 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Graph, Explicit Retrieval: Towards Efficient and Interpretable Long-horizon Memory for Large Language Models
Jan 06, 2026Long-horizon applications increasingly require large language models (LLMs) to answer queries when relevant evidence is sparse and dispersed across very long contexts. Existing memory systems largely follow two paradigms: explicit structured memories offer interpretability but often become brittle under long-context overload, while latent memory mechanisms are efficient and stable yet difficult to inspect. We propose LatentGraphMem, a memory framework that combines implicit graph memory with explicit subgraph retrieval. LatentGraphMem stores a graph-structured memory in latent space for stability and efficiency, and exposes a task-specific subgraph retrieval interface that returns a compact symbolic subgraph under a fixed budget for downstream reasoning and human inspection. During training, an explicit graph view is materialized to interface with a frozen reasoner for question-answering supervision. At inference time, retrieval is performed in latent space and only the retrieved subgraph is externalized. Experiments on long-horizon benchmarks across multiple model scales show that LatentGraphMem consistently outperforms representative explicit-graph and latent-memory baselines, while enabling parameter-efficient adaptation and flexible scaling to larger reasoners without introducing large symbolic artifacts.
Unraveling MMDiT Blocks: Training-free Analysis and Enhancement of Text-conditioned Diffusion
Jan 05, 2026Recent breakthroughs of transformer-based diffusion models, particularly with Multimodal Diffusion Transformers (MMDiT) driven models like FLUX and Qwen Image, have facilitated thrilling experiences in text-to-image generation and editing. To understand the internal mechanism of MMDiT-based models, existing methods tried to analyze the effect of specific components like positional encoding and attention layers. Yet, a comprehensive understanding of how different blocks and their interactions with textual conditions contribute to the synthesis process remains elusive. In this paper, we first develop a systematic pipeline to comprehensively investigate each block's functionality by removing, disabling and enhancing textual hidden-states at corresponding blocks. Our analysis reveals that 1) semantic information appears in earlier blocks and finer details are rendered in later blocks, 2) removing specific blocks is usually less disruptive than disabling text conditions, and 3) enhancing textual conditions in selective blocks improves semantic attributes. Building on these observations, we further propose novel training-free strategies for improved text alignment, precise editing, and acceleration. Extensive experiments demonstrated that our method outperforms various baselines and remains flexible across text-to-image generation, image editing, and inference acceleration. Our method improves T2I-Combench++ from 56.92% to 63.00% and GenEval from 66.42% to 71.63% on SD3.5, without sacrificing synthesis quality. These results advance understanding of MMDiT models and provide valuable insights to unlock new possibilities for further improvements.
Beyond Gemini-3-Pro: Revisiting LLM Routing and Aggregation at Scale
Jan 04, 2026Large Language Models (LLMs) have rapidly advanced, with Gemini-3-Pro setting a new performance milestone. In this work, we explore collective intelligence as an alternative to monolithic scaling, and demonstrate that open-source LLMs' collaboration can surpass Gemini-3-Pro. We first revisit LLM routing and aggregation at scale and identify three key bottlenecks: (1) current train-free routers are limited by a query-based paradigm focusing solely on textual similarity; (2) recent aggregation methods remain largely static, failing to select appropriate aggregators for different tasks;(3) the complementarity of routing and aggregation remains underutilized. To address these problems, we introduce JiSi, a novel framework designed to release the full potential of LLMs' collaboration through three innovations: (1) Query-Response Mixed Routing capturing both semantic information and problem difficulty; (2) Support-Set-based Aggregator Selection jointly evaluating the aggregation and domain capacity of aggregators; (3) Adaptive Routing-Aggregation Switch dynamically leveraging the advantages of routing and aggregation. Comprehensive experiments on nine benchmarks demonstrate that JiSi can surpass Gemini-3-Pro with only 47% costs by orchestrating ten open-source LLMs, while outperforming mainstream baselines. It suggests that collective intelligence represents a novel path towards Artificial General Intelligence (AGI).
A unified multimodal understanding and generation model for cross-disciplinary scientific research
Jan 04, 2026Scientific discovery increasingly relies on integrating heterogeneous, high-dimensional data across disciplines nowadays. While AI models have achieved notable success across various scientific domains, they typically remain domain-specific or lack the capability of simultaneously understanding and generating multimodal scientific data, particularly for high-dimensional data. Yet, many pressing global challenges and scientific problems are inherently cross-disciplinary and require coordinated progress across multiple fields. Here, we present FuXi-Uni, a native unified multimodal model for scientific understanding and high-fidelity generation across scientific domains within a single architecture. Specifically, FuXi-Uni aligns cross-disciplinary scientific tokens within natural language tokens and employs science decoder to reconstruct scientific tokens, thereby supporting both natural language conversation and scientific numerical prediction. Empirically, we validate FuXi-Uni in Earth science and Biomedicine. In Earth system modeling, the model supports global weather forecasting, tropical cyclone (TC) forecast editing, and spatial downscaling driven by only language instructions. FuXi-Uni generates 10-day global forecasts at 0.25° resolution that outperform the SOTA physical forecasting system. It shows superior performance for both TC track and intensity prediction relative to the SOTA physical model, and generates high-resolution regional weather fields that surpass standard interpolation baselines. Regarding biomedicine, FuXi-Uni outperforms leading multimodal large language models on multiple biomedical visual question answering benchmarks. By unifying heterogeneous scientific modalities within a native shared latent space while maintaining strong domain-specific performance, FuXi-Uni provides a step forward more general-purpose, multimodal scientific models.
IntraStyler: Exemplar-based Style Synthesis for Cross-modality Domain Adaptation
Jan 01, 2026Image-level domain alignment is the de facto approach for unsupervised domain adaptation, where unpaired image translation is used to minimize the domain gap. Prior studies mainly focus on the domain shift between the source and target domains, whereas the intra-domain variability remains under-explored. To address the latter, an effective strategy is to diversify the styles of the synthetic target domain data during image translation. However, previous methods typically require intra-domain variations to be pre-specified for style synthesis, which may be impractical. In this paper, we propose an exemplar-based style synthesis method named IntraStyler, which can capture diverse intra-domain styles without any prior knowledge. Specifically, IntraStyler uses an exemplar image to guide the style synthesis such that the output style matches the exemplar style. To extract the style-only features, we introduce a style encoder to learn styles discriminatively based on contrastive learning. We evaluate the proposed method on the largest public dataset for cross-modality domain adaptation, CrossMoDA 2023. Our experiments show the efficacy of our method in controllable style synthesis and the benefits of diverse synthetic data for downstream segmentation. Code is available at https://github.com/han-liu/IntraStyler.
AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Dec 29, 2025Memory serves as the pivotal nexus bridging past and future, providing both humans and AI systems with invaluable concepts and experience to navigate complex tasks. Recent research on autonomous agents has increasingly focused on designing efficient memory workflows by drawing on cognitive neuroscience. However, constrained by interdisciplinary barriers, existing works struggle to assimilate the essence of human memory mechanisms. To bridge this gap, we systematically synthesizes interdisciplinary knowledge of memory, connecting insights from cognitive neuroscience with LLM-driven agents. Specifically, we first elucidate the definition and function of memory along a progressive trajectory from cognitive neuroscience through LLMs to agents. We then provide a comparative analysis of memory taxonomy, storage mechanisms, and the complete management lifecycle from both biological and artificial perspectives. Subsequently, we review the mainstream benchmarks for evaluating agent memory. Additionally, we explore memory security from dual perspectives of attack and defense. Finally, we envision future research directions, with a focus on multimodal memory systems and skill acquisition.
Multi-AI Agent Framework Reveals the "Oxide Gatekeeper" in Aluminum Nanoparticle Oxidation
Dec 27, 2025Aluminum nanoparticles (ANPs) are among the most energy-dense solid fuels, yet the atomic mechanisms governing their transition from passivated particles to explosive reactants remain elusive. This stems from a fundamental computational bottleneck: ab initio methods offer quantum accuracy but are restricted to small spatiotemporal scales (< 500 atoms, picoseconds), while empirical force fields lack the reactive fidelity required for complex combustion environments. Herein, we bridge this gap by employing a "human-in-the-loop" closed-loop framework where self-auditing AI Agents validate the evolution of a machine learning potential (MLP). By acting as scientific sentinels that visualize hidden model artifacts for human decision-making, this collaborative cycle ensures quantum mechanical accuracy while exhibiting near-linear scalability to million-atom systems and accessing nanosecond timescales (energy RMSE: 1.2 meV/atom, force RMSE: 0.126 eV/Angstrom). Strikingly, our simulations reveal a temperature-regulated dual-mode oxidation mechanism: at moderate temperatures, the oxide shell acts as a dynamic "gatekeeper," regulating oxidation through a "breathing mode" of transient nanochannels; above a critical threshold, a "rupture mode" unleashes catastrophic shell failure and explosive combustion. Importantly, we resolve a decades-old controversy by demonstrating that aluminum cation outward diffusion, rather than oxygen transport, dominates mass transfer across all temperature regimes, with diffusion coefficients consistently exceeding those of oxygen by 2-3 orders of magnitude. These discoveries establish a unified atomic-scale framework for energetic nanomaterial design, enabling the precision engineering of ignition sensitivity and energy release rates through intelligent computational design.
Envision: Embodied Visual Planning via Goal-Imagery Video Diffusion
Dec 27, 2025Embodied visual planning aims to enable manipulation tasks by imagining how a scene evolves toward a desired goal and using the imagined trajectories to guide actions. Video diffusion models, through their image-to-video generation capability, provide a promising foundation for such visual imagination. However, existing approaches are largely forward predictive, generating trajectories conditioned on the initial observation without explicit goal modeling, thus often leading to spatial drift and goal misalignment. To address these challenges, we propose Envision, a diffusion-based framework that performs visual planning for embodied agents. By explicitly constraining the generation with a goal image, our method enforces physical plausibility and goal consistency throughout the generated trajectory. Specifically, Envision operates in two stages. First, a Goal Imagery Model identifies task-relevant regions, performs region-aware cross attention between the scene and the instruction, and synthesizes a coherent goal image that captures the desired outcome. Then, an Env-Goal Video Model, built upon a first-and-last-frame-conditioned video diffusion model (FL2V), interpolates between the initial observation and the goal image, producing smooth and physically plausible video trajectories that connect the start and goal states. Experiments on object manipulation and image editing benchmarks demonstrate that Envision achieves superior goal alignment, spatial consistency, and object preservation compared to baselines. The resulting visual plans can directly support downstream robotic planning and control, providing reliable guidance for embodied agents.
Enabling Ultra-Fast Cardiovascular Imaging Across Heterogeneous Clinical Environments with a Generalist Foundation Model and Multimodal Database
Dec 25, 2025Multimodal cardiovascular magnetic resonance (CMR) imaging provides comprehensive and non-invasive insights into cardiovascular disease (CVD) diagnosis and underlying mechanisms. Despite decades of advancements, its widespread clinical adoption remains constrained by prolonged scan times and heterogeneity across medical environments. This underscores the urgent need for a generalist reconstruction foundation model for ultra-fast CMR imaging, one capable of adapting across diverse imaging scenarios and serving as the essential substrate for all downstream analyses. To enable this goal, we curate MMCMR-427K, the largest and most comprehensive multimodal CMR k-space database to date, comprising 427,465 multi-coil k-space data paired with structured metadata across 13 international centers, 12 CMR modalities, 15 scanners, and 17 CVD categories in populations across three continents. Building on this unprecedented resource, we introduce CardioMM, a generalist reconstruction foundation model capable of dynamically adapting to heterogeneous fast CMR imaging scenarios. CardioMM unifies semantic contextual understanding with physics-informed data consistency to deliver robust reconstructions across varied scanners, protocols, and patient presentations. Comprehensive evaluations demonstrate that CardioMM achieves state-of-the-art performance in the internal centers and exhibits strong zero-shot generalization to unseen external settings. Even at imaging acceleration up to 24x, CardioMM reliably preserves key cardiac phenotypes, quantitative myocardial biomarkers, and diagnostic image quality, enabling a substantial increase in CMR examination throughput without compromising clinical integrity. Together, our open-access MMCMR-427K database and CardioMM framework establish a scalable pathway toward high-throughput, high-quality, and clinically accessible cardiovascular imaging.
Rethinking Popularity Bias in Collaborative Filtering via Analytical Vector Decomposition
Dec 24, 2025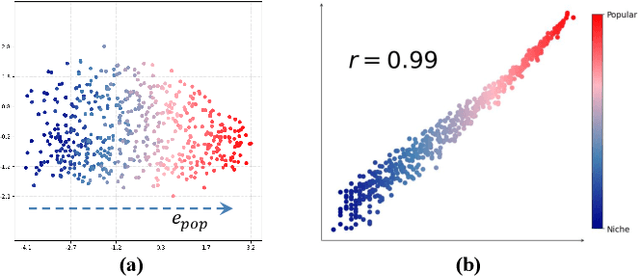
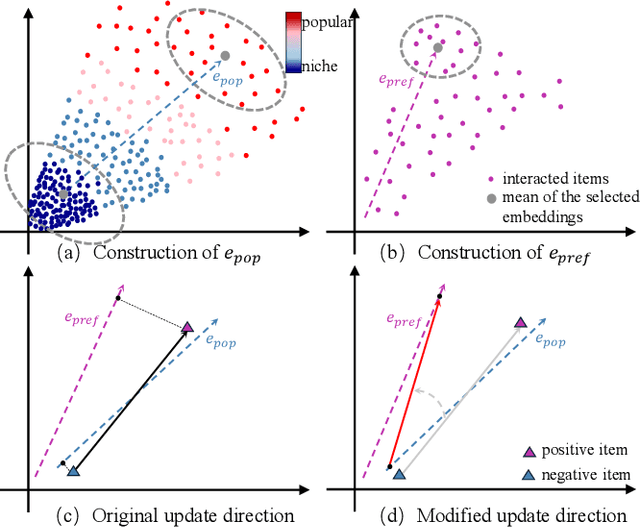
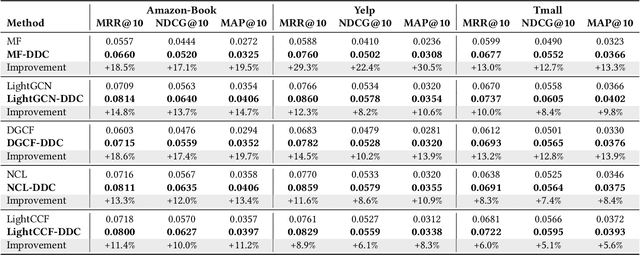
Popularity bias fundamentally undermines the personalization capabilities of collaborative filtering (CF) models, causing them to disproportionately recommend popular items while neglecting users' genuine preferences for niche content. While existing approaches treat this as an external confounding factor, we reveal that popularity bias is an intrinsic geometric artifact of Bayesian Pairwise Ranking (BPR) optimization in CF models. Through rigorous mathematical analysis, we prove that BPR systematically organizes item embeddings along a dominant "popularity direction" where embedding magnitudes directly correlate with interaction frequency. This geometric distortion forces user embeddings to simultaneously handle two conflicting tasks-expressing genuine preference and calibrating against global popularity-trapping them in suboptimal configurations that favor popular items regardless of individual tastes. We propose Directional Decomposition and Correction (DDC), a universally applicable framework that surgically corrects this embedding geometry through asymmetric directional updates. DDC guides positive interactions along personalized preference directions while steering negative interactions away from the global popularity direction, disentangling preference from popularity at the geometric source. Extensive experiments across multiple BPR-based architectures demonstrate that DDC significantly outperforms state-of-the-art debiasing methods, reducing training loss to less than 5% of heavily-tuned baselines while achieving superior recommendation quality and fairness. Code is available in https://github.com/LingFeng-Liu-AI/DDC.