 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChi-Square Wavelet Graph Neural Networks for Heterogeneous Graph Anomaly Detection
May 25, 2025



Graph Anomaly Detection (GAD) in heterogeneous networks presents unique challenges due to node and edge heterogeneity. Existing Graph Neural Network (GNN) methods primarily focus on homogeneous GAD and thus fail to address three key issues: (C1) Capturing abnormal signal and rich semantics across diverse meta-paths; (C2) Retaining high-frequency content in HIN dimension alignment; and (C3) Learning effectively from difficult anomaly samples with class imbalance. To overcome these, we propose ChiGAD, a spectral GNN framework based on a novel Chi-Square filter, inspired by the wavelet effectiveness in diverse domains. Specifically, ChiGAD consists of: (1) Multi-Graph Chi-Square Filter, which captures anomalous information via applying dedicated Chi-Square filters to each meta-path graph; (2) Interactive Meta-Graph Convolution, which aligns features while preserving high-frequency information and incorporates heterogeneous messages by a unified Chi-Square Filter; and (3) Contribution-Informed Cross-Entropy Loss, which prioritizes difficult anomalies to address class imbalance. Extensive experiments on public and industrial datasets show that ChiGAD outperforms state-of-the-art models on multiple metrics. Additionally, its homogeneous variant, ChiGNN, excels on seven GAD datasets, validating the effectiveness of Chi-Square filters. Our code is available at https://github.com/HsipingLi/ChiGAD.
All Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning
Apr 02, 2025The exponential growth of AI-generated images (AIGIs) underscores the urgent need for robust and generalizable detection methods. In this paper, we establish two key principles for AIGI detection through systematic analysis: \textbf{(1) All Patches Matter:} Unlike conventional image classification where discriminative features concentrate on object-centric regions, each patch in AIGIs inherently contains synthetic artifacts due to the uniform generation process, suggesting that every patch serves as an important artifact source for detection. \textbf{(2) More Patches Better}: Leveraging distributed artifacts across more patches improves detection robustness by capturing complementary forensic evidence and reducing over-reliance on specific patches, thereby enhancing robustness and generalization. However, our counterfactual analysis reveals an undesirable phenomenon: naively trained detectors often exhibit a \textbf{Few-Patch Bias}, discriminating between real and synthetic images based on minority patches. We identify \textbf{Lazy Learner} as the root cause: detectors preferentially learn conspicuous artifacts in limited patches while neglecting broader artifact distributions. To address this bias, we propose the \textbf{P}anoptic \textbf{P}atch \textbf{L}earning (PPL) framework, involving: (1) Random Patch Replacement that randomly substitutes synthetic patches with real counterparts to compel models to identify artifacts in underutilized regions, encouraging the broader use of more patches; (2) Patch-wise Contrastive Learning that enforces consistent discriminative capability across all patches, ensuring uniform utilization of all patches. Extensive experiments across two different settings on several benchmarks verify the effectiveness of our approach.
Unified and Dynamic Graph for Temporal Character Grouping in Long Videos
Aug 29, 2023



Video temporal character grouping locates appearing moments of major characters within a video according to their identities. To this end, recent works have evolved from unsupervised clustering to graph-based supervised clustering. However, graph methods are built upon the premise of fixed affinity graphs, bringing many inexact connections. Besides, they extract multi-modal features with kinds of models, which are unfriendly to deployment. In this paper, we present a unified and dynamic graph (UniDG) framework for temporal character grouping. This is accomplished firstly by a unified representation network that learns representations of multiple modalities within the same space and still preserves the modality's uniqueness simultaneously. Secondly, we present a dynamic graph clustering where the neighbors of different quantities are dynamically constructed for each node via a cyclic matching strategy, leading to a more reliable affinity graph. Thirdly, a progressive association method is introduced to exploit spatial and temporal contexts among different modalities, allowing multi-modal clustering results to be well fused. As current datasets only provide pre-extracted features, we evaluate our UniDG method on a collected dataset named MTCG, which contains each character's appearing clips of face and body and speaking voice tracks. We also evaluate our key components on existing clustering and retrieval datasets to verify the generalization ability. Experimental results manifest that our method can achieve promising results and outperform several state-of-the-art approaches.
D3G: Exploring Gaussian Prior for Temporal Sentence Grounding with Glance Annotation
Aug 08, 2023



Temporal sentence grounding (TSG) aims to locate a specific moment from an untrimmed video with a given natural language query. Recently, weakly supervised methods still have a large performance gap compared to fully supervised ones, while the latter requires laborious timestamp annotations. In this study, we aim to reduce the annotation cost yet keep competitive performance for TSG task compared to fully supervised ones. To achieve this goal, we investigate a recently proposed glance-supervised temporal sentence grounding task, which requires only single frame annotation (referred to as glance annotation) for each query. Under this setup, we propose a Dynamic Gaussian prior based Grounding framework with Glance annotation (D3G), which consists of a Semantic Alignment Group Contrastive Learning module (SA-GCL) and a Dynamic Gaussian prior Adjustment module (DGA). Specifically, SA-GCL samples reliable positive moments from a 2D temporal map via jointly leveraging Gaussian prior and semantic consistency, which contributes to aligning the positive sentence-moment pairs in the joint embedding space. Moreover, to alleviate the annotation bias resulting from glance annotation and model complex queries consisting of multiple events, we propose the DGA module, which adjusts the distribution dynamically to approximate the ground truth of target moments. Extensive experiments on three challenging benchmarks verify the effectiveness of the proposed D3G. It outperforms the state-of-the-art weakly supervised methods by a large margin and narrows the performance gap compared to fully supervised methods. Code is available at https://github.com/solicucu/D3G.
Collaborative Noisy Label Cleaner: Learning Scene-aware Trailers for Multi-modal Highlight Detection in Movies
Mar 26, 2023



Movie highlights stand out of the screenplay for efficient browsing and play a crucial role on social media platforms. Based on existing efforts, this work has two observations: (1) For different annotators, labeling highlight has uncertainty, which leads to inaccurate and time-consuming annotations. (2) Besides previous supervised or unsupervised settings, some existing video corpora can be useful, e.g., trailers, but they are often noisy and incomplete to cover the full highlights. In this work, we study a more practical and promising setting, i.e., reformulating highlight detection as "learning with noisy labels". This setting does not require time-consuming manual annotations and can fully utilize existing abundant video corpora. First, based on movie trailers, we leverage scene segmentation to obtain complete shots, which are regarded as noisy labels. Then, we propose a Collaborative noisy Label Cleaner (CLC) framework to learn from noisy highlight moments. CLC consists of two modules: augmented cross-propagation (ACP) and multi-modality cleaning (MMC). The former aims to exploit the closely related audio-visual signals and fuse them to learn unified multi-modal representations. The latter aims to achieve cleaner highlight labels by observing the changes in losses among different modalities. To verify the effectiveness of CLC, we further collect a large-scale highlight dataset named MovieLights. Comprehensive experiments on MovieLights and YouTube Highlights datasets demonstrate the effectiveness of our approach. Code has been made available at: https://github.com/TencentYoutuResearch/HighlightDetection-CLC
See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
Aug 26, 2022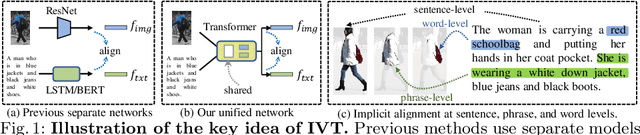
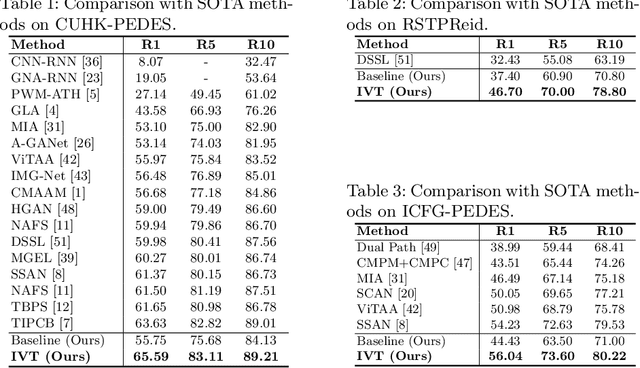
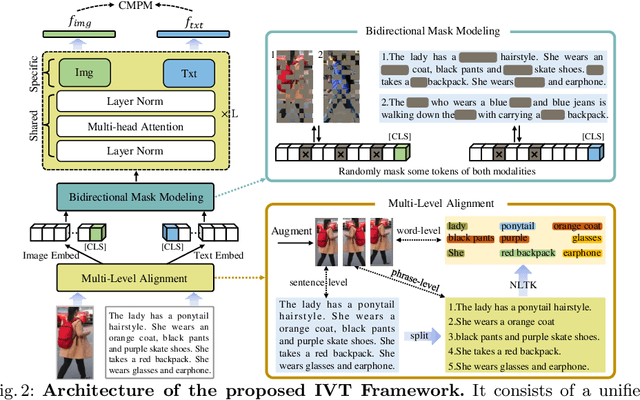

Text-based person retrieval aims to find the query person based on a textual description. The key is to learn a common latent space mapping between visual-textual modalities. To achieve this goal, existing works employ segmentation to obtain explicitly cross-modal alignments or utilize attention to explore salient alignments. These methods have two shortcomings: 1) Labeling cross-modal alignments are time-consuming. 2) Attention methods can explore salient cross-modal alignments but may ignore some subtle and valuable pairs. To relieve these issues, we introduce an Implicit Visual-Textual (IVT) framework for text-based person retrieval. Different from previous models, IVT utilizes a single network to learn representation for both modalities, which contributes to the visual-textual interaction. To explore the fine-grained alignment, we further propose two implicit semantic alignment paradigms: multi-level alignment (MLA) and bidirectional mask modeling (BMM). The MLA module explores finer matching at sentence, phrase, and word levels, while the BMM module aims to mine \textbf{more} semantic alignments between visual and textual modalities. Extensive experiments are carried out to evaluate the proposed IVT on public datasets, i.e., CUHK-PEDES, RSTPReID, and ICFG-PEDES. Even without explicit body part alignment, our approach still achieves state-of-the-art performance. Code is available at: https://github.com/TencentYoutuResearch/PersonRetrieval-IVT.
VLMAE: Vision-Language Masked Autoencoder
Aug 19, 2022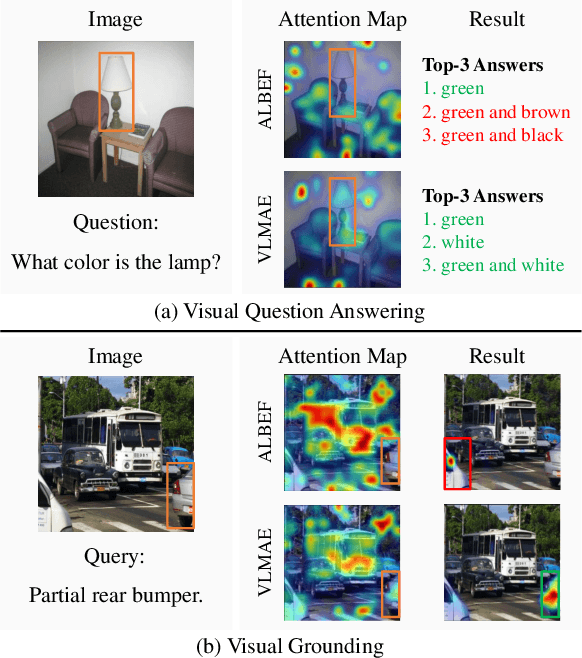
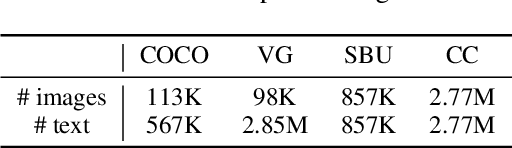
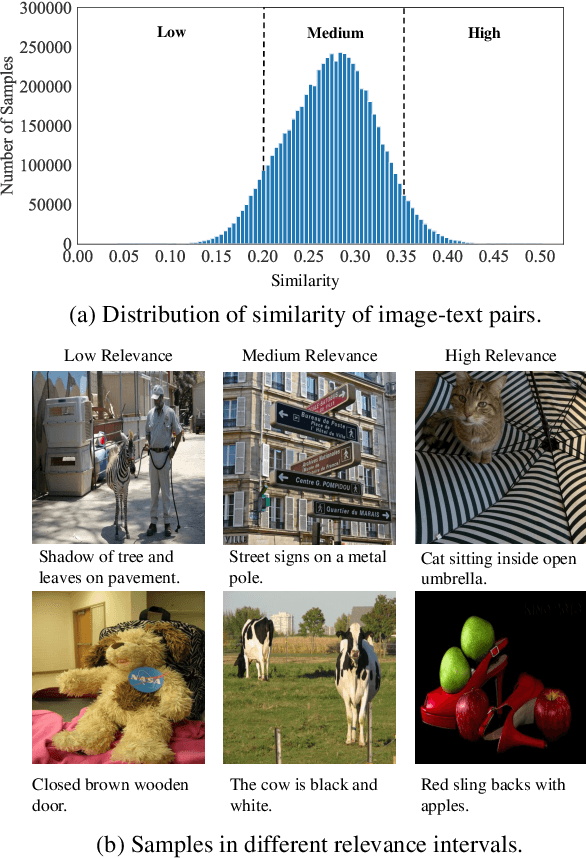
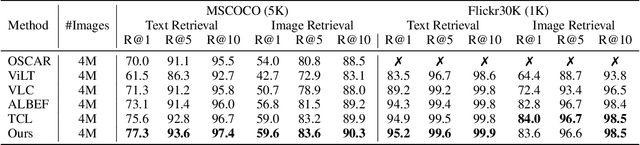
Image and language modeling is of crucial importance for vision-language pre-training (VLP), which aims to learn multi-modal representations from large-scale paired image-text data. However, we observe that most existing VLP methods focus on modeling the interactions between image and text features while neglecting the information disparity between image and text, thus suffering from focal bias. To address this problem, we propose a vision-language masked autoencoder framework (VLMAE). VLMAE employs visual generative learning, facilitating the model to acquire fine-grained and unbiased features. Unlike the previous works, VLMAE pays attention to almost all critical patches in an image, providing more comprehensive understanding. Extensive experiments demonstrate that VLMAE achieves better performance in various vision-language downstream tasks, including visual question answering, image-text retrieval and visual grounding, even with up to 20% pre-training speedup.
Exploiting Feature Diversity for Make-up Temporal Video Grounding
Aug 12, 2022
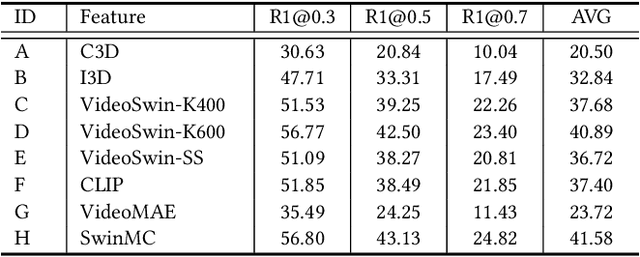
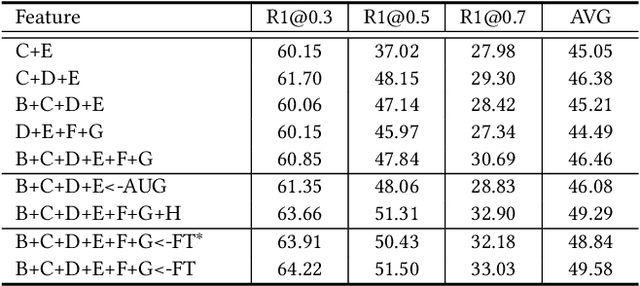

This technical report presents the 3rd winning solution for MTVG, a new task introduced in the 4-th Person in Context (PIC) Challenge at ACM MM 2022. MTVG aims at localizing the temporal boundary of the step in an untrimmed video based on a textual description. The biggest challenge of this task is the fi ne-grained video-text semantics of make-up steps. However, current methods mainly extract video features using action-based pre-trained models. As actions are more coarse-grained than make-up steps, action-based features are not sufficient to provide fi ne-grained cues. To address this issue,we propose to achieve fi ne-grained representation via exploiting feature diversities. Specifically, we proposed a series of methods from feature extraction, network optimization, to model ensemble. As a result, we achieved 3rd place in the MTVG competition.
Head and Body: Unified Detector and Graph Network for Person Search in Media
Nov 27, 2021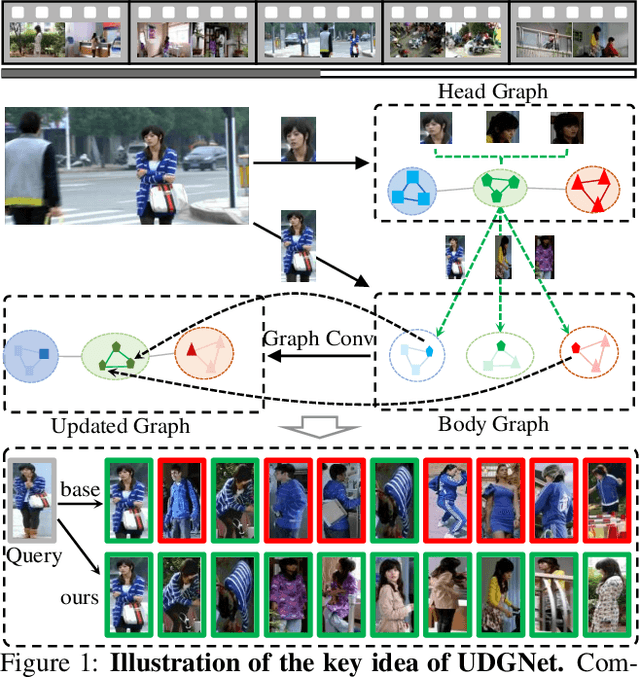
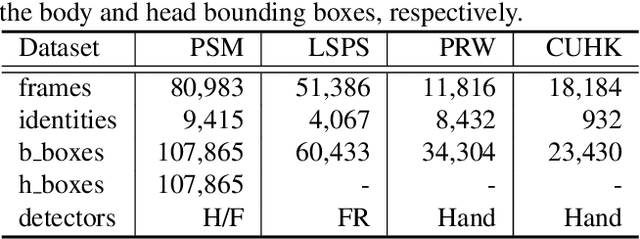
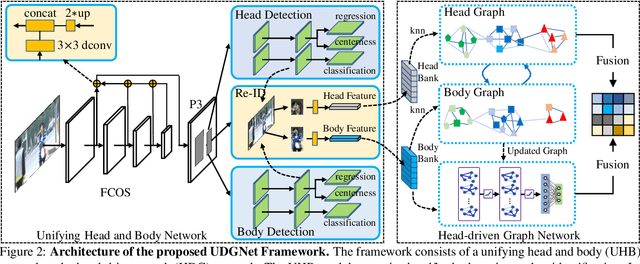
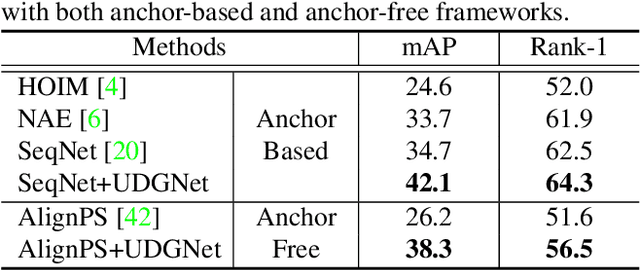
Person search in media has seen increasing potential in Internet applications, such as video clipping and character collection. This task is common but overlooked by previous person search works which focus on surveillance scenes. The media scenarios have some different challenges from surveillance scenes. For example, a person may change his clothes frequently. To alleviate this issue, this paper proposes a Unified Detector and Graph Network (UDGNet) for person search in media. UDGNet is the first person search framework to detect and re-identify the human body and head simultaneously. Specifically, it first builds two branches based on a unified network to detect the human body and head, then the detected body and head are used for re-identification. This dual-task approach can significantly enhance discriminative learning. To tackle the cloth-changing issue, UDGNet builds two graphs to explore reliable links among cloth-changing samples and utilizes a graph network to learn better embeddings. This design effectively enhances the robustness of person search to cloth-changing challenges. Besides, we demonstrate that UDGNet can be implemented with both anchor-based and anchor-free person search frameworks and further achieve performance improvement. This paper also contributes a large-scale dataset for Person Search in Media (PSM), which provides both body and head annotations. It is by far the largest dataset for person search in media. Experiments show that UDGNet improves the anchor-free model AlignPS by 12.1% in mAP. Meanwhile, it shows good generalization across surveillance and longterm scenarios. The dataset and code will be available at: https://github.com/shuxjweb/PSM.git.
Exploiting Robust Unsupervised Video Person Re-identification
Nov 18, 2021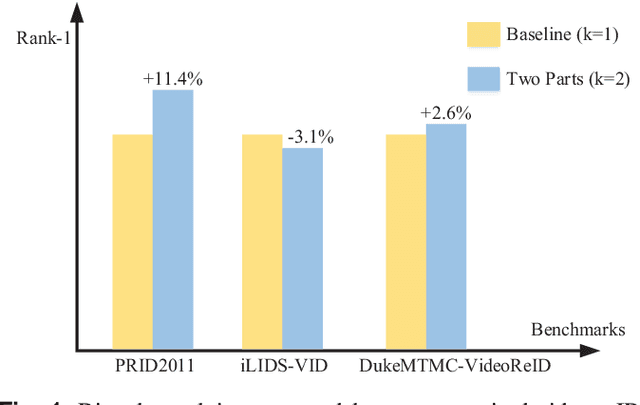
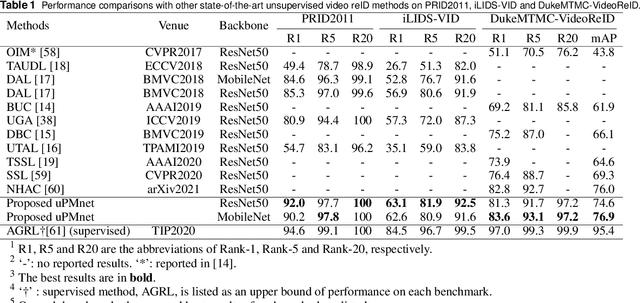


Unsupervised video person re-identification (reID) methods usually depend on global-level features. And many supervised reID methods employed local-level features and achieved significant performance improvements. However, applying local-level features to unsupervised methods may introduce an unstable performance. To improve the performance stability for unsupervised video reID, this paper introduces a general scheme fusing part models and unsupervised learning. In this scheme, the global-level feature is divided into equal local-level feature. A local-aware module is employed to explore the poentials of local-level feature for unsupervised learning. A global-aware module is proposed to overcome the disadvantages of local-level features. Features from these two modules are fused to form a robust feature representation for each input image. This feature representation has the advantages of local-level feature without suffering from its disadvantages. Comprehensive experiments are conducted on three benchmarks, including PRID2011, iLIDS-VID, and DukeMTMC-VideoReID, and the results demonstrate that the proposed approach achieves state-of-the-art performance. Extensive ablation studies demonstrate the effectiveness and robustness of proposed scheme, local-aware module and global-aware module.