 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Prune to act, trace to learn with selective turn memory in agentic RL
Jun 30, 2026Long-horizon language agents must repeatedly interact with tools, accumulate evidence, and make decisions under bounded context windows. Existing context-management methods make such rollouts feasible by truncating distant history, folding past turns into summaries, or selecting compact memory states. However, these breakthroughs introduce two coupled limitations. First, as the number of turns grows, historical observations are progressively removed or collapsed into compressed states, making it harder for the policy to reuse fine-grained evidence. Second, once the original turns are no longer source-addressable, outcome-based RL loses an explicit path for aligning policy updates with the evidence that supported a successful final answer. To this end, we propose ECHO, a selective turn-memory framework that jointly addresses history collapse and traceable learning through source-indexed reconstruction. Specifically, ECHO compresses each completed environment turn into a compact memory record, reconstructs bounded policy contexts by selecting from these records, and reuses the selected source indices to route positive outcome credit to the evidence and selection actions that support successful answers. On BrowseComp-Plus, ECHO reaches 43.4% held-out accuracy, outperforming GRPO (28.9%) and the rolling-summary baseline SUPO (36.1%), while using fewer turns and lower trajectory volume than SUPO (Figure 1). Additionally, the trained policy improves zero-shot generalization across multi-objective QA, code generation, and deep information-seeking benchmarks on both dense and MoE backbones.
Rethinking Popularity Bias in Collaborative Filtering via Analytical Vector Decomposition
Dec 24, 2025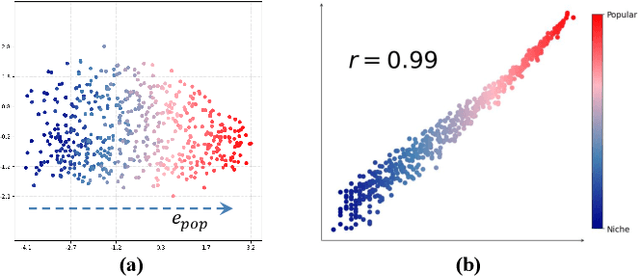
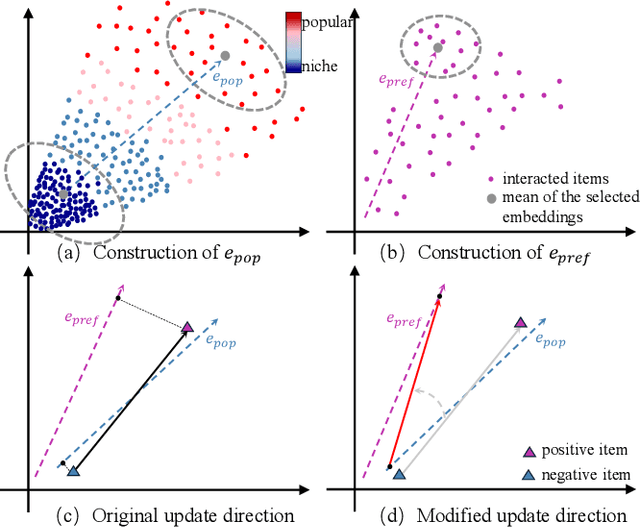
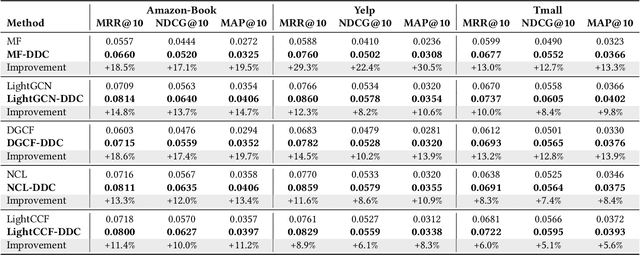
Popularity bias fundamentally undermines the personalization capabilities of collaborative filtering (CF) models, causing them to disproportionately recommend popular items while neglecting users' genuine preferences for niche content. While existing approaches treat this as an external confounding factor, we reveal that popularity bias is an intrinsic geometric artifact of Bayesian Pairwise Ranking (BPR) optimization in CF models. Through rigorous mathematical analysis, we prove that BPR systematically organizes item embeddings along a dominant "popularity direction" where embedding magnitudes directly correlate with interaction frequency. This geometric distortion forces user embeddings to simultaneously handle two conflicting tasks-expressing genuine preference and calibrating against global popularity-trapping them in suboptimal configurations that favor popular items regardless of individual tastes. We propose Directional Decomposition and Correction (DDC), a universally applicable framework that surgically corrects this embedding geometry through asymmetric directional updates. DDC guides positive interactions along personalized preference directions while steering negative interactions away from the global popularity direction, disentangling preference from popularity at the geometric source. Extensive experiments across multiple BPR-based architectures demonstrate that DDC significantly outperforms state-of-the-art debiasing methods, reducing training loss to less than 5% of heavily-tuned baselines while achieving superior recommendation quality and fairness. Code is available in https://github.com/LingFeng-Liu-AI/DDC.
LUM-ViT: Learnable Under-sampling Mask Vision Transformer for Bandwidth Limited Optical Signal Acquisition
Mar 03, 2024



Bandwidth constraints during signal acquisition frequently impede real-time detection applications. Hyperspectral data is a notable example, whose vast volume compromises real-time hyperspectral detection. To tackle this hurdle, we introduce a novel approach leveraging pre-acquisition modulation to reduce the acquisition volume. This modulation process is governed by a deep learning model, utilizing prior information. Central to our approach is LUM-ViT, a Vision Transformer variant. Uniquely, LUM-ViT incorporates a learnable under-sampling mask tailored for pre-acquisition modulation. To further optimize for optical calculations, we propose a kernel-level weight binarization technique and a three-stage fine-tuning strategy. Our evaluations reveal that, by sampling a mere 10% of the original image pixels, LUM-ViT maintains the accuracy loss within 1.8% on the ImageNet classification task. The method sustains near-original accuracy when implemented on real-world optical hardware, demonstrating its practicality. Code will be available at https://github.com/MaxLLF/LUM-ViT.