 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Policy Optimization via Analytic Dynamics Regularization
Mar 15, 2026Reinforcement learning (RL) has achieved strong performance in robotic control; however, state-of-the-art policy learning methods, such as actor-critic methods, still suffer from high sample complexity and often produce physically inconsistent actions. This limitation stems from neural policies implicitly rediscovering complex physics from data alone, despite accurate dynamics models being readily available in simulators. In this paper, we introduce a novel physics-informed RL framework, called PIPER, that seamlessly integrates physical constraints directly into neural policy optimization with analytical soft physics constraints. At the core of our method is the integration of a differentiable Lagrangian residual as a regularization term within the actor's objective. This residual, extracted from a robot's simulator description, subtly biases policy updates towards dynamically consistent solutions. Crucially, this physics integration is realized through an additional loss term during policy optimization, requiring no alterations to existing simulators or core RL algorithms. Extensive experiments demonstrate that our method significantly improves learning efficiency, stability, and control accuracy, establishing a new paradigm for efficient and physically consistent robotic control.
Learning Diffusion Policy from Primitive Skills for Robot Manipulation
Jan 05, 2026Diffusion policies (DP) have recently shown great promise for generating actions in robotic manipulation. However, existing approaches often rely on global instructions to produce short-term control signals, which can result in misalignment in action generation. We conjecture that the primitive skills, referred to as fine-grained, short-horizon manipulations, such as ``move up'' and ``open the gripper'', provide a more intuitive and effective interface for robot learning. To bridge this gap, we propose SDP, a skill-conditioned DP that integrates interpretable skill learning with conditional action planning. SDP abstracts eight reusable primitive skills across tasks and employs a vision-language model to extract discrete representations from visual observations and language instructions. Based on them, a lightweight router network is designed to assign a desired primitive skill for each state, which helps construct a single-skill policy to generate skill-aligned actions. By decomposing complex tasks into a sequence of primitive skills and selecting a single-skill policy, SDP ensures skill-consistent behavior across diverse tasks. Extensive experiments on two challenging simulation benchmarks and real-world robot deployments demonstrate that SDP consistently outperforms SOTA methods, providing a new paradigm for skill-based robot learning with diffusion policies.
Zeroth-Order Stochastic Mirror Descent Algorithms for Minimax Excess Risk Optimization
Aug 22, 2024The minimax excess risk optimization (MERO) problem is a new variation of the traditional distributionally robust optimization (DRO) problem, which achieves uniformly low regret across all test distributions under suitable conditions. In this paper, we propose a zeroth-order stochastic mirror descent (ZO-SMD) algorithm available for both smooth and non-smooth MERO to estimate the minimal risk of each distrbution, and finally solve MERO as (non-)smooth stochastic convex-concave (linear) minimax optimization problems. The proposed algorithm is proved to converge at optimal convergence rates of $\mathcal{O}\left(1/\sqrt{t}\right)$ on the estimate of $R_i^*$ and $\mathcal{O}\left(1/\sqrt{t}\right)$ on the optimization error of both smooth and non-smooth MERO. Numerical results show the efficiency of the proposed algorithm.
Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection
Mar 19, 2024Industrial anomaly detection (IAD) has garnered significant attention and experienced rapid development. However, the recent development of IAD approach has encountered certain difficulties due to dataset limitations. On the one hand, most of the state-of-the-art methods have achieved saturation (over 99% in AUROC) on mainstream datasets such as MVTec, and the differences of methods cannot be well distinguished, leading to a significant gap between public datasets and actual application scenarios. On the other hand, the research on various new practical anomaly detection settings is limited by the scale of the dataset, posing a risk of overfitting in evaluation results. Therefore, we propose a large-scale, Real-world, and multi-view Industrial Anomaly Detection dataset, named Real-IAD, which contains 150K high-resolution images of 30 different objects, an order of magnitude larger than existing datasets. It has a larger range of defect area and ratio proportions, making it more challenging than previous datasets. To make the dataset closer to real application scenarios, we adopted a multi-view shooting method and proposed sample-level evaluation metrics. In addition, beyond the general unsupervised anomaly detection setting, we propose a new setting for Fully Unsupervised Industrial Anomaly Detection (FUIAD) based on the observation that the yield rate in industrial production is usually greater than 60%, which has more practical application value. Finally, we report the results of popular IAD methods on the Real-IAD dataset, providing a highly challenging benchmark to promote the development of the IAD field.
Towards Artistic Image Aesthetics Assessment: a Large-scale Dataset and a New Method
Mar 27, 2023
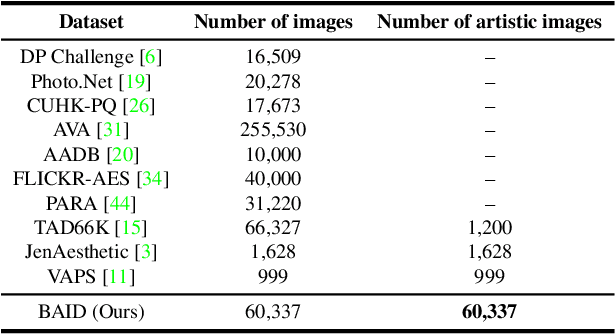
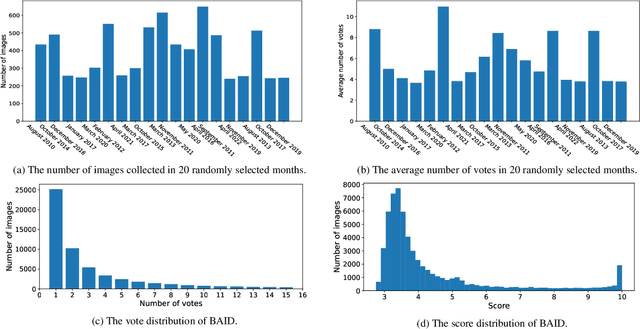

Image aesthetics assessment (IAA) is a challenging task due to its highly subjective nature. Most of the current studies rely on large-scale datasets (e.g., AVA and AADB) to learn a general model for all kinds of photography images. However, little light has been shed on measuring the aesthetic quality of artistic images, and the existing datasets only contain relatively few artworks. Such a defect is a great obstacle to the aesthetic assessment of artistic images. To fill the gap in the field of artistic image aesthetics assessment (AIAA), we first introduce a large-scale AIAA dataset: Boldbrush Artistic Image Dataset (BAID), which consists of 60,337 artistic images covering various art forms, with more than 360,000 votes from online users. We then propose a new method, SAAN (Style-specific Art Assessment Network), which can effectively extract and utilize style-specific and generic aesthetic information to evaluate artistic images. Experiments demonstrate that our proposed approach outperforms existing IAA methods on the proposed BAID dataset according to quantitative comparisons. We believe the proposed dataset and method can serve as a foundation for future AIAA works and inspire more research in this field. Dataset and code are available at: https://github.com/Dreemurr-T/BAID.git
Spatiotemporal Inconsistency Learning for DeepFake Video Detection
Sep 07, 2021
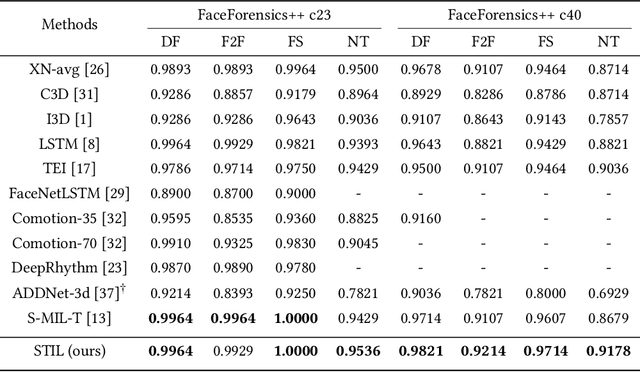
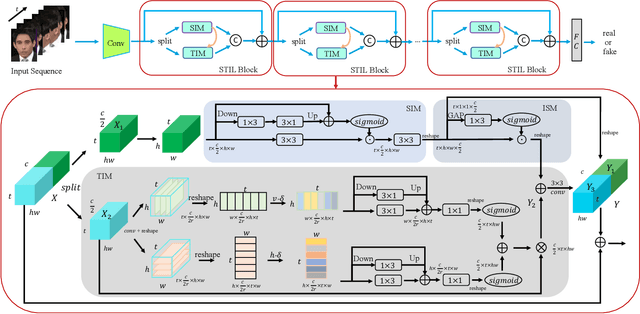
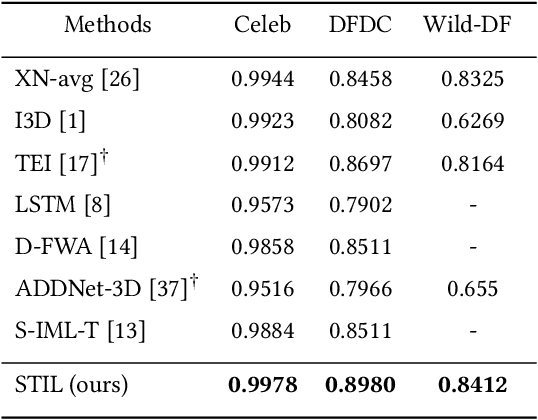
The rapid development of facial manipulation techniques has aroused public concerns in recent years. Following the success of deep learning, existing methods always formulate DeepFake video detection as a binary classification problem and develop frame-based and video-based solutions. However, little attention has been paid to capturing the spatial-temporal inconsistency in forged videos. To address this issue, we term this task as a Spatial-Temporal Inconsistency Learning (STIL) process and instantiate it into a novel STIL block, which consists of a Spatial Inconsistency Module (SIM), a Temporal Inconsistency Module (TIM), and an Information Supplement Module (ISM). Specifically, we present a novel temporal modeling paradigm in TIM by exploiting the temporal difference over adjacent frames along with both horizontal and vertical directions. And the ISM simultaneously utilizes the spatial information from SIM and temporal information from TIM to establish a more comprehensive spatial-temporal representation. Moreover, our STIL block is flexible and could be plugged into existing 2D CNNs. Extensive experiments and visualizations are presented to demonstrate the effectiveness of our method against the state-of-the-art competitors.