 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoong: A Human-Like Long Document Translation Agent with Observe-and-Act Adaptive Context Selection
May 28, 2026Document-level translation remains one of the most challenging tasks for large language models, which are constrained by limited context windows that impede global cohesion, while simultaneously suffering from redundant contextual information that degrades translation quality. To address this, we propose a human-like long document translation agent called Loong, which leverages a 3E memory module (Essence-Exemplar-Entity) to store summaries, sentence pairs, and entity records as historical context. Instead of passively attending to all history, Loong performs deep reasoning to adaptively identify the optimal context for translation guidance. Loong optimizes its context policy through reinforcement learning, utilizing preference data derived from its own sampled observe-and-act reasoning trajectories. Empirical evaluations demonstrate that Loong achieves substantial translation quality improvements in English $\Leftrightarrow$ Chinese, German, and French directions, with average gains of up to 13.0 points across the three evaluation metrics. Furthermore, Loong exhibits strong generalization across domains and robustness against contextual noise, while maintaining remarkable stability in ultra-long document translation. Our code is released at https://github.com/YutongWang1216/LoongDocMT.
The GaoYao Benchmark: A Comprehensive Framework for Evaluating Multilingual and Multicultural Abilities of Large Language Models
Apr 22, 2026Evaluating the multilingual and multicultural capabilities of Large Language Models (LLMs) is essential for their global utility. However, current benchmarks face three critical limitations: (1) fragmented evaluation dimensions that often neglect deep cultural nuances; (2) insufficient language coverage in subjective tasks relying on low-quality machine translation; and (3) shallow analysis that lacks diagnostic depth beyond simple rankings. To address these, we introduce GaoYao, a comprehensive benchmark with 182.3k samples, 26 languages and 51 nations/areas. First, GaoYao proposes a unified framework categorizing evaluation tasks into three cultural layers (General Multilingual, Cross-cultural, Monocultural) and nine cognitive sub-layers. Second, we achieve native-quality expansion by leveraging experts to rigorously localize subjective benchmarks into 19 languages and synthesizing cross-cultural test sets for 34 cultures, surpassing prior coverage by up to 111%. Third, we conduct an in-depth diagnostic analysis on 20+ flagship and compact LLMs. Our findings reveal significant geographical performance disparities and distinct gaps between tasks, offering a reliable map for future work. We release the benchmark (https://github.com/lunyiliu/GaoYao).
Cross-Preference Learning for Sentence-Level and Context-Aware Machine Translation
Mar 26, 2026Context-aware machine translation (MT) leverages document-level information, yet it does not consistently outperform sentence-level MT, as contextual signals are unevenly beneficial across sentences. Existing training objectives do not explicitly model this variability, limiting a model's ability to adaptively exploit context. In this paper, we propose Cross-Preference Learning (CPL), a preference-based training framework that explicitly captures the complementary benefits of sentence-level and context-aware MT. CPL achieves this by integrating both intra- and cross-condition preferences into the preference optimization objective. The introduction of intra- and cross-condition preferences provides explicit supervision on when and how contextual information improves translation quality. We validate the proposed approach on several public context-aware MT tasks using multiple models, including Qwen3-4B, Qwen3-8B, and Llama-3-8B. Experimental results demonstrate consistent improvements in translation quality and robustness across both input conditions, achieved without any architectural modifications.
Global-Local Dual Perception for MLLMs in High-Resolution Text-Rich Image Translation
Feb 25, 2026Text Image Machine Translation (TIMT) aims to translate text embedded in images in the source-language into target-language, requiring synergistic integration of visual perception and linguistic understanding. Existing TIMT methods, whether cascaded pipelines or end-to-end multimodal large language models (MLLMs),struggle with high-resolution text-rich images due to cluttered layouts, diverse fonts, and non-textual distractions, resulting in text omission, semantic drift, and contextual inconsistency. To address these challenges, we propose GLoTran, a global-local dual visual perception framework for MLLM-based TIMT. GLoTran integrates a low-resolution global image with multi-scale region-level text image slices under an instruction-guided alignment strategy, conditioning MLLMs to maintain scene-level contextual consistency while faithfully capturing fine-grained textual details. Moreover, to realize this dual-perception paradigm, we construct GLoD, a large-scale text-rich TIMT dataset comprising 510K high-resolution global-local image-text pairs covering diverse real-world scenarios. Extensive experiments demonstrate that GLoTran substantially improves translation completeness and accuracy over state-of-the-art MLLMs, offering a new paradigm for fine-grained TIMT under high-resolution and text-rich conditions.
Towards Fine-Grained Code-Switch Speech Translation with Semantic Space Alignment
Nov 09, 2025Code-switching (CS) speech translation (ST) refers to translating speech that alternates between two or more languages into a target language text, which poses significant challenges due to the complexity of semantic modeling and the scarcity of CS data. Previous studies tend to rely on the model itself to implicitly learn semantic modeling during training, and resort to inefficient and costly manual annotations for these two challenges. To mitigate these limitations, we propose enhancing Large Language Models (LLMs) with a Mixture of Experts (MoE) speech projector, where each expert specializes in the semantic subspace of a specific language, enabling fine-grained modeling of speech features. Additionally, we introduce a multi-stage training paradigm that utilizes readily available monolingual automatic speech recognition (ASR) and monolingual ST data, facilitating speech-text alignment and improving translation capabilities. During training, we leverage a combination of language-specific loss and intra-group load balancing loss to guide the MoE speech projector in efficiently allocating tokens to the appropriate experts, across expert groups and within each group, respectively. To bridge the data gap across different training stages and improve adaptation to the CS scenario, we further employ a transition loss, enabling smooth transitions of data between stages, to effectively address the scarcity of high-quality CS speech translation data. Extensive experiments on widely used datasets demonstrate the effectiveness and generality of our approach.
A method for improving multilingual quality and diversity of instruction fine-tuning datasets
Sep 19, 2025Multilingual Instruction Fine-Tuning (IFT) is essential for enabling large language models (LLMs) to generalize effectively across diverse linguistic and cultural contexts. However, the scarcity of high-quality multilingual training data and corresponding building method remains a critical bottleneck. While data selection has shown promise in English settings, existing methods often fail to generalize across languages due to reliance on simplistic heuristics or language-specific assumptions. In this work, we introduce Multilingual Data Quality and Diversity (M-DaQ), a novel method for improving LLMs multilinguality, by selecting high-quality and semantically diverse multilingual IFT samples. We further conduct the first systematic investigation of the Superficial Alignment Hypothesis (SAH) in multilingual setting. Empirical results across 18 languages demonstrate that models fine-tuned with M-DaQ method achieve significant performance gains over vanilla baselines over 60% win rate. Human evaluations further validate these gains, highlighting the increment of cultural points in the response. We release the M-DaQ code to support future research.
RationAnomaly: Log Anomaly Detection with Rationality via Chain-of-Thought and Reinforcement Learning
Sep 18, 2025Logs constitute a form of evidence signaling the operational status of software systems. Automated log anomaly detection is crucial for ensuring the reliability of modern software systems. However, existing approaches face significant limitations: traditional deep learning models lack interpretability and generalization, while methods leveraging Large Language Models are often hindered by unreliability and factual inaccuracies. To address these issues, we propose RationAnomaly, a novel framework that enhances log anomaly detection by synergizing Chain-of-Thought (CoT) fine-tuning with reinforcement learning. Our approach first instills expert-like reasoning patterns using CoT-guided supervised fine-tuning, grounded in a high-quality dataset corrected through a rigorous expert-driven process. Subsequently, a reinforcement learning phase with a multi-faceted reward function optimizes for accuracy and logical consistency, effectively mitigating hallucinations. Experimentally, RationAnomaly outperforms state-of-the-art baselines, achieving superior F1-scores on key benchmarks while providing transparent, step-by-step analytical outputs. We have released the corresponding resources, including code and datasets.
Align-then-Slide: A complete evaluation framework for Ultra-Long Document-Level Machine Translation
Sep 04, 2025



Large language models (LLMs) have ushered in a new era for document-level machine translation (\textit{doc}-mt), yet their whole-document outputs challenge existing evaluation methods that assume sentence-by-sentence alignment. We introduce \textit{\textbf{Align-then-Slide}}, a complete evaluation framework for ultra-long doc-mt. In the Align stage, we automatically infer sentence-level source-target correspondences and rebuild the target to match the source sentence number, resolving omissions and many-to-one/one-to-many mappings. In the n-Chunk Sliding Evaluate stage, we calculate averaged metric scores under 1-, 2-, 3- and 4-chunk for multi-granularity assessment. Experiments on the WMT benchmark show a Pearson correlation of 0.929 between our method with expert MQM rankings. On a newly curated real-world test set, our method again aligns closely with human judgments. Furthermore, preference data produced by Align-then-Slide enables effective CPO training and its direct use as a reward model for GRPO, both yielding translations preferred over a vanilla SFT baseline. The results validate our framework as an accurate, robust, and actionable evaluation tool for doc-mt systems.
Generative Annotation for ASR Named Entity Correction
Aug 28, 2025

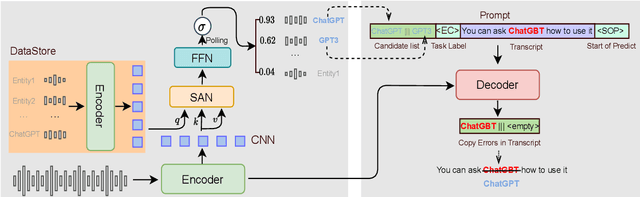
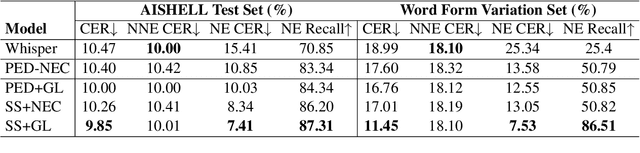
End-to-end automatic speech recognition systems often fail to transcribe domain-specific named entities, causing catastrophic failures in downstream tasks. Numerous fast and lightweight named entity correction (NEC) models have been proposed in recent years. These models, mainly leveraging phonetic-level edit distance algorithms, have shown impressive performances. However, when the forms of the wrongly-transcribed words(s) and the ground-truth entity are significantly different, these methods often fail to locate the wrongly transcribed words in hypothesis, thus limiting their usage. We propose a novel NEC method that utilizes speech sound features to retrieve candidate entities. With speech sound features and candidate entities, we inovatively design a generative method to annotate entity errors in ASR transcripts and replace the text with correct entities. This method is effective in scenarios of word form difference. We test our method using open-source and self-constructed test sets. The results demonstrate that our NEC method can bring significant improvement to entity accuracy. We will open source our self-constructed test set and training data.
MIDB: Multilingual Instruction Data Booster for Enhancing Multilingual Instruction Synthesis
May 23, 2025



Despite doubts on data quality, instruction synthesis has been widely applied into instruction tuning (IT) of LLMs as an economic and rapid alternative. Recent endeavors focus on improving data quality for synthesized instruction pairs in English and have facilitated IT of English-centric LLMs. However, data quality issues in multilingual synthesized instruction pairs are even more severe, since the common synthesizing practice is to translate English synthesized data into other languages using machine translation (MT). Besides the known content errors in these English synthesized data, multilingual synthesized instruction data are further exposed to defects introduced by MT and face insufficient localization of the target languages. In this paper, we propose MIDB, a Multilingual Instruction Data Booster to automatically address the quality issues in multilingual synthesized data. MIDB is trained on around 36.8k revision examples across 16 languages by human linguistic experts, thereby can boost the low-quality data by addressing content errors and MT defects, and improving localization in these synthesized data. Both automatic and human evaluation indicate that not only MIDB steadily improved instruction data quality in 16 languages, but also the instruction-following and cultural-understanding abilities of multilingual LLMs fine-tuned on MIDB-boosted data were significantly enhanced.