 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception Without Engagement: Dissecting the Causal Discovery Deficit in LMMs
May 10, 2026Although Large Multimodal Models (LMMs) have achieved strong performance on general video understanding, their susceptibility to textual prior shortcuts during causal discovery has been recognized as a critical deficit. The underlying mechanisms of this phenomenon remain incompletely understood, as existing benchmarks only measure response accuracy without revealing the sources and extent of the deficit. We introduce ProCauEval, a perturbation-based evaluation protocol that shifts from outcome assessment to mechanism diagnosis, probing causal discovery through five controlled configurations that systematically manipulate visual and textual modalities to decompose their respective contributions to model behavior and dissect the failure modes. Evaluating 17 mainstream LMMs, we find that models faithfully perceive video content yet systematically underexploit it during causal reasoning. We further observe that stronger post-training amplifies rather than mitigates textual prior reliance, and that higher baseline performance correlates with greater fragility under perturbation. To address these, we propose Anti-Distillation Policy Optimization (ADPO), a reinforcement learning framework built on negative teacher alignment, which augments GRPO by explicitly pushing the policy away from a prior-only counterfactual teacher induced by visual corruption. Specifically, ADPO maximizes the divergence between the policy distributions conditioned on the original and visually corrupted inputs, thereby forcing the model to ground its reasoning in visual evidence rather than textual shortcuts. Extensive experiments show that ADPO improves visual engagement without sacrificing fundamental comprehension, thus offering a preliminary step toward reliable causal discovery.
Schema-Aware Planning and Hybrid Knowledge Toolset for Reliable Knowledge Graph Triple Verification
Apr 05, 2026Knowledge Graphs (KGs) serve as a critical foundation for AI systems, yet their automated construction inevitably introduces noise, compromising data trustworthiness. Existing triple verification methods, based on graph embeddings or language models, often suffer from single-source bias by relying on either internal structural constraints or external semantic evidence, and usually follow a static inference paradigm. As a result, they struggle with complex or long-tail facts and provide limited interpretability. To address these limitations, we propose SHARP (Schema-Hybrid Agent for Reliable Prediction), a training-free autonomous agent that reformulates triple verification as a dynamic process of strategic planning, active investigation, and evidential reasoning. Specifically, SHARP combines a Memory-Augmented Mechanism with Schema-Aware Strategic Planning to improve reasoning stability, and employs an enhanced ReAct loop with a Hybrid Knowledge Toolset to dynamically integrate internal KG structure and external textual evidence for cross-verification. Experiments on FB15K-237 and Wikidata5M-Ind show that SHARP significantly outperforms existing state-of-the-art baselines, achieving accuracy gains of 4.2% and 12.9%, respectively. Moreover, SHARP provides transparent, fact-based evidence chains for each judgment, demonstrating strong interpretability and robustness for complex verification tasks.
LoopRPT: Reinforcement Pre-Training for Looped Language Models
Mar 20, 2026Looped language models (LoopLMs) perform iterative latent computation to refine internal representations, offering a promising alternative to explicit chain-of-thought (CoT) reasoning. However, existing reinforcement learning (RL) paradigms primarily target output tokens, creating a structural mismatch with looped architectures whose reasoning unfolds implicitly. In this work, we propose LoopRPT, a reinforcement pre-training framework tailored for LoopLMs. By reframing next-token prediction as a next-token reasoning task, LoopRPT assigns reinforcement signals directly to latent steps using an EMA teacher reference and noisy latent rollouts. This formulation enables RL to directly shape intermediate representations, compressing effective reasoning into fewer iterations. We instantiate LoopRPT on the Ouro architecture across multiple model scales. Results demonstrate that LoopRPT consistently improves per-step representation quality, achieving Pareto dominance in accuracy-computation trade-offs. Notably, significant gains on hard tokens indicate that LoopRPT enhances early-stage reasoning rather than merely encouraging premature exits. Our findings highlight reinforcement pre-training as a principled paradigm for learning efficient latent reasoning in LoopLMs.
Analyzing Reasoning Consistency in Large Multimodal Models under Cross-Modal Conflicts
Jan 07, 2026Large Multimodal Models (LMMs) have demonstrated impressive capabilities in video reasoning via Chain-of-Thought (CoT). However, the robustness of their reasoning chains remains questionable. In this paper, we identify a critical failure mode termed textual inertia, where once a textual hallucination occurs in the thinking process, models tend to blindly adhere to the erroneous text while neglecting conflicting visual evidence. To systematically investigate this, we propose the LogicGraph Perturbation Protocol that structurally injects perturbations into the reasoning chains of diverse LMMs spanning both native reasoning architectures and prompt-driven paradigms to evaluate their self-reflection capabilities. The results reveal that models successfully self-correct in less than 10% of cases and predominantly succumb to blind textual error propagation. To mitigate this, we introduce Active Visual-Context Refinement, a training-free inference paradigm which orchestrates an active visual re-grounding mechanism to enforce fine-grained verification coupled with an adaptive context refinement strategy to summarize and denoise the reasoning history. Experiments demonstrate that our approach significantly stifles hallucination propagation and enhances reasoning robustness.
AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents
Dec 29, 2025Memory serves as the pivotal nexus bridging past and future, providing both humans and AI systems with invaluable concepts and experience to navigate complex tasks. Recent research on autonomous agents has increasingly focused on designing efficient memory workflows by drawing on cognitive neuroscience. However, constrained by interdisciplinary barriers, existing works struggle to assimilate the essence of human memory mechanisms. To bridge this gap, we systematically synthesizes interdisciplinary knowledge of memory, connecting insights from cognitive neuroscience with LLM-driven agents. Specifically, we first elucidate the definition and function of memory along a progressive trajectory from cognitive neuroscience through LLMs to agents. We then provide a comparative analysis of memory taxonomy, storage mechanisms, and the complete management lifecycle from both biological and artificial perspectives. Subsequently, we review the mainstream benchmarks for evaluating agent memory. Additionally, we explore memory security from dual perspectives of attack and defense. Finally, we envision future research directions, with a focus on multimodal memory systems and skill acquisition.
Investigating and Enhancing the Robustness of Large Multimodal Models Against Temporal Inconsistency
May 20, 2025Large Multimodal Models (LMMs) have recently demonstrated impressive performance on general video comprehension benchmarks. Nevertheless, for broader applications, the robustness of their temporal analysis capability needs to be thoroughly investigated yet predominantly ignored. Motivated by this, we propose a novel temporal robustness benchmark (TemRobBench), which introduces temporal inconsistency perturbations separately at the visual and textual modalities to assess the robustness of models. We evaluate 16 mainstream LMMs and find that they exhibit over-reliance on prior knowledge and textual context in adversarial environments, while ignoring the actual temporal dynamics in the video. To mitigate this issue, we design panoramic direct preference optimization (PanoDPO), which encourages LMMs to incorporate both visual and linguistic feature preferences simultaneously. Experimental results show that PanoDPO can effectively enhance the model's robustness and reliability in temporal analysis.
From Specific-MLLM to Omni-MLLM: A Survey about the MLLMs alligned with Multi-Modality
Dec 16, 2024



From the Specific-MLLM, which excels in single-modal tasks, to the Omni-MLLM, which extends the range of general modalities, this evolution aims to achieve understanding and generation of multimodal information. Omni-MLLM treats the features of different modalities as different "foreign languages," enabling cross-modal interaction and understanding within a unified space. To promote the advancement of related research, we have compiled 47 relevant papers to provide the community with a comprehensive introduction to Omni-MLLM. We first explain the four core components of Omni-MLLM for unified modeling and interaction of multiple modalities. Next, we introduce the effective integration achieved through "alignment pretraining" and "instruction fine-tuning," and discuss open-source datasets and testing of interaction capabilities. Finally, we summarize the main challenges facing current Omni-MLLM and outline future directions.
GUIDE: A Guideline-Guided Dataset for Instructional Video Comprehension
Jun 26, 2024



There are substantial instructional videos on the Internet, which provide us tutorials for completing various tasks. Existing instructional video datasets only focus on specific steps at the video level, lacking experiential guidelines at the task level, which can lead to beginners struggling to learn new tasks due to the lack of relevant experience. Moreover, the specific steps without guidelines are trivial and unsystematic, making it difficult to provide a clear tutorial. To address these problems, we present the GUIDE (Guideline-Guided) dataset, which contains 3.5K videos of 560 instructional tasks in 8 domains related to our daily life. Specifically, we annotate each instructional task with a guideline, representing a common pattern shared by all task-related videos. On this basis, we annotate systematic specific steps, including their associated guideline steps, specific step descriptions and timestamps. Our proposed benchmark consists of three sub-tasks to evaluate comprehension ability of models: (1) Step Captioning: models have to generate captions for specific steps from videos. (2) Guideline Summarization: models have to mine the common pattern in task-related videos and summarize a guideline from them. (3) Guideline-Guided Captioning: models have to generate captions for specific steps under the guide of guideline. We evaluate plenty of foundation models with GUIDE and perform in-depth analysis. Given the diversity and practicality of GUIDE, we believe that it can be used as a better benchmark for instructional video comprehension.
A Hierarchical Deep Convolutional Neural Network and Gated Recurrent Unit Framework for Structural Damage Detection
May 29, 2020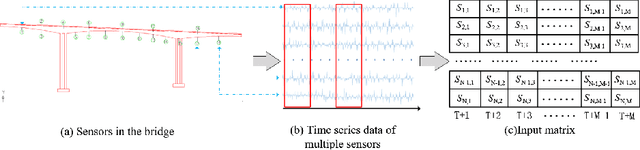

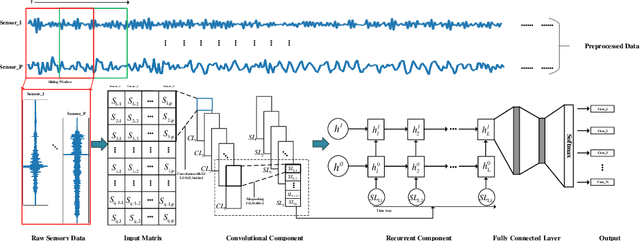

Structural damage detection has become an interdisciplinary area of interest for various engineering fields, while the available damage detection methods are being in the process of adapting machine learning concepts. Most machine learning based methods heavily depend on extracted ``hand-crafted" features that are manually selected in advance by domain experts and then, fixed. Recently, deep learning has demonstrated remarkable performance on traditional challenging tasks, such as image classification, object detection, etc., due to the powerful feature learning capabilities. This breakthrough has inspired researchers to explore deep learning techniques for structural damage detection problems. However, existing methods have considered either spatial relation (e.g., using convolutional neural network (CNN)) or temporal relation (e.g., using long short term memory network (LSTM)) only. In this work, we propose a novel Hierarchical CNN and Gated recurrent unit (GRU) framework to model both spatial and temporal relations, termed as HCG, for structural damage detection. Specifically, CNN is utilized to model the spatial relations and the short-term temporal dependencies among sensors, while the output features of CNN are fed into the GRU to learn the long-term temporal dependencies jointly. Extensive experiments on IASC-ASCE structural health monitoring benchmark and scale model of three-span continuous rigid frame bridge structure datasets have shown that our proposed HCG outperforms other existing methods for structural damage detection significantly.