 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRWKV-UNet: Improving UNet with Long-Range Cooperation for Effective Medical Image Segmentation
Jan 14, 2025



In recent years, there have been significant advancements in deep learning for medical image analysis, especially with convolutional neural networks (CNNs) and transformer models. However, CNNs face limitations in capturing long-range dependencies while transformers suffer high computational complexities. To address this, we propose RWKV-UNet, a novel model that integrates the RWKV (Receptance Weighted Key Value) structure into the U-Net architecture. This integration enhances the model's ability to capture long-range dependencies and improve contextual understanding, which is crucial for accurate medical image segmentation. We build a strong encoder with developed inverted residual RWKV (IR-RWKV) blocks combining CNNs and RWKVs. We also propose a Cross-Channel Mix (CCM) module to improve skip connections with multi-scale feature fusion, achieving global channel information integration. Experiments on benchmark datasets, including Synapse, ACDC, BUSI, CVC-ClinicDB, CVC-ColonDB, Kvasir-SEG, ISIC 2017 and GLAS show that RWKV-UNet achieves state-of-the-art performance on various types of medical image segmentation. Additionally, smaller variants, RWKV-UNet-S and RWKV-UNet-T, balance accuracy and computational efficiency, making them suitable for broader clinical applications.
Towards Lightweight Transformer via Group-wise Transformation for Vision-and-Language Tasks
Apr 16, 2022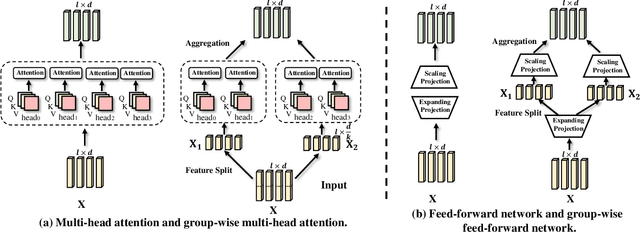


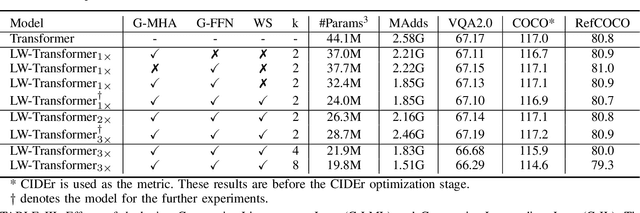
Despite the exciting performance, Transformer is criticized for its excessive parameters and computation cost. However, compressing Transformer remains as an open problem due to its internal complexity of the layer designs, i.e., Multi-Head Attention (MHA) and Feed-Forward Network (FFN). To address this issue, we introduce Group-wise Transformation towards a universal yet lightweight Transformer for vision-and-language tasks, termed as LW-Transformer. LW-Transformer applies Group-wise Transformation to reduce both the parameters and computations of Transformer, while also preserving its two main properties, i.e., the efficient attention modeling on diverse subspaces of MHA, and the expanding-scaling feature transformation of FFN. We apply LW-Transformer to a set of Transformer-based networks, and quantitatively measure them on three vision-and-language tasks and six benchmark datasets. Experimental results show that while saving a large number of parameters and computations, LW-Transformer achieves very competitive performance against the original Transformer networks for vision-and-language tasks. To examine the generalization ability, we also apply our optimization strategy to a recently proposed image Transformer called Swin-Transformer for image classification, where the effectiveness can be also confirmed
Differentiated Relevances Embedding for Group-based Referring Expression Comprehension
Mar 12, 2022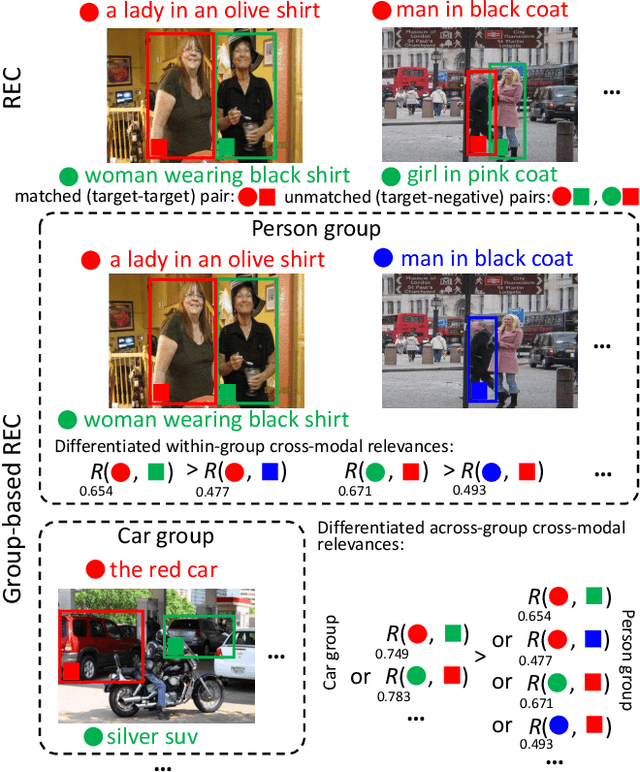
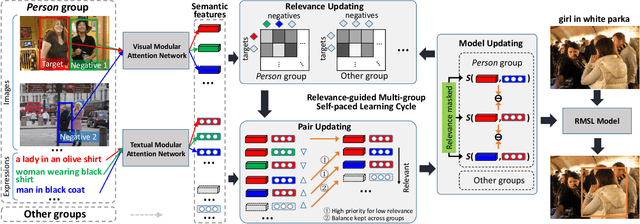

Referring expression comprehension (REC) aims to locate a certain object in an image referred by a natural language expression. For joint understanding of regions and expressions, existing REC works typically target on modeling the cross-modal relevance in each region-expression pair within each single image. In this paper, we explore a new but general REC-related problem, named Group-based REC, where the regions and expressions can come from different subject-related images (images in the same group), e.g., sets of photo albums or video frames. Different from REC, Group-based REC involves differentiated cross-modal relevances within each group and across different groups, which, however, are neglected in the existing one-line paradigm. To this end, we propose a novel relevance-guided multi-group self-paced learning schema (termed RMSL), where the within-group region-expression pairs are adaptively assigned with different priorities according to their cross-modal relevances, and the bias of the group priority is balanced via an across-group relevance constraint simultaneously. In particular, based on the visual and textual semantic features, RMSL conducts an adaptive learning cycle upon triplet ranking, where (1) the target-negative region-expression pairs with low within-group relevances are used preferentially in model training to distinguish the primary semantics of the target objects, and (2) an across-group relevance regularization is integrated into model training to balance the bias of group priority. The relevances, the pairs, and the model parameters are alternatively updated upon a unified self-paced hinge loss.
LSTC: Boosting Atomic Action Detection with Long-Short-Term Context
Oct 19, 2021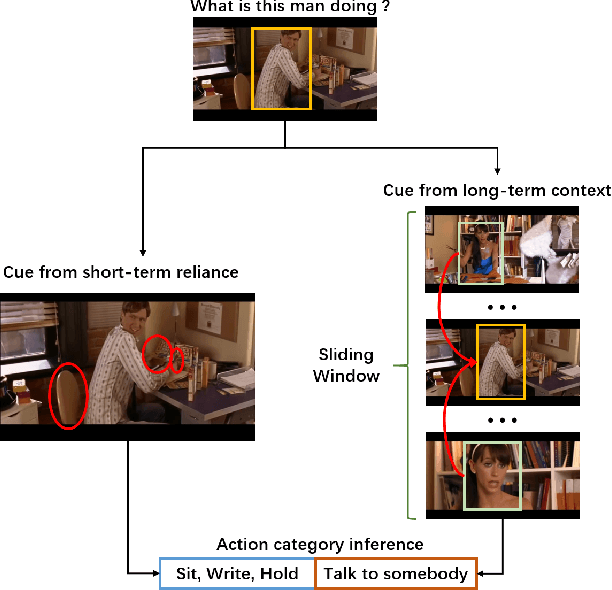
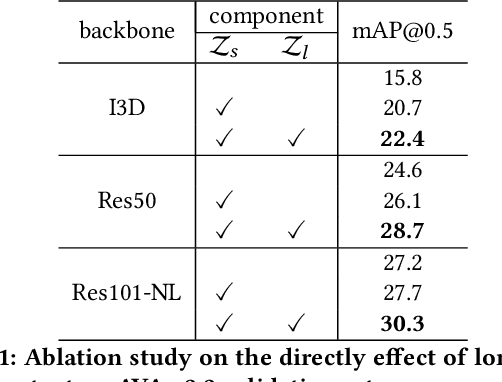
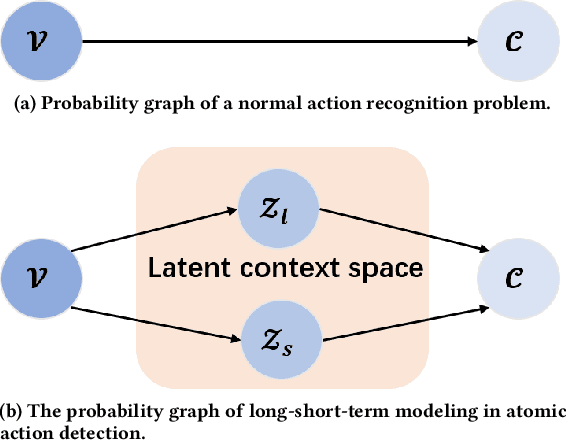
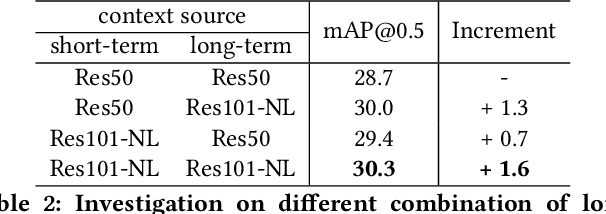
In this paper, we place the atomic action detection problem into a Long-Short Term Context (LSTC) to analyze how the temporal reliance among video signals affect the action detection results. To do this, we decompose the action recognition pipeline into short-term and long-term reliance, in terms of the hypothesis that the two kinds of context are conditionally independent given the objective action instance. Within our design, a local aggregation branch is utilized to gather dense and informative short-term cues, while a high order long-term inference branch is designed to reason the objective action class from high-order interaction between actor and other person or person pairs. Both branches independently predict the context-specific actions and the results are merged in the end. We demonstrate that both temporal grains are beneficial to atomic action recognition. On the mainstream benchmarks of atomic action detection, our design can bring significant performance gain from the existing state-of-the-art pipeline. The code of this project can be found at [this url](https://github.com/TencentYoutuResearch/ActionDetection-LSTC)
Towards Language-guided Visual Recognition via Dynamic Convolutions
Oct 17, 2021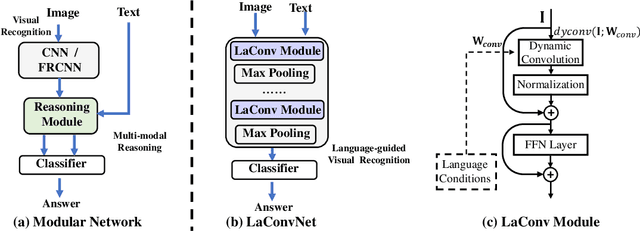
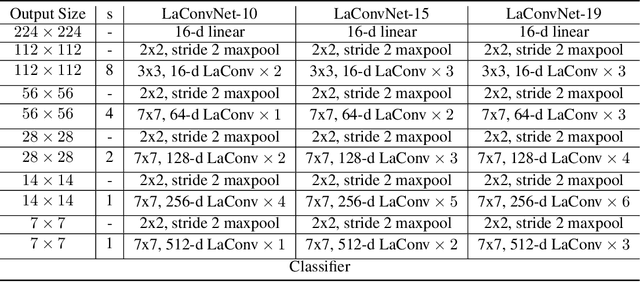
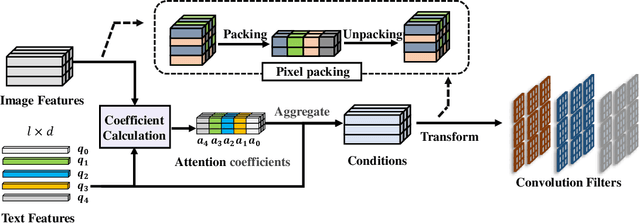
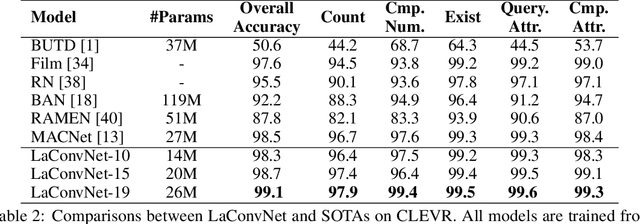
In this paper, we are committed to establishing an unified and end-to-end multi-modal network via exploring the language-guided visual recognition. To approach this target, we first propose a novel multi-modal convolution module called Language-dependent Convolution (LaConv). Its convolution kernels are dynamically generated based on natural language information, which can help extract differentiated visual features for different multi-modal examples. Based on the LaConv module, we further build the first fully language-driven convolution network, termed as LaConvNet, which can unify the visual recognition and multi-modal reasoning in one forward structure. To validate LaConv and LaConvNet, we conduct extensive experiments on four benchmark datasets of two vision-and-language tasks, i.e., visual question answering (VQA) and referring expression comprehension (REC). The experimental results not only shows the performance gains of LaConv compared to the existing multi-modal modules, but also witness the merits of LaConvNet as an unified network, including compact network, high generalization ability and excellent performance, e.g., +4.7% on RefCOCO+.
Transformer-based Dual Relation Graph for Multi-label Image Recognition
Oct 12, 2021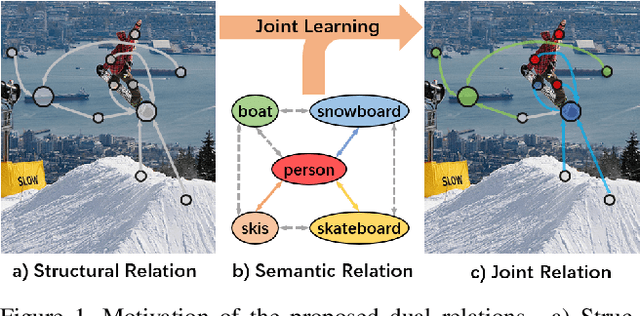

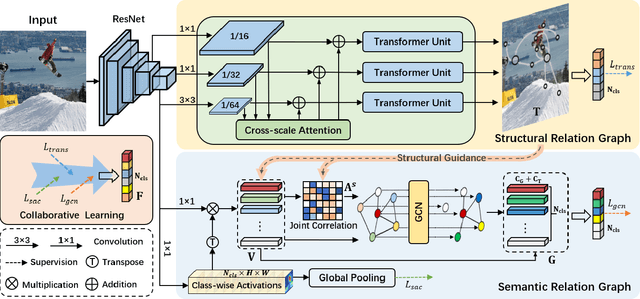
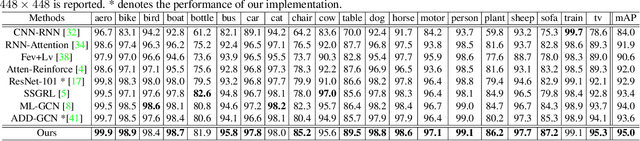
The simultaneous recognition of multiple objects in one image remains a challenging task, spanning multiple events in the recognition field such as various object scales, inconsistent appearances, and confused inter-class relationships. Recent research efforts mainly resort to the statistic label co-occurrences and linguistic word embedding to enhance the unclear semantics. Different from these researches, in this paper, we propose a novel Transformer-based Dual Relation learning framework, constructing complementary relationships by exploring two aspects of correlation, i.e., structural relation graph and semantic relation graph. The structural relation graph aims to capture long-range correlations from object context, by developing a cross-scale transformer-based architecture. The semantic graph dynamically models the semantic meanings of image objects with explicit semantic-aware constraints. In addition, we also incorporate the learnt structural relationship into the semantic graph, constructing a joint relation graph for robust representations. With the collaborative learning of these two effective relation graphs, our approach achieves new state-of-the-art on two popular multi-label recognition benchmarks, i.e., MS-COCO and VOC 2007 dataset.
* 10 pages, 5 figures. Published in ICCV 2021
Fine-grained Data Distribution Alignment for Post-Training Quantization
Sep 09, 2021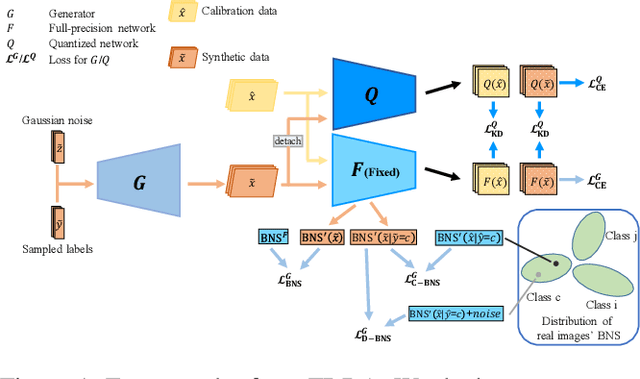
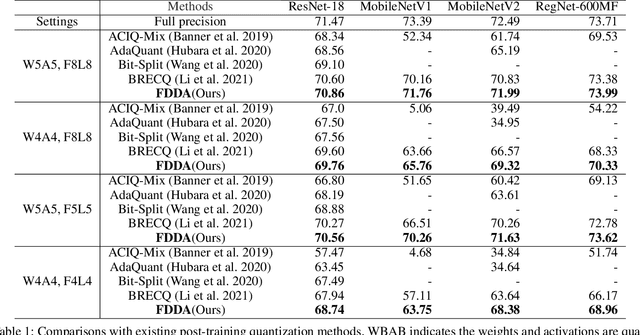

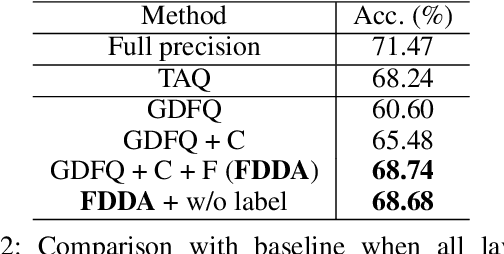
While post-training quantization receives popularity mostly due to its evasion in accessing the original complete training dataset, its poor performance also stems from this limitation. To alleviate this limitation, in this paper, we leverage the synthetic data introduced by zero-shot quantization with calibration dataset and we propose a fine-grained data distribution alignment (FDDA) method to boost the performance of post-training quantization. The method is based on two important properties of batch normalization statistics (BNS) we observed in deep layers of the trained network, i.e., inter-class separation and intra-class incohesion. To preserve this fine-grained distribution information: 1) We calculate the per-class BNS of the calibration dataset as the BNS centers of each class and propose a BNS-centralized loss to force the synthetic data distributions of different classes to be close to their own centers. 2) We add Gaussian noise into the centers to imitate the incohesion and propose a BNS-distorted loss to force the synthetic data distribution of the same class to be close to the distorted centers. By introducing these two fine-grained losses, our method shows the state-of-the-art performance on ImageNet, especially when the first and last layers are quantized to low-bit as well. Our project is available at https://github.com/viperit/FDDA.
Spatiotemporal Inconsistency Learning for DeepFake Video Detection
Sep 07, 2021
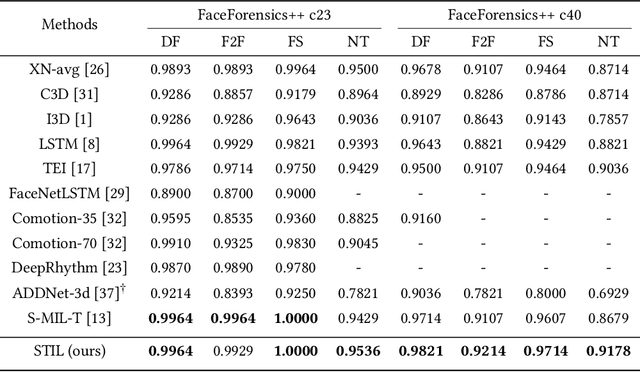
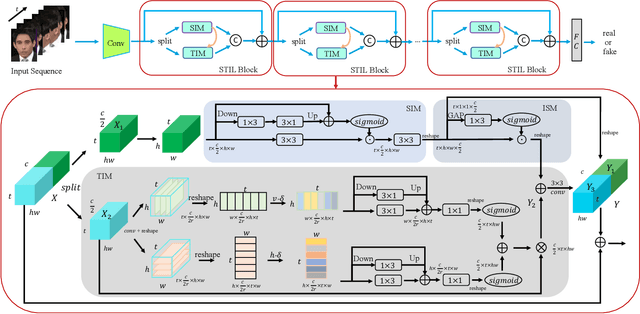
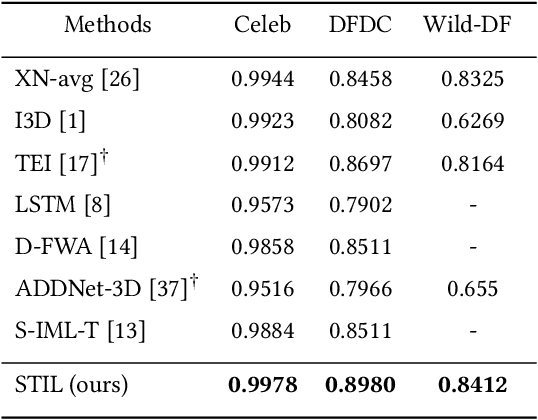
The rapid development of facial manipulation techniques has aroused public concerns in recent years. Following the success of deep learning, existing methods always formulate DeepFake video detection as a binary classification problem and develop frame-based and video-based solutions. However, little attention has been paid to capturing the spatial-temporal inconsistency in forged videos. To address this issue, we term this task as a Spatial-Temporal Inconsistency Learning (STIL) process and instantiate it into a novel STIL block, which consists of a Spatial Inconsistency Module (SIM), a Temporal Inconsistency Module (TIM), and an Information Supplement Module (ISM). Specifically, we present a novel temporal modeling paradigm in TIM by exploiting the temporal difference over adjacent frames along with both horizontal and vertical directions. And the ISM simultaneously utilizes the spatial information from SIM and temporal information from TIM to establish a more comprehensive spatial-temporal representation. Moreover, our STIL block is flexible and could be plugged into existing 2D CNNs. Extensive experiments and visualizations are presented to demonstrate the effectiveness of our method against the state-of-the-art competitors.
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
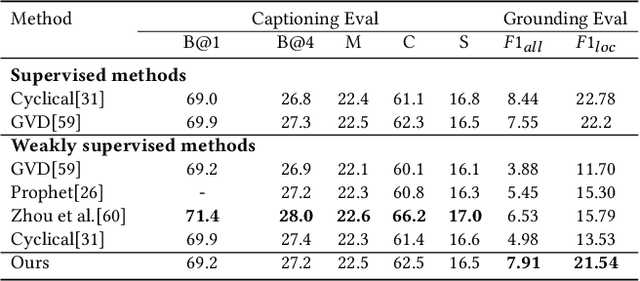
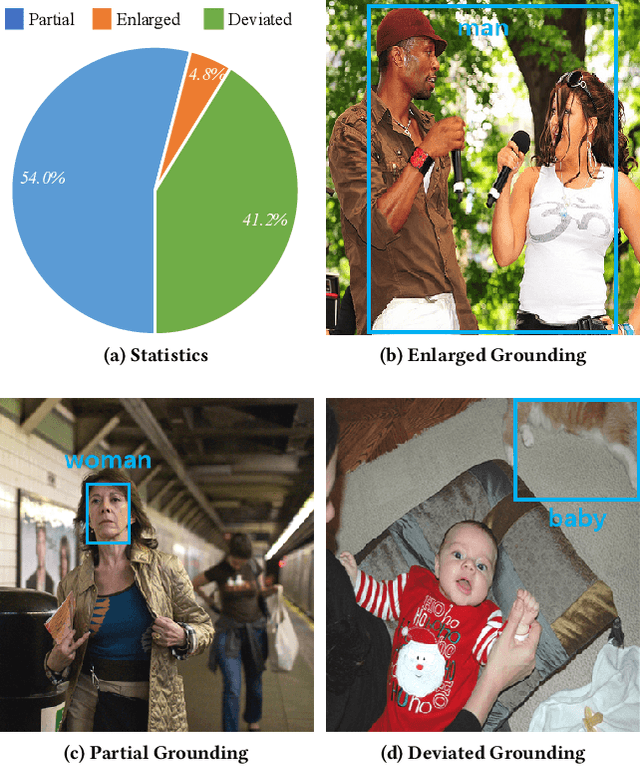
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
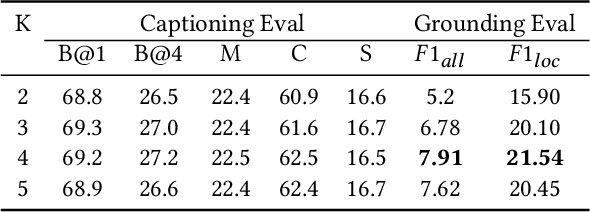
Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework
Aug 07, 2021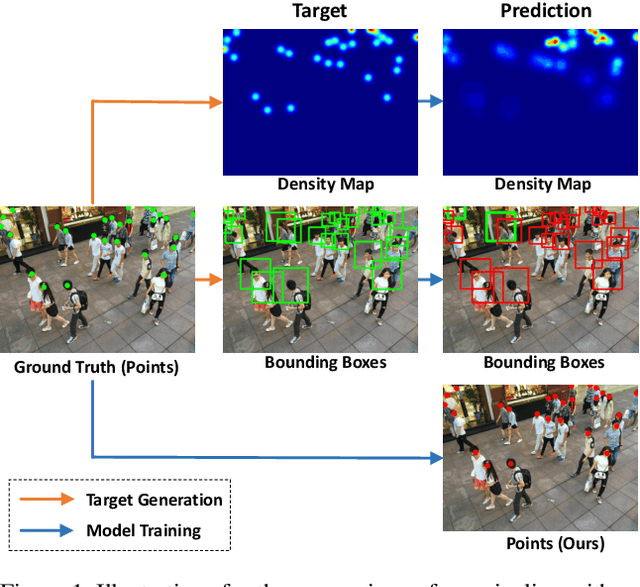
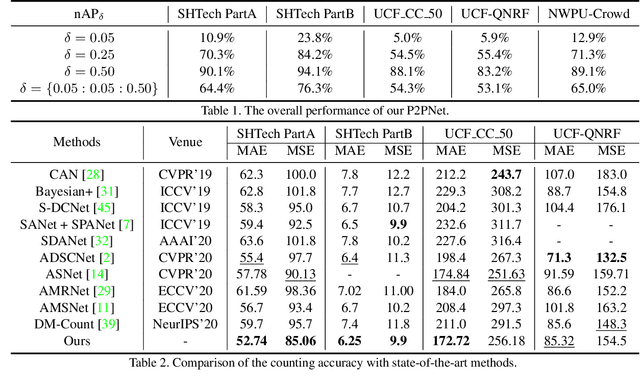
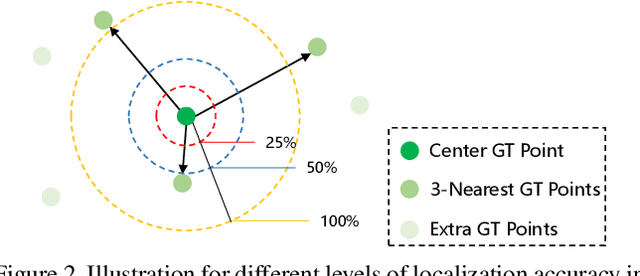
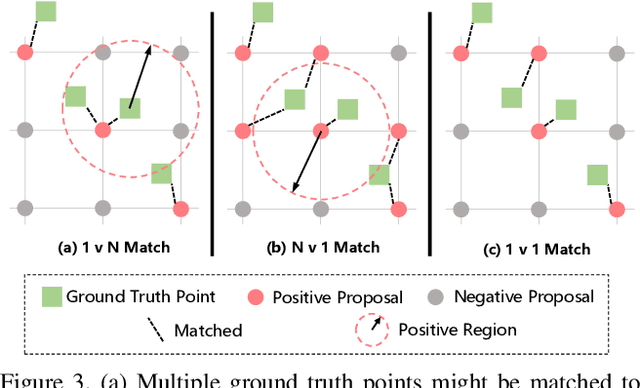
Localizing individuals in crowds is more in accordance with the practical demands of subsequent high-level crowd analysis tasks than simply counting. However, existing localization based methods relying on intermediate representations (\textit{i.e.}, density maps or pseudo boxes) serving as learning targets are counter-intuitive and error-prone. In this paper, we propose a purely point-based framework for joint crowd counting and individual localization. For this framework, instead of merely reporting the absolute counting error at image level, we propose a new metric, called density Normalized Average Precision (nAP), to provide more comprehensive and more precise performance evaluation. Moreover, we design an intuitive solution under this framework, which is called Point to Point Network (P2PNet). P2PNet discards superfluous steps and directly predicts a set of point proposals to represent heads in an image, being consistent with the human annotation results. By thorough analysis, we reveal the key step towards implementing such a novel idea is to assign optimal learning targets for these proposals. Therefore, we propose to conduct this crucial association in an one-to-one matching manner using the Hungarian algorithm. The P2PNet not only significantly surpasses state-of-the-art methods on popular counting benchmarks, but also achieves promising localization accuracy. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet.