 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFighting Numerical Hallucinations via Data-centric Compilation for Online Financial QA
May 29, 2026Large Language Models (LLMs) have significantly advanced online data services, particularly in the domain of financial question answering (FinQA). However, such systems remain susceptible to numerical reasoning hallucinations, which critically undermine reliability in high-stakes financial applications. Although retrieval-augmented generation (RAG) has been widely adopted to ground responses in external knowledge, it introduces three persistent challenges: noise sensitivity, calculation fragility, and an auditability crisis. Existing model-centric approaches, which primarily focus on optimizing either the retriever or generator in isolation, still struggle to address these issues in an integrated manner. In this work, we pioneer a data-centric paradigm and propose a novel framework, the Data-centric Reasoning Compiler (DCRC). The framework operates through three cohesive phases: (1) adversarial data construction, which synthesizes training examples with controlled noise to teach robustness; (2) multi-stage training that cultivates a Data-centric Structuring Agent (DSA) capable of explicit evidence auditing and program synthesis; and (3) a compile-and-execute inference process, where the DSA transforms user queries and retrieved documents into verifiable, executable reasoning programs. This data-driven framework ensures faithful numerical reasoning by design. We conduct extensive experiments on established offline benchmarks and further validate our framework through deployment in a real-world online financial QA system.
Looking Farther with Confidence: Uncertainty-Guided Future Learning for Sequential Recommendation
May 27, 2026Sequential recommendation effectively models dynamic user interests but continues to face challenges related to data sparsity. While self-supervised learning has alleviated this issue to some extent, most existing methods focus exclusively on immediate next-item prediction during training, thereby neglecting the rich information embedded in longer-term future interactions. Although a few studies have explored the utilization of future data, existing attempts typically apply future supervision signals with uniform intensity across all samples, which may lead to suboptimal solutions. In this paper, we propose an adaptive future learning framework, UFRec, which encourages the model to look further ahead when it is confident in the current state, while focusing on the immediate task when it is uncertain. Specifically, UFRec incorporates an Uncertainty-Guided Future Supervision module that dynamically modulates the weight of multi-step future supervision based on the model's confidence in the primary next-item prediction task. Furthermore, we complement step-wise future supervision with a Future-Aware Contrastive Learning module that treats the future trajectory as a holistic entity. Notably, both auxiliary modules are utilized exclusively during training and incur no inference overhead. Extensive experiments on four benchmark datasets demonstrate that our method significantly outperforms state-of-the-art approaches by effectively leveraging future data.
Retrieve-then-Adapt: Retrieval-Augmented Test-Time Adaptation for Sequential Recommendation
Apr 07, 2026The sequential recommendation (SR) task aims to predict the next item based on users' historical interaction sequences. Typically trained on historical data, SR models often struggle to adapt to real-time preference shifts during inference due to challenges posed by distributional divergence and parameterized constraints. Existing approaches to address this issue include test-time training, test-time augmentation, and retrieval-augmented fine-tuning. However, these methods either introduce significant computational overhead, rely on random augmentation strategies, or require a carefully designed two-stage training paradigm. In this paper, we argue that the key to effective test-time adaptation lies in achieving both effective augmentation and efficient adaptation. To this end, we propose Retrieve-then-Adapt (ReAd), a novel framework that dynamically adapts a deployed SR model to the test distribution through retrieved user preference signals. Specifically, given a trained SR model, ReAd first retrieves collaboratively similar items for a test user from a constructed collaborative memory database. A lightweight retrieval learning module then integrates these items into an informative augmentation embedding that captures both collaborative signals and prediction-refinement cues. Finally, the initial SR prediction is refined via a fusion mechanism that incorporates this embedding. Extensive experiments across five benchmark datasets demonstrate that ReAd consistently outperforms existing SR methods.
Data-Driven Function Calling Improvements in Large Language Model for Online Financial QA
Apr 07, 2026Large language models (LLMs) have been incorporated into numerous industrial applications. Meanwhile, a vast array of API assets is scattered across various functions in the financial domain. An online financial question-answering system can leverage both LLMs and private APIs to provide timely financial analysis and information. The key is equipping the LLM model with function calling capability tailored to a financial scenario. However, a generic LLM requires customized financial APIs to call and struggles to adapt to the financial domain. Additionally, online user queries are diverse and contain out-of-distribution parameters compared with the required function input parameters, which makes it more difficult for a generic LLM to serve online users. In this paper, we propose a data-driven pipeline to enhance function calling in LLM for our online, deployed financial QA, comprising dataset construction, data augmentation, and model training. Specifically, we construct a dataset based on a previous study and update it periodically, incorporating queries and an augmentation method named AugFC. The addition of user query-related samples will \textit{exploit} our financial toolset in a data-driven manner, and AugFC explores the possible parameter values to enhance the diversity of our updated dataset. Then, we train an LLM with a two-step method, which enables the use of our financial functions. Extensive experiments on existing offline datasets, as well as the deployment of an online scenario, illustrate the superiority of our pipeline. The related pipeline has been adopted in the financial QA of YuanBao\footnote{https://yuanbao.tencent.com/chat/}, one of the largest chat platforms in China.
SLSREC: Self-Supervised Contrastive Learning for Adaptive Fusion of Long- and Short-Term User Interests
Apr 06, 2026User interests typically encompass both long-term preferences and short-term intentions, reflecting the dynamic nature of user behaviors across different timeframes. The uneven temporal distribution of user interactions highlights the evolving patterns of interests, making it challenging to accurately capture shifts in interests using comprehensive historical behaviors. To address this, we propose SLSRec, a novel Session-based model with the fusion of Long- and Short-term Recommendations that effectively captures the temporal dynamics of user interests by segmenting historical behaviors over time. Unlike conventional models that combine long- and short-term user interests into a single representation, compromising recommendation accuracy, SLSRec utilizes a self-supervised learning framework to disentangle these two types of interests. A contrastive learning strategy is introduced to ensure accurate calibration of long- and short-term interest representations. Additionally, an attention-based fusion network is designed to adaptively aggregate interest representations, optimizing their integration to enhance recommendation performance. Extensive experiments on three public benchmark datasets demonstrate that SLSRec consistently outperforms state-of-the-art models while exhibiting superior robustness across various scenarios.We will release all source code upon acceptance.
PreferRec: Learning and Transferring Pareto Preferences for Multi-objective Re-ranking
Mar 23, 2026Multi-objective re-ranking has become a critical component of modern multi-stage recommender systems, as it tasked to balance multiple conflicting objectives such as accuracy, diversity, and fairness. Existing multi-objective re-ranking methods typically optimize aggregate objectives at the item level using static or handcrafted preference weights. This design overlooks that users inherently exhibit Pareto-optimal preferences at the intent level, reflecting personalized trade-offs among objectives rather than fixed weight combinations. Moreover, most approaches treat re-ranking task for each user as an isolated problem, and repeatedly learn the preferences from scratch. Such a paradigm not only incurs high computational cost, but also ignores the fact that users often share similar preference trade-off structures across objectives. Inspired by the existence of homogeneous multi-objective optimization spaces where Pareto-optimal patterns are transferable, we propose PreferRec, a novel framework that explicitly models and transfers Pareto preferences across users. Specifically, PreferRec is built upon three tightly coupled components: Preference-Aware Pareto Learning aims to capture user intrinsic trade-offs among multiple conflicting objectives at the intent level. By learning Pareto preference representations from re-ranking populations, this component explicitly models how users prioritize different objectives under diverse contexts. Knowledge-Guided Transfer facilitates efficient cross-user knowledge transfer by distilling shared optimization patterns across homogeneous optimization spaces. The transferred knowledge is then used to guide solution selection and personalized re-ranking, biasing the optimization process toward high-quality regions of the Pareto front while preserving user-specific preference characteristics.
DeepResearch-9K: A Challenging Benchmark Dataset of Deep-Research Agent
Mar 01, 2026Deep-research agents are capable of executing multi-step web exploration, targeted retrieval, and sophisticated question answering. Despite their powerful capabilities, deep-research agents face two critical bottlenecks: (1) the lack of large-scale, challenging datasets with real-world difficulty, and (2) the absence of accessible, open-source frameworks for data synthesis and agent training. To bridge these gaps, we first construct DeepResearch-9K, a large-scale challenging dataset specifically designed for deep-research scenarios built from open-source multi-hop question-answering (QA) datasets via a low-cost autonomous pipeline. Notably, it consists of (1) 9000 questions spanning three difficulty levels from L1 to L3 (2) high-quality search trajectories with reasoning chains from Tongyi-DeepResearch-30B-A3B, a state-of-the-art deep-research agent, and (3) verifiable answers. Furthermore, we develop an open-source training framework DeepResearch-R1 that supports (1) multi-turn web interactions, (2) different reinforcement learning (RL) approaches, and (3) different reward models such as rule-based outcome reward and LLM-as-judge feedback. Finally, empirical results demonstrate that agents trained on DeepResearch-9K under our DeepResearch-R1 achieve state-of-the-art results on challenging deep-research benchmarks. We release the DeepResearch-9K dataset on https://huggingface.co/datasets/artillerywu/DeepResearch-9K and the code of DeepResearch-R1 on https://github.com/Applied-Machine-Learning-Lab/DeepResearch-R1.
Give Users the Wheel: Towards Promptable Recommendation Paradigm
Feb 21, 2026Conventional sequential recommendation models have achieved remarkable success in mining implicit behavioral patterns. However, these architectures remain structurally blind to explicit user intent: they struggle to adapt when a user's immediate goal (e.g., expressed via a natural language prompt) deviates from their historical habits. While Large Language Models (LLMs) offer the semantic reasoning to interpret such intent, existing integration paradigms force a dilemma: LLM-as-a-recommender paradigm sacrifices the efficiency and collaborative precision of ID-based retrieval, while Reranking methods are inherently bottlenecked by the recall capabilities of the underlying model. In this paper, we propose Decoupled Promptable Sequential Recommendation (DPR), a model-agnostic framework that empowers conventional sequential backbones to natively support Promptable Recommendation, the ability to dynamically steer the retrieval process using natural language without abandoning collaborative signals. DPR modulates the latent user representation directly within the retrieval space. To achieve this, we introduce a Fusion module to align the collaborative and semantic signals, a Mixture-of-Experts (MoE) architecture that disentangles the conflicting gradients from positive and negative steering, and a three-stage training strategy that progressively aligns the semantic space of prompts with the collaborative space. Extensive experiments on real-world datasets demonstrate that DPR significantly outperforms state-of-the-art baselines in prompt-guided tasks while maintaining competitive performance in standard sequential recommendation scenarios.
Automated Information Flow Selection for Multi-scenario Multi-task Recommendation
Dec 15, 2025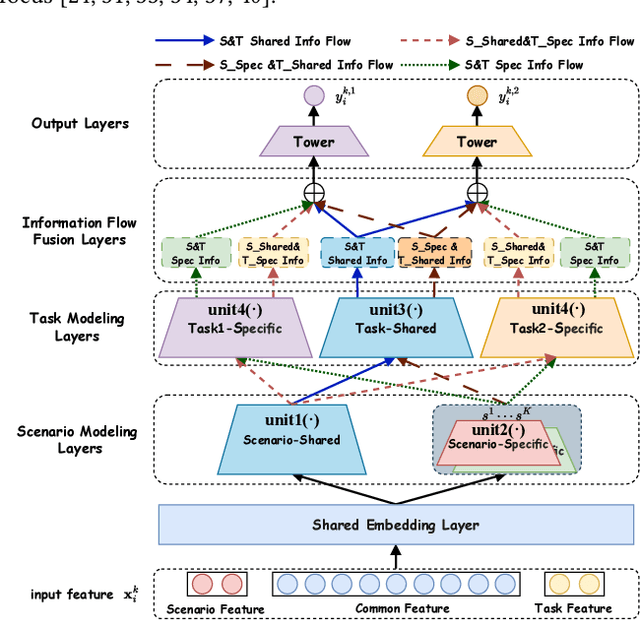
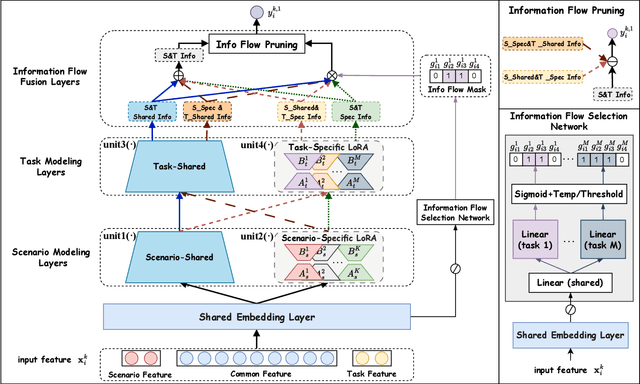
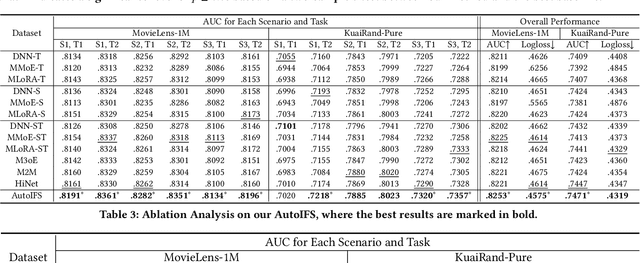
Multi-scenario multi-task recommendation (MSMTR) systems must address recommendation demands across diverse scenarios while simultaneously optimizing multiple objectives, such as click-through rate and conversion rate. Existing MSMTR models typically consist of four information units: scenario-shared, scenario-specific, task-shared, and task-specific networks. These units interact to generate four types of relationship information flows, directed from scenario-shared or scenario-specific networks to task-shared or task-specific networks. However, these models face two main limitations: 1) They often rely on complex architectures, such as mixture-of-experts (MoE) networks, which increase the complexity of information fusion, model size, and training cost. 2) They extract all available information flows without filtering out irrelevant or even harmful content, introducing potential noise. Regarding these challenges, we propose a lightweight Automated Information Flow Selection (AutoIFS) framework for MSMTR. To tackle the first issue, AutoIFS incorporates low-rank adaptation (LoRA) to decouple the four information units, enabling more flexible and efficient information fusion with minimal parameter overhead. To address the second issue, AutoIFS introduces an information flow selection network that automatically filters out invalid scenario-task information flows based on model performance feedback. It employs a simple yet effective pruning function to eliminate useless information flows, thereby enhancing the impact of key relationships and improving model performance. Finally, we evaluate AutoIFS and confirm its effectiveness through extensive experiments on two public benchmark datasets and an online A/B test.
Exploring Test-time Scaling via Prediction Merging on Large-Scale Recommendation
Dec 08, 2025Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.