 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADE: Beyond Scoring via a Multilingual Agentic Diagnosing Engine for Fine-Grained Evaluation Insights
Jun 05, 2026Multilingual and multicultural benchmarks now cover dozens of languages and model families, but the resulting score landscapes remain metric-rich and insight-poor, necessitating fine-grained multilingual post-evaluation diagnosis. However, single LLMs and open-ended agents are easily swamped by the long, noisy diagnostic input, and no reusable taxonomy exists for it. To address this, we propose MADE, a Multilingual Agentic Diagnosing Engine that decomposes post-evaluation analysis into planning, aggregate analysis, instance-level case inspection, multilingual and cultural reflection, and grounded report synthesis. MADE is paired with an expert-led 54-query and 15-language diagnostic set, evaluated on top of a large-scale multilingual evaluation substrate (33 model families, 11 benchmarks, 26 languages, 34 cultures, 8.66M evaluation records). Experiments show that MADE outperforms the strongest shared baseline by 47% in diagnosis report quality and is preferred by human multilingual experts in 87.9% of pairwise comparisons. Applied with multilingual experts, MADE further surfaces four actionable findings on deployment, iteration, and cross-cultural pitfalls, turning benchmark score tables into model-selection and remediation guidance.
The GaoYao Benchmark: A Comprehensive Framework for Evaluating Multilingual and Multicultural Abilities of Large Language Models
Apr 22, 2026Evaluating the multilingual and multicultural capabilities of Large Language Models (LLMs) is essential for their global utility. However, current benchmarks face three critical limitations: (1) fragmented evaluation dimensions that often neglect deep cultural nuances; (2) insufficient language coverage in subjective tasks relying on low-quality machine translation; and (3) shallow analysis that lacks diagnostic depth beyond simple rankings. To address these, we introduce GaoYao, a comprehensive benchmark with 182.3k samples, 26 languages and 51 nations/areas. First, GaoYao proposes a unified framework categorizing evaluation tasks into three cultural layers (General Multilingual, Cross-cultural, Monocultural) and nine cognitive sub-layers. Second, we achieve native-quality expansion by leveraging experts to rigorously localize subjective benchmarks into 19 languages and synthesizing cross-cultural test sets for 34 cultures, surpassing prior coverage by up to 111%. Third, we conduct an in-depth diagnostic analysis on 20+ flagship and compact LLMs. Our findings reveal significant geographical performance disparities and distinct gaps between tasks, offering a reliable map for future work. We release the benchmark (https://github.com/lunyiliu/GaoYao).
TRN-R1-Zero: Text-rich Network Reasoning via LLMs with Reinforcement Learning Only
Apr 21, 2026Zero-shot reasoning on text-rich networks (TRNs) remains a challenging frontier, as models must integrate textual semantics with relational structure without task-specific supervision. While graph neural networks rely on fixed label spaces and supervised objectives, recent large language model (LLM)-based approaches often overlook graph context or depend on distillation from larger models, limiting generalisation. We propose TRN-R1-Zero, a post-training framework for TRN reasoning trained solely via reinforcement learning. TRN-R1-Zero directly optimises base LLMs using a Neighbour-aware Group Relative Policy Optimisation objective that dynamically adjusts rewards based on a novel margin gain metric for the informativeness of neighbouring signals, effectively guiding the model toward relational reasoning. Unlike prior methods, TRN-R1-Zero requires no supervised fine-tuning or chain-of-thought data generated from large reasoning models. Extensive experiments across citation, hyperlink, social and co-purchase TRN benchmarks demonstrate the superiority and robustness of TRN-R1-Zero. Moreover, relying strictly on node-level training, TRN-R1-Zero achieves zero-shot inference on edge- and graph-level tasks, extending beyond cross-domain transfer. The codebase is publicly available at https://github.com/superallen13/TRN-R1-Zero.
LLM Safety From Within: Detecting Harmful Content with Internal Representations
Apr 20, 2026Guard models are widely used to detect harmful content in user prompts and LLM responses. However, state-of-the-art guard models rely solely on terminal-layer representations and overlook the rich safety-relevant features distributed across internal layers. We present SIREN, a lightweight guard model that harnesses these internal features. By identifying safety neurons via linear probing and combining them through an adaptive layer-weighted strategy, SIREN builds a harmfulness detector from LLM internals without modifying the underlying model. Our comprehensive evaluation shows that SIREN substantially outperforms state-of-the-art open-source guard models across multiple benchmarks while using 250 times fewer trainable parameters. Moreover, SIREN exhibits superior generalization to unseen benchmarks, naturally enables real-time streaming detection, and significantly improves inference efficiency compared to generative guard models. Overall, our results highlight LLM internal states as a promising foundation for practical, high-performance harmfulness detection.
Routing-Free Mixture-of-Experts
Apr 01, 2026Standard Mixture-of-Experts (MoE) models rely on centralized routing mechanisms that introduce rigid inductive biases. We propose Routing-Free MoE which eliminates any hard-coded centralized designs including external routers, Softmax, Top-K and load balancing, instead encapsulating all activation functionalities within individual experts and directly optimized through continuous gradient flow, enabling each expert to determine its activation entirely on its own. We introduce a unified adaptive load-balancing framework to simultaneously optimize both expert-balancing and token-balancing objectives through a configurable interpolation, allowing flexible and customizable resource allocation. Extensive experiments show that Routing-Free MoE can consistently outperform baselines with better scalability and robustness. We analyze its behavior in detail and offer insights that may facilitate future MoE design ad optimization.
Chart Specification: Structural Representations for Incentivizing VLM Reasoning in Chart-to-Code Generation
Feb 11, 2026Vision-Language Models (VLMs) have shown promise in generating plotting code from chart images, yet achieving structural fidelity remains challenging. Existing approaches largely rely on supervised fine-tuning, encouraging surface-level token imitation rather than faithful modeling of underlying chart structure, which often leads to hallucinated or semantically inconsistent outputs. We propose Chart Specification, a structured intermediate representation that shifts training from text imitation to semantically grounded supervision. Chart Specification filters syntactic noise to construct a structurally balanced training set and supports a Spec-Align Reward that provides fine-grained, verifiable feedback on structural correctness, enabling reinforcement learning to enforce consistent plotting logic. Experiments on three public benchmarks show that our method consistently outperforms prior approaches. With only 3K training samples, we achieve strong data efficiency, surpassing leading baselines by up to 61.7% on complex benchmarks, and scaling to 4K samples establishes new state-of-the-art results across all evaluated metrics. Overall, our results demonstrate that precise structural supervision offers an efficient pathway to high-fidelity chart-to-code generation. Code and dataset are available at: https://github.com/Mighten/chart-specification-paper
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
LogPurge: Log Data Purification for Anomaly Detection via Rule-Enhanced Filtering
Nov 18, 2025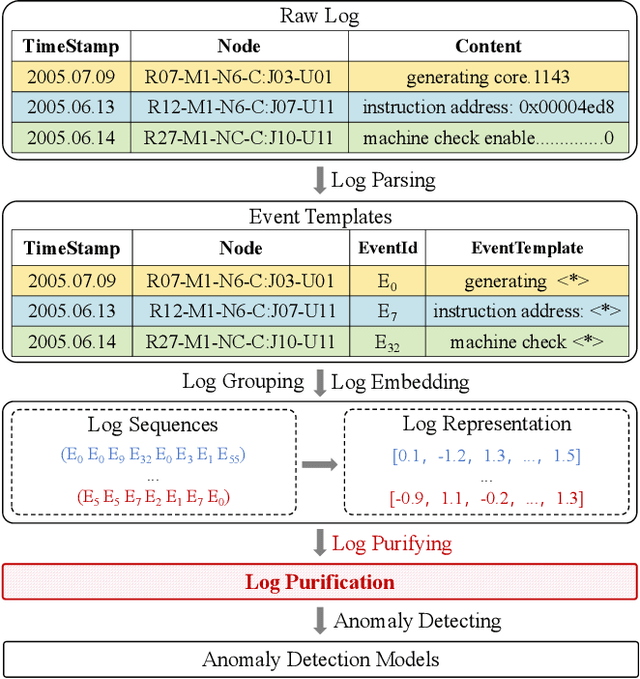
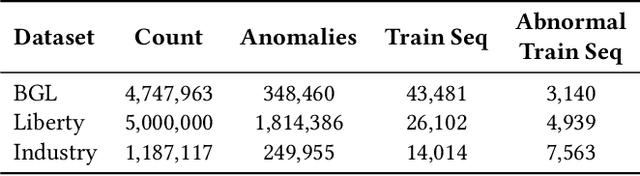
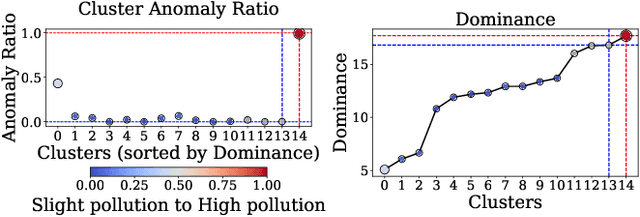
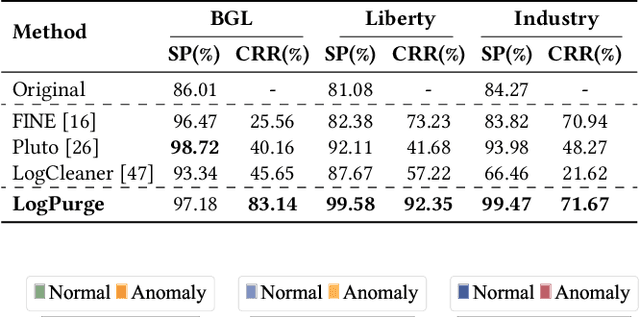
Log anomaly detection, which is critical for identifying system failures and preempting security breaches, detects irregular patterns within large volumes of log data, and impacts domains such as service reliability, performance optimization, and database log analysis. Modern log anomaly detection methods rely on training deep learning models on clean, anomaly-free log sequences. However, obtaining such clean log data requires costly and tedious human labeling, and existing automatic cleaning methods fail to fully integrate the specific characteristics and actual semantics of logs in their purification process. In this paper, we propose a cost-aware, rule-enhanced purification framework, LogPurge, that automatically selects a sufficient subset of normal log sequences from contamination log sequences to train a anomaly detection model. Our approach involves a two-stage filtering algorithm: In the first stage, we use a large language model (LLM) to remove clustered anomalous patterns and enhance system rules to improve LLM's understanding of system logs; in the second stage, we utilize a divide-and-conquer strategy that decomposes the remaining contaminated regions into smaller subproblems, allowing each to be effectively purified through the first stage procedure. Our experiments, conducted on two public datasets and one industrial dataset, show that our method significantly removes an average of 98.74% of anomalies while retaining 82.39% of normal samples. Compared to the latest unsupervised log sample selection algorithms, our method achieves F-1 score improvements of 35.7% and 84.11% on the public datasets, and an impressive 149.72% F-1 improvement on the private dataset, demonstrating the effectiveness of our approach.
A method for improving multilingual quality and diversity of instruction fine-tuning datasets
Sep 19, 2025Multilingual Instruction Fine-Tuning (IFT) is essential for enabling large language models (LLMs) to generalize effectively across diverse linguistic and cultural contexts. However, the scarcity of high-quality multilingual training data and corresponding building method remains a critical bottleneck. While data selection has shown promise in English settings, existing methods often fail to generalize across languages due to reliance on simplistic heuristics or language-specific assumptions. In this work, we introduce Multilingual Data Quality and Diversity (M-DaQ), a novel method for improving LLMs multilinguality, by selecting high-quality and semantically diverse multilingual IFT samples. We further conduct the first systematic investigation of the Superficial Alignment Hypothesis (SAH) in multilingual setting. Empirical results across 18 languages demonstrate that models fine-tuned with M-DaQ method achieve significant performance gains over vanilla baselines over 60% win rate. Human evaluations further validate these gains, highlighting the increment of cultural points in the response. We release the M-DaQ code to support future research.
RationAnomaly: Log Anomaly Detection with Rationality via Chain-of-Thought and Reinforcement Learning
Sep 18, 2025Logs constitute a form of evidence signaling the operational status of software systems. Automated log anomaly detection is crucial for ensuring the reliability of modern software systems. However, existing approaches face significant limitations: traditional deep learning models lack interpretability and generalization, while methods leveraging Large Language Models are often hindered by unreliability and factual inaccuracies. To address these issues, we propose RationAnomaly, a novel framework that enhances log anomaly detection by synergizing Chain-of-Thought (CoT) fine-tuning with reinforcement learning. Our approach first instills expert-like reasoning patterns using CoT-guided supervised fine-tuning, grounded in a high-quality dataset corrected through a rigorous expert-driven process. Subsequently, a reinforcement learning phase with a multi-faceted reward function optimizes for accuracy and logical consistency, effectively mitigating hallucinations. Experimentally, RationAnomaly outperforms state-of-the-art baselines, achieving superior F1-scores on key benchmarks while providing transparent, step-by-step analytical outputs. We have released the corresponding resources, including code and datasets.