 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoVista: Visually Grounded Active Perception for Ultra-High-Resolution Remote Sensing Understanding
May 14, 2026Interpreting ultra-high-resolution (UHR) remote sensing images requires models to search for sparse and tiny visual evidence across large-scale scenes. Existing remote sensing vision-language models can inspect local regions with zooming and cropping tools, but most exploration strategies follow either a one-shot focus or a single sequential trajectory. Such single-path exploration can lose global context, leave scattered regions unvisited, and revisit or count the same evidence multiple times. To this end, we propose GeoVista, a planning-driven active perception framework for UHR remote sensing interpretation. Instead of committing to one zooming path, GeoVista first builds a global exploration plan, then verifies multiple candidate regions through branch-wise local inspection, while maintaining an explicit evidence state for cross-region aggregation and de-duplication. To enable this behavior, we introduce APEX-GRO, a cold-start supervised trajectory corpus that reformulates diverse UHR tasks as Global-Region-Object interactive reasoning processes with a unified, scale-invariant spatial representation. We further design an Observe-Plan-Track mechanism for global observation, adaptive region inspection, and evidence tracking, and align the model with a GRPO-based strategy using step-wise rewards for planning, localization, and final answer correctness. Experiments on RSHR-Bench, XLRS-Bench, and LRS-VQA show that GeoVista achieves state-of-the-art performance. Code and dataset are available at https://github.com/ryan6073/GeoVista
GeoAlignCLIP: Enhancing Fine-Grained Vision-Language Alignment in Remote Sensing via Multi-Granular Consistency Learning
Mar 10, 2026Vision-language pretraining models have made significant progress in bridging remote sensing imagery with natural language. However, existing approaches often fail to effectively integrate multi-granular visual and textual information, relying primarily on global image-text alignment. This limitation hinders the model's ability to accurately capture fine-grained details in images, thus restricting its performance in complex, fine-grained tasks. To address this, we propose GeoAlignCLIP, a unified framework that achieves fine-grained alignment in remote sensing tasks by learning multi-granular semantic alignments and incorporating intra-modal consistency, enabling more precise visual-semantic alignment between image regions and text concepts. Additionally, we construct RSFG-100k, a fine-granular remote sensing dataset containing scene descriptions, region-level annotations, and challenging hard-negative samples, providing hierarchical supervision for model training. Extensive experiments conducted on multiple public remote-sensing benchmarks demonstrate that GeoAlignCLIP consistently outperforms existing RS-specific methods across diverse tasks, exhibiting more robust and accurate fine-grained vision-language alignment.
OmniEarth: A Benchmark for Evaluating Vision-Language Models in Geospatial Tasks
Mar 10, 2026Vision-Language Models (VLMs) have demonstrated effective perception and reasoning capabilities on general-domain tasks, leading to growing interest in their application to Earth observation. However, a systematic benchmark for comprehensively evaluating remote sensing vision-language models (RSVLMs) remains lacking. To address this gap, we introduce OmniEarth, a benchmark for evaluating RSVLMs under realistic Earth observation scenarios. OmniEarth organizes tasks along three capability dimensions: perception, reasoning, and robustness. It defines 28 fine-grained tasks covering multi-source sensing data and diverse geospatial contexts. The benchmark supports two task formulations: multiple-choice VQA and open-ended VQA. The latter includes pure text outputs for captioning tasks, bounding box outputs for visual grounding tasks, and mask outputs for segmentation tasks. To reduce linguistic bias and examine whether model predictions rely on visual evidence, OmniEarth adopts a blind test protocol and a quintuple semantic consistency requirement. OmniEarth includes 9,275 carefully quality-controlled images, including proprietary satellite imagery from Jilin-1 (JL-1), along with 44,210 manually verified instructions. We conduct a systematic evaluation of contrastive learning-based models, general closed-source and open-source VLMs, as well as RSVLMs. Results show that existing VLMs still struggle with geospatially complex tasks, revealing clear gaps that need to be addressed for remote sensing applications. OmniEarth is publicly available at https://huggingface.co/datasets/sjeeudd/OmniEarth.
Dual Relation Mining Network for Zero-Shot Learning
May 06, 2024Zero-shot learning (ZSL) aims to recognize novel classes through transferring shared semantic knowledge (e.g., attributes) from seen classes to unseen classes. Recently, attention-based methods have exhibited significant progress which align visual features and attributes via a spatial attention mechanism. However, these methods only explore visual-semantic relationship in the spatial dimension, which can lead to classification ambiguity when different attributes share similar attention regions, and semantic relationship between attributes is rarely discussed. To alleviate the above problems, we propose a Dual Relation Mining Network (DRMN) to enable more effective visual-semantic interactions and learn semantic relationship among attributes for knowledge transfer. Specifically, we introduce a Dual Attention Block (DAB) for visual-semantic relationship mining, which enriches visual information by multi-level feature fusion and conducts spatial attention for visual to semantic embedding. Moreover, an attribute-guided channel attention is utilized to decouple entangled semantic features. For semantic relationship modeling, we utilize a Semantic Interaction Transformer (SIT) to enhance the generalization of attribute representations among images. Additionally, a global classification branch is introduced as a complement to human-defined semantic attributes, and we then combine the results with attribute-based classification. Extensive experiments demonstrate that the proposed DRMN leads to new state-of-the-art performances on three standard ZSL benchmarks, i.e., CUB, SUN, and AwA2.
Anchor-based Robust Finetuning of Vision-Language Models
Apr 09, 2024



We aim at finetuning a vision-language model without hurting its out-of-distribution (OOD) generalization. We address two types of OOD generalization, i.e., i) domain shift such as natural to sketch images, and ii) zero-shot capability to recognize the category that was not contained in the finetune data. Arguably, the diminished OOD generalization after finetuning stems from the excessively simplified finetuning target, which only provides the class information, such as ``a photo of a [CLASS]''. This is distinct from the process in that CLIP was pretrained, where there is abundant text supervision with rich semantic information. Therefore, we propose to compensate for the finetune process using auxiliary supervision with rich semantic information, which acts as anchors to preserve the OOD generalization. Specifically, two types of anchors are elaborated in our method, including i) text-compensated anchor which uses the images from the finetune set but enriches the text supervision from a pretrained captioner, ii) image-text-pair anchor which is retrieved from the dataset similar to pretraining data of CLIP according to the downstream task, associating with the original CLIP text with rich semantics. Those anchors are utilized as auxiliary semantic information to maintain the original feature space of CLIP, thereby preserving the OOD generalization capabilities. Comprehensive experiments demonstrate that our method achieves in-distribution performance akin to conventional finetuning while attaining new state-of-the-art results on domain shift and zero-shot learning benchmarks.
VMT-Adapter: Parameter-Efficient Transfer Learning for Multi-Task Dense Scene Understanding
Dec 15, 2023Large-scale pre-trained models have achieved remarkable success in various computer vision tasks. A standard approach to leverage these models is to fine-tune all model parameters for downstream tasks, which poses challenges in terms of computational and storage costs. Recently, inspired by Natural Language Processing (NLP), parameter-efficient transfer learning has been successfully applied to vision tasks. However, most existing techniques primarily focus on single-task adaptation, and despite limited research on multi-task adaptation, these methods often exhibit suboptimal training and inference efficiency. In this paper, we first propose an once-for-all Vision Multi-Task Adapter (VMT-Adapter), which strikes approximately O(1) training and inference efficiency w.r.t task number. Concretely, VMT-Adapter shares the knowledge from multiple tasks to enhance cross-task interaction while preserves task-specific knowledge via independent knowledge extraction modules. Notably, since task-specific modules require few parameters, VMT-Adapter can handle an arbitrary number of tasks with a negligible increase of trainable parameters. We also propose VMT-Adapter-Lite, which further reduces the trainable parameters by learning shared parameters between down- and up-projections. Extensive experiments on four dense scene understanding tasks demonstrate the superiority of VMT-Adapter(-Lite), achieving a 3.96%(1.34%) relative improvement compared to single-task full fine-tuning, while utilizing merely ~1% (0.36%) trainable parameters of the pre-trained model.
HODN: Disentangling Human-Object Feature for HOI Detection
Aug 20, 2023



The task of Human-Object Interaction (HOI) detection is to detect humans and their interactions with surrounding objects, where transformer-based methods show dominant advances currently. However, these methods ignore the relationship among humans, objects, and interactions: 1) human features are more contributive than object ones to interaction prediction; 2) interactive information disturbs the detection of objects but helps human detection. In this paper, we propose a Human and Object Disentangling Network (HODN) to model the HOI relationships explicitly, where humans and objects are first detected by two disentangling decoders independently and then processed by an interaction decoder. Considering that human features are more contributive to interaction, we propose a Human-Guide Linking method to make sure the interaction decoder focuses on the human-centric regions with human features as the positional embeddings. To handle the opposite influences of interactions on humans and objects, we propose a Stop-Gradient Mechanism to stop interaction gradients from optimizing the object detection but to allow them to optimize the human detection. Our proposed method achieves competitive performance on both the V-COCO and the HICO-Det datasets. It can be combined with existing methods easily for state-of-the-art results.
Distributed Attention for Grounded Image Captioning
Aug 22, 2021
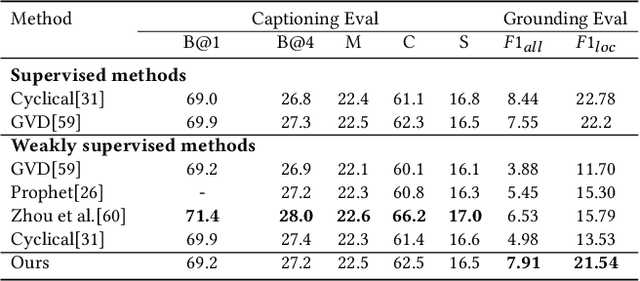
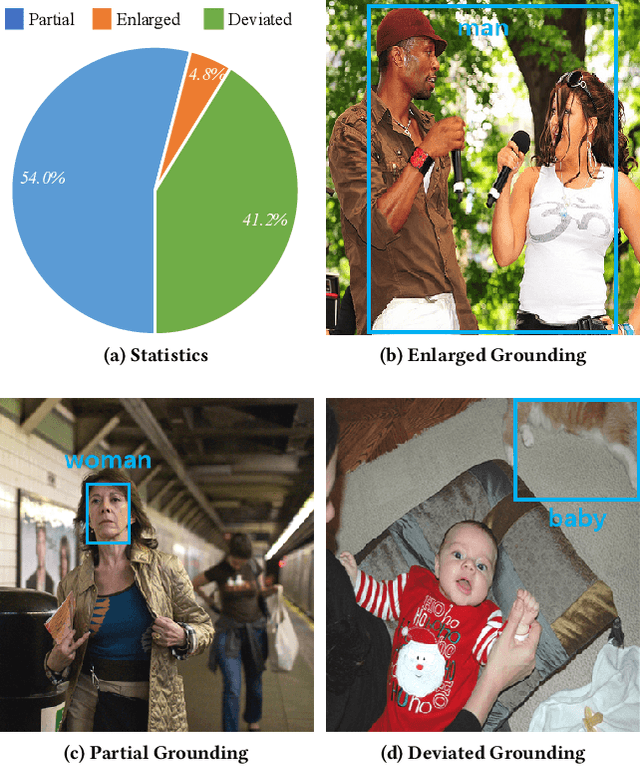
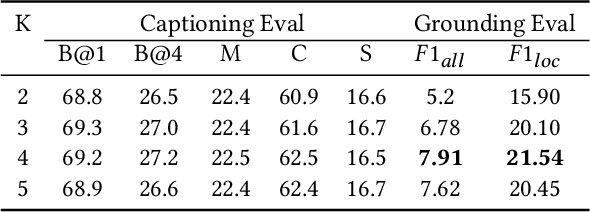
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
Unveiling the Potential of Structure Preserving for Weakly Supervised Object Localization
Mar 30, 2021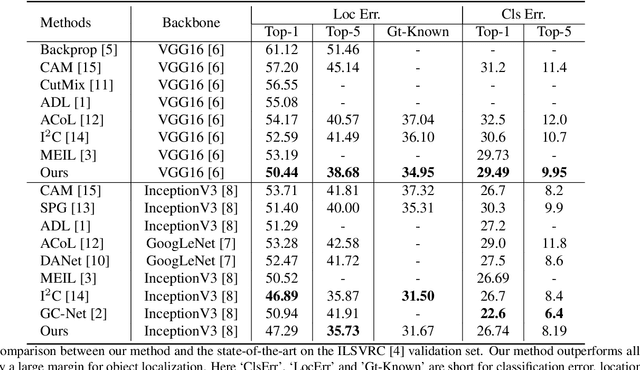

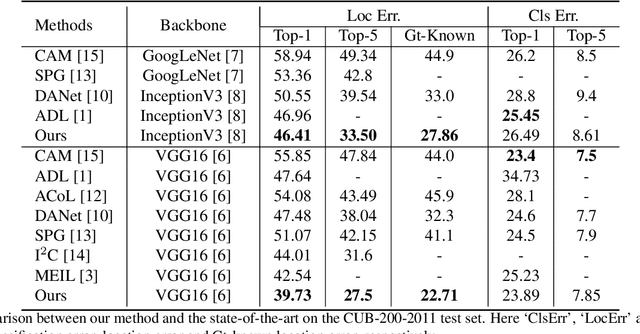
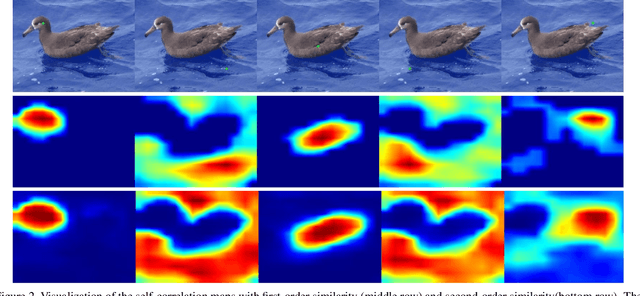
Weakly supervised object localization(WSOL) remains an open problem given the deficiency of finding object extent information using a classification network. Although prior works struggled to localize objects through various spatial regularization strategies, we argue that how to extract object structural information from the trained classification network is neglected. In this paper, we propose a two-stage approach, termed structure-preserving activation (SPA), toward fully leveraging the structure information incorporated in convolutional features for WSOL. First, a restricted activation module (RAM) is designed to alleviate the structure-missing issue caused by the classification network on the basis of the observation that the unbounded classification map and global average pooling layer drive the network to focus only on object parts. Second, we designed a post-process approach, termed self-correlation map generating (SCG) module to obtain structure-preserving localization maps on the basis of the activation maps acquired from the first stage. Specifically, we utilize the high-order self-correlation (HSC) to extract the inherent structural information retained in the learned model and then aggregate HSC of multiple points for precise object localization. Extensive experiments on two publicly available benchmarks including CUB-200-2011 and ILSVRC show that the proposed SPA achieves substantial and consistent performance gains compared with baseline approaches.Code and models are available at https://github.com/Panxjia/SPA_CVPR2021