 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Popularity Bias in Collaborative Filtering via Analytical Vector Decomposition
Dec 24, 2025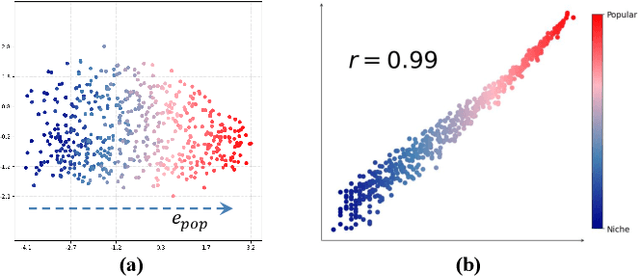
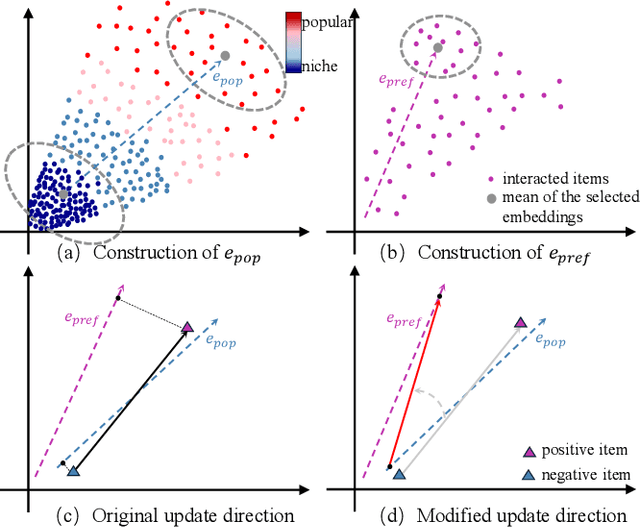
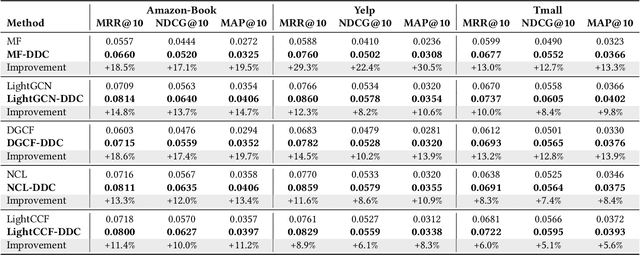
Popularity bias fundamentally undermines the personalization capabilities of collaborative filtering (CF) models, causing them to disproportionately recommend popular items while neglecting users' genuine preferences for niche content. While existing approaches treat this as an external confounding factor, we reveal that popularity bias is an intrinsic geometric artifact of Bayesian Pairwise Ranking (BPR) optimization in CF models. Through rigorous mathematical analysis, we prove that BPR systematically organizes item embeddings along a dominant "popularity direction" where embedding magnitudes directly correlate with interaction frequency. This geometric distortion forces user embeddings to simultaneously handle two conflicting tasks-expressing genuine preference and calibrating against global popularity-trapping them in suboptimal configurations that favor popular items regardless of individual tastes. We propose Directional Decomposition and Correction (DDC), a universally applicable framework that surgically corrects this embedding geometry through asymmetric directional updates. DDC guides positive interactions along personalized preference directions while steering negative interactions away from the global popularity direction, disentangling preference from popularity at the geometric source. Extensive experiments across multiple BPR-based architectures demonstrate that DDC significantly outperforms state-of-the-art debiasing methods, reducing training loss to less than 5% of heavily-tuned baselines while achieving superior recommendation quality and fairness. Code is available in https://github.com/LingFeng-Liu-AI/DDC.
SmallThinker: A Family of Efficient Large Language Models Natively Trained for Local Deployment
Jul 28, 2025While frontier large language models (LLMs) continue to push capability boundaries, their deployment remains confined to GPU-powered cloud infrastructure. We challenge this paradigm with SmallThinker, a family of LLMs natively designed - not adapted - for the unique constraints of local devices: weak computational power, limited memory, and slow storage. Unlike traditional approaches that mainly compress existing models built for clouds, we architect SmallThinker from the ground up to thrive within these limitations. Our innovation lies in a deployment-aware architecture that transforms constraints into design principles. First, We introduce a two-level sparse structure combining fine-grained Mixture-of-Experts (MoE) with sparse feed-forward networks, drastically reducing computational demands without sacrificing model capacity. Second, to conquer the I/O bottleneck of slow storage, we design a pre-attention router that enables our co-designed inference engine to prefetch expert parameters from storage while computing attention, effectively hiding storage latency that would otherwise cripple on-device inference. Third, for memory efficiency, we utilize NoPE-RoPE hybrid sparse attention mechanism to slash KV cache requirements. We release SmallThinker-4B-A0.6B and SmallThinker-21B-A3B, which achieve state-of-the-art performance scores and even outperform larger LLMs. Remarkably, our co-designed system mostly eliminates the need for expensive GPU hardware: with Q4_0 quantization, both models exceed 20 tokens/s on ordinary consumer CPUs, while consuming only 1GB and 8GB of memory respectively. SmallThinker is publicly available at hf.co/PowerInfer/SmallThinker-4BA0.6B-Instruct and hf.co/PowerInfer/SmallThinker-21BA3B-Instruct.
Can LLMs Alleviate Catastrophic Forgetting in Graph Continual Learning? A Systematic Study
May 24, 2025Nowadays, real-world data, including graph-structure data, often arrives in a streaming manner, which means that learning systems need to continuously acquire new knowledge without forgetting previously learned information. Although substantial existing works attempt to address catastrophic forgetting in graph machine learning, they are all based on training from scratch with streaming data. With the rise of pretrained models, an increasing number of studies have leveraged their strong generalization ability for continual learning. Therefore, in this work, we attempt to answer whether large language models (LLMs) can mitigate catastrophic forgetting in Graph Continual Learning (GCL). We first point out that current experimental setups for GCL have significant flaws, as the evaluation stage may lead to task ID leakage. Then, we evaluate the performance of LLMs in more realistic scenarios and find that even minor modifications can lead to outstanding results. Finally, based on extensive experiments, we propose a simple-yet-effective method, Simple Graph Continual Learning (SimGCL), that surpasses the previous state-of-the-art GNN-based baseline by around 20% under the rehearsal-free constraint. To facilitate reproducibility, we have developed an easy-to-use benchmark LLM4GCL for training and evaluating existing GCL methods. The code is available at: https://github.com/ZhixunLEE/LLM4GCL.
PipeWeaver: Addressing Data Dynamicity in Large Multimodal Model Training with Dynamic Interleaved Pipeline
Apr 19, 2025



Large multimodal models (LMMs) have demonstrated excellent capabilities in both understanding and generation tasks with various modalities. While these models can accept flexible combinations of input data, their training efficiency suffers from two major issues: pipeline stage imbalance caused by heterogeneous model architectures, and training data dynamicity stemming from the diversity of multimodal data. In this paper, we present PipeWeaver, a dynamic pipeline scheduling framework designed for LMM training. The core of PipeWeaver is dynamic interleaved pipeline, which searches for pipeline schedules dynamically tailored to current training batches. PipeWeaver addresses issues of LMM training with two techniques: adaptive modality-aware partitioning and efficient pipeline schedule search within a hierarchical schedule space. Meanwhile, PipeWeaver utilizes SEMU (Step Emulator), a training simulator for multimodal models, for accurate performance estimations, accelerated by spatial-temporal subgraph reuse to improve search efficiency. Experiments show that PipeWeaver can enhance LMM training efficiency by up to 97.3% compared to state-of-the-art systems, and demonstrate excellent adaptivity to LMM training's data dynamicity.
PowerInfer-2: Fast Large Language Model Inference on a Smartphone
Jun 12, 2024



This paper introduces PowerInfer-2, a framework designed for high-speed inference of Large Language Models (LLMs) on smartphones, particularly effective for models whose sizes exceed the device's memory capacity. The key insight of PowerInfer-2 is to utilize the heterogeneous computation, memory, and I/O resources in smartphones by decomposing traditional matrix computations into fine-grained neuron cluster computations. Specifically, PowerInfer-2 features a polymorphic neuron engine that adapts computational strategies for various stages of LLM inference. Additionally, it introduces segmented neuron caching and fine-grained neuron-cluster-level pipelining, which effectively minimize and conceal the overhead caused by I/O operations. The implementation and evaluation of PowerInfer-2 demonstrate its capability to support a wide array of LLM models on two smartphones, achieving up to a 29.2x speed increase compared with state-of-the-art frameworks. Notably, PowerInfer-2 is the first system to serve the TurboSparse-Mixtral-47B model with a generation rate of 11.68 tokens per second on a smartphone. For models that fit entirely within the memory, PowerInfer-2 can achieve approximately a 40% reduction in memory usage while maintaining inference speeds comparable to llama.cpp and MLC-LLM. For more details, including a demonstration video, please visit the project site at www.powerinfer.ai/v2.
Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters
Jun 11, 2024



Exploiting activation sparsity is a promising approach to significantly accelerating the inference process of large language models (LLMs) without compromising performance. However, activation sparsity is determined by activation functions, and commonly used ones like SwiGLU and GeGLU exhibit limited sparsity. Simply replacing these functions with ReLU fails to achieve sufficient sparsity. Moreover, inadequate training data can further increase the risk of performance degradation. To address these challenges, we propose a novel dReLU function, which is designed to improve LLM activation sparsity, along with a high-quality training data mixture ratio to facilitate effective sparsification. Additionally, we leverage sparse activation patterns within the Feed-Forward Network (FFN) experts of Mixture-of-Experts (MoE) models to further boost efficiency. By applying our neuron sparsification method to the Mistral and Mixtral models, only 2.5 billion and 4.3 billion parameters are activated per inference iteration, respectively, while achieving even more powerful model performance. Evaluation results demonstrate that this sparsity achieves a 2-5x decoding speedup. Remarkably, on mobile phones, our TurboSparse-Mixtral-47B achieves an inference speed of 11 tokens per second. Our models are available at \url{https://huggingface.co/PowerInfer}
ReLU$^2$ Wins: Discovering Efficient Activation Functions for Sparse LLMs
Feb 06, 2024Sparse computation offers a compelling solution for the inference of Large Language Models (LLMs) in low-resource scenarios by dynamically skipping the computation of inactive neurons. While traditional approaches focus on ReLU-based LLMs, leveraging zeros in activation values, we broaden the scope of sparse LLMs beyond zero activation values. We introduce a general method that defines neuron activation through neuron output magnitudes and a tailored magnitude threshold, demonstrating that non-ReLU LLMs also exhibit sparse activation. To find the most efficient activation function for sparse computation, we propose a systematic framework to examine the sparsity of LLMs from three aspects: the trade-off between sparsity and performance, the predictivity of sparsity, and the hardware affinity. We conduct thorough experiments on LLMs utilizing different activation functions, including ReLU, SwiGLU, ReGLU, and ReLU$^2$. The results indicate that models employing ReLU$^2$ excel across all three evaluation aspects, highlighting its potential as an efficient activation function for sparse LLMs. We will release the code to facilitate future research.
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU
Dec 16, 2023



This paper introduces PowerInfer, a high-speed Large Language Model (LLM) inference engine on a personal computer (PC) equipped with a single consumer-grade GPU. The key underlying the design of PowerInfer is exploiting the high locality inherent in LLM inference, characterized by a power-law distribution in neuron activation. This distribution indicates that a small subset of neurons, termed hot neurons, are consistently activated across inputs, while the majority, cold neurons, vary based on specific inputs. PowerInfer exploits such an insight to design a GPU-CPU hybrid inference engine: hot-activated neurons are preloaded onto the GPU for fast access, while cold-activated neurons are computed on the CPU, thus significantly reducing GPU memory demands and CPU-GPU data transfers. PowerInfer further integrates adaptive predictors and neuron-aware sparse operators, optimizing the efficiency of neuron activation and computational sparsity. Evaluation shows that PowerInfer attains an average token generation rate of 13.20 tokens/s, with a peak of 29.08 tokens/s, across various LLMs (including OPT-175B) on a single NVIDIA RTX 4090 GPU, only 18% lower than that achieved by a top-tier server-grade A100 GPU. This significantly outperforms llama.cpp by up to 11.69x while retaining model accuracy.