measuring Type I hallucinations are incomplete. Finally, we provide a simple and effective data augmentation method to reduce Type I and Type II hallucinations as a strong baseline.
SAFE: Machine Unlearning With Shard Graphs
Apr 25, 2023We present Synergy Aware Forgetting Ensemble (SAFE), a method to adapt large models on a diverse collection of data while minimizing the expected cost to remove the influence of training samples from the trained model. This process, also known as selective forgetting or unlearning, is often conducted by partitioning a dataset into shards, training fully independent models on each, then ensembling the resulting models. Increasing the number of shards reduces the expected cost to forget but at the same time it increases inference cost and reduces the final accuracy of the model since synergistic information between samples is lost during the independent model training. Rather than treating each shard as independent, SAFE introduces the notion of a shard graph, which allows incorporating limited information from other shards during training, trading off a modest increase in expected forgetting cost with a significant increase in accuracy, all while still attaining complete removal of residual influence after forgetting. SAFE uses a lightweight system of adapters which can be trained while reusing most of the computations. This allows SAFE to be trained on shards an order-of-magnitude smaller than current state-of-the-art methods (thus reducing the forgetting costs) while also maintaining high accuracy, as we demonstrate empirically on fine-grained computer vision datasets.
Learning Expressive Prompting With Residuals for Vision Transformers
Mar 27, 2023Prompt learning is an efficient approach to adapt transformers by inserting learnable set of parameters into the input and intermediate representations of a pre-trained model. In this work, we present Expressive Prompts with Residuals (EXPRES) which modifies the prompt learning paradigm specifically for effective adaptation of vision transformers (ViT). Out method constructs downstream representations via learnable ``output'' tokens, that are akin to the learned class tokens of the ViT. Further for better steering of the downstream representation processed by the frozen transformer, we introduce residual learnable tokens that are added to the output of various computations. We apply EXPRES for image classification, few shot learning, and semantic segmentation, and show our method is capable of achieving state of the art prompt tuning on 3/3 categories of the VTAB benchmark. In addition to strong performance, we observe that our approach is an order of magnitude more prompt efficient than existing visual prompting baselines. We analytically show the computational benefits of our approach over weight space adaptation techniques like finetuning. Lastly we systematically corroborate the architectural design of our method via a series of ablation experiments.
Introspective Cross-Attention Probing for Lightweight Transfer of Pre-trained Models
Mar 07, 2023



We propose InCA, a lightweight method for transfer learning that cross-attends to any activation layer of a pre-trained model. During training, InCA uses a single forward pass to extract multiple activations, which are passed to external cross-attention adapters, trained anew and combined or selected for downstream tasks. We show that, even when selecting a single top-scoring adapter, InCA achieves performance comparable to full fine-tuning, at a cost comparable to fine-tuning just the last layer. For example, with a cross-attention probe 1.3% the size of a pre-trained ViT-L/16 model, we achieve performance within 0.2% of the full fine-tuning paragon at 51% training cost of the baseline, on average across 11 downstream classification tasks. Unlike other forms of efficient adaptation, InCA does not require backpropagating through the pre-trained model, thus leaving its execution unaltered at both training and inference. The versatility of InCA is best illustrated in fine-grained tasks, which may require accessing information absent in the last layer but accessible in intermediate layer activations. Since the backbone is fixed, InCA allows parallel ensembling as well as parallel execution of multiple tasks. InCA achieves state-of-the-art performance in the ImageNet-to-Sketch multi-task benchmark.
DIVA: Dataset Derivative of a Learning Task
Nov 18, 2021
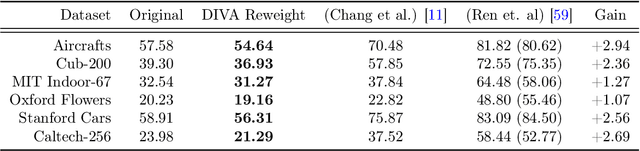

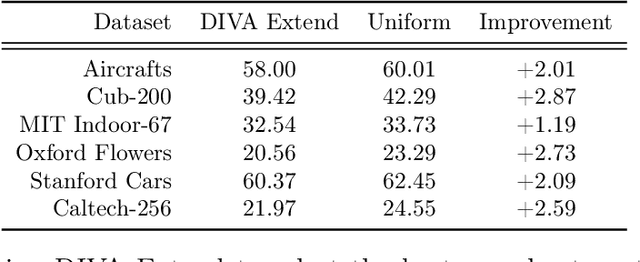
We present a method to compute the derivative of a learning task with respect to a dataset. A learning task is a function from a training set to the validation error, which can be represented by a trained deep neural network (DNN). The "dataset derivative" is a linear operator, computed around the trained model, that informs how perturbations of the weight of each training sample affect the validation error, usually computed on a separate validation dataset. Our method, DIVA (Differentiable Validation) hinges on a closed-form differentiable expression of the leave-one-out cross-validation error around a pre-trained DNN. Such expression constitutes the dataset derivative. DIVA could be used for dataset auto-curation, for example removing samples with faulty annotations, augmenting a dataset with additional relevant samples, or rebalancing. More generally, DIVA can be used to optimize the dataset, along with the parameters of the model, as part of the training process without the need for a separate validation dataset, unlike bi-level optimization methods customary in AutoML. To illustrate the flexibility of DIVA, we report experiments on sample auto-curation tasks such as outlier rejection, dataset extension, and automatic aggregation of multi-modal data.
Optimization Theory for ReLU Neural Networks Trained with Normalization Layers
Jun 11, 2020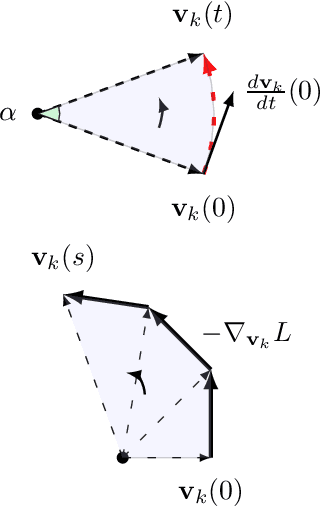
The success of deep neural networks is in part due to the use of normalization layers. Normalization layers like Batch Normalization, Layer Normalization and Weight Normalization are ubiquitous in practice, as they improve generalization performance and speed up training significantly. Nonetheless, the vast majority of current deep learning theory and non-convex optimization literature focuses on the un-normalized setting, where the functions under consideration do not exhibit the properties of commonly normalized neural networks. In this paper, we bridge this gap by giving the first global convergence result for two-layer neural networks with ReLU activations trained with a normalization layer, namely Weight Normalization. Our analysis shows how the introduction of normalization layers changes the optimization landscape and can enable faster convergence as compared with un-normalized neural networks.
Wasserstein Diffusion Tikhonov Regularization
Sep 15, 2019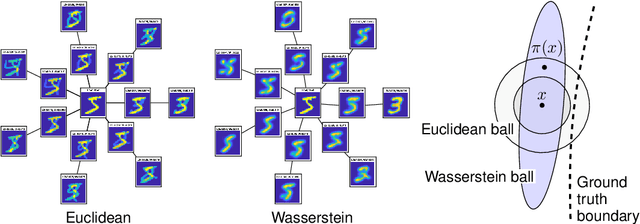


We propose regularization strategies for learning discriminative models that are robust to in-class variations of the input data. We use the Wasserstein-2 geometry to capture semantically meaningful neighborhoods in the space of images, and define a corresponding input-dependent additive noise data augmentation model. Expanding and integrating the augmented loss yields an effective Tikhonov-type Wasserstein diffusion smoothness regularizer. This approach allows us to apply high levels of regularization and train functions that have low variability within classes but remain flexible across classes. We provide efficient methods for computing the regularizer at a negligible cost in comparison to training with adversarial data augmentation. Initial experiments demonstrate improvements in generalization performance under adversarial perturbations and also large in-class variations of the input data.