 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Data: Effectively Substitute Training for Black-box Attack
Apr 26, 2021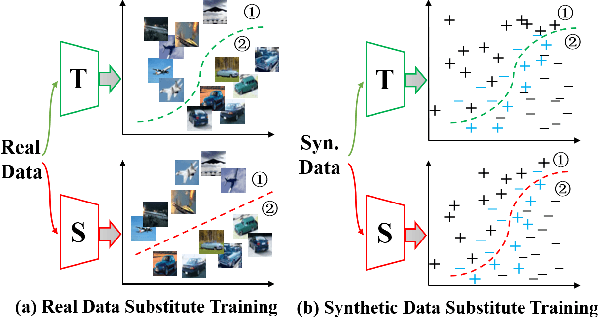
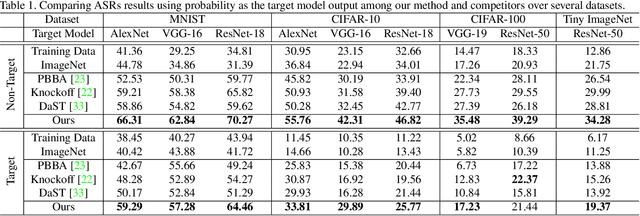
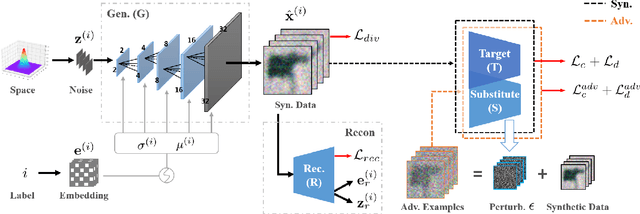
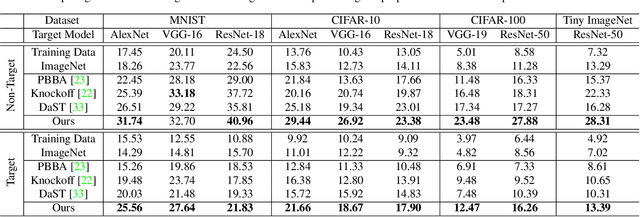
Deep models have shown their vulnerability when processing adversarial samples. As for the black-box attack, without access to the architecture and weights of the attacked model, training a substitute model for adversarial attacks has attracted wide attention. Previous substitute training approaches focus on stealing the knowledge of the target model based on real training data or synthetic data, without exploring what kind of data can further improve the transferability between the substitute and target models. In this paper, we propose a novel perspective substitute training that focuses on designing the distribution of data used in the knowledge stealing process. More specifically, a diverse data generation module is proposed to synthesize large-scale data with wide distribution. And adversarial substitute training strategy is introduced to focus on the data distributed near the decision boundary. The combination of these two modules can further boost the consistency of the substitute model and target model, which greatly improves the effectiveness of adversarial attack. Extensive experiments demonstrate the efficacy of our method against state-of-the-art competitors under non-target and target attack settings. Detailed visualization and analysis are also provided to help understand the advantage of our method.
Carrying out CNN Channel Pruning in a White Box
Apr 24, 2021
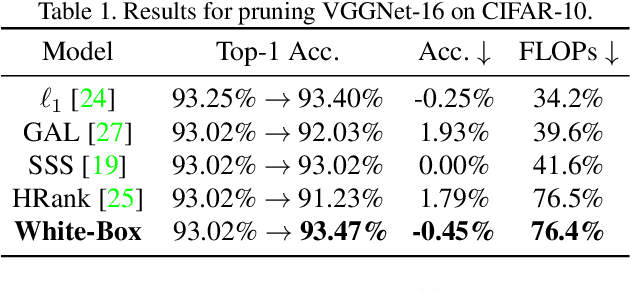
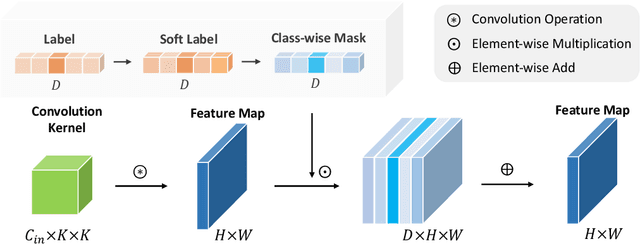
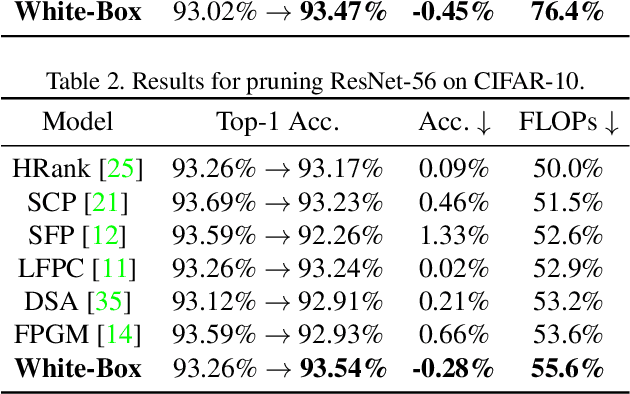
Channel Pruning has been long adopted for compressing CNNs, which significantly reduces the overall computation. Prior works implement channel pruning in an unexplainable manner, which tends to reduce the final classification errors while failing to consider the internal influence of each channel. In this paper, we conduct channel pruning in a white box. Through deep visualization of feature maps activated by different channels, we observe that different channels have a varying contribution to different categories in image classification. Inspired by this, we choose to preserve channels contributing to most categories. Specifically, to model the contribution of each channel to differentiating categories, we develop a class-wise mask for each channel, implemented in a dynamic training manner w.r.t. the input image's category. On the basis of the learned class-wise mask, we perform a global voting mechanism to remove channels with less category discrimination. Lastly, a fine-tuning process is conducted to recover the performance of the pruned model. To our best knowledge, it is the first time that CNN interpretability theory is considered to guide channel pruning. Extensive experiments demonstrate the superiority of our White-Box over many state-of-the-arts. For instance, on CIFAR-10, it reduces 65.23% FLOPs with even 0.62% accuracy improvement for ResNet-110. On ILSVRC-2012, White-Box achieves a 45.6% FLOPs reduction with only a small loss of 0.83% in the top-1 accuracy for ResNet-50. Code, training logs and pruned models are anonymously at https://github.com/zyxxmu/White-Box.
DisCo: Remedy Self-supervised Learning on Lightweight Models with Distilled Contrastive Learning
Apr 19, 2021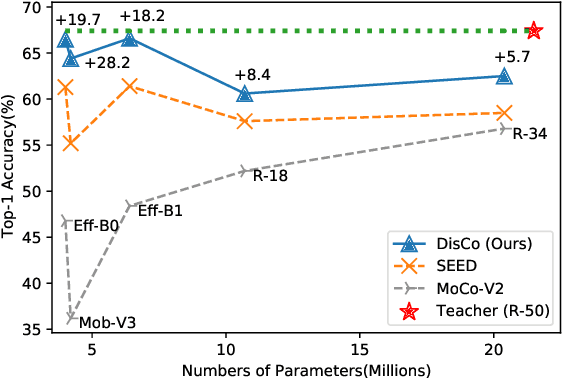
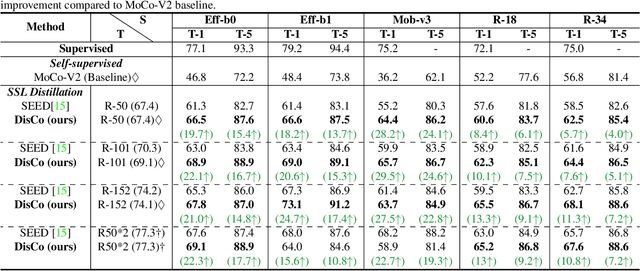
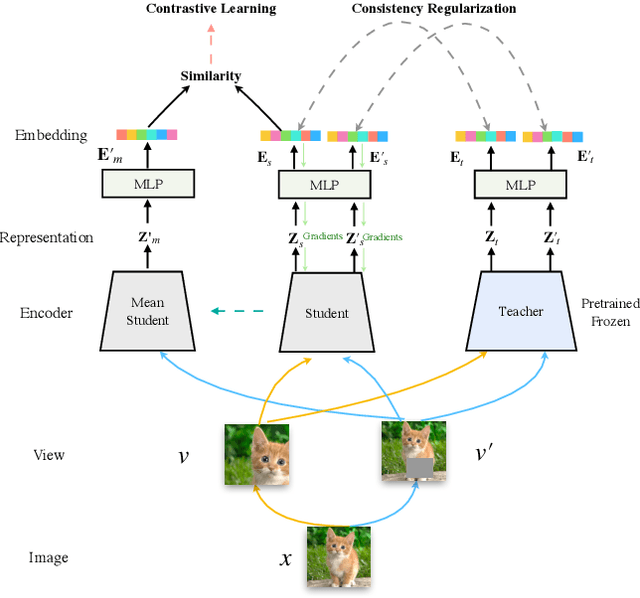
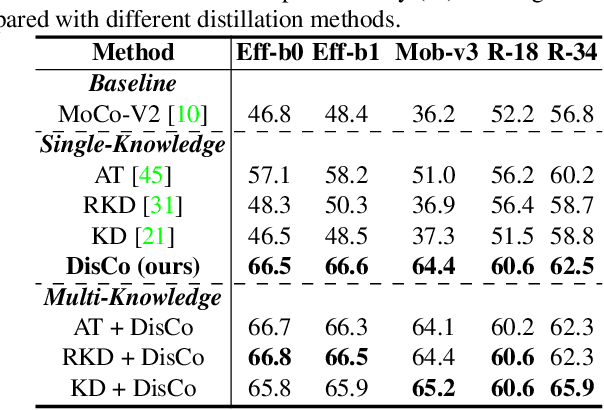
While self-supervised representation learning (SSL) has received widespread attention from the community, recent research argue that its performance will suffer a cliff fall when the model size decreases. The current method mainly relies on contrastive learning to train the network and in this work, we propose a simple yet effective Distilled Contrastive Learning (DisCo) to ease the issue by a large margin. Specifically, we find the final embedding obtained by the mainstream SSL methods contains the most fruitful information, and propose to distill the final embedding to maximally transmit a teacher's knowledge to a lightweight model by constraining the last embedding of the student to be consistent with that of the teacher. In addition, in the experiment, we find that there exists a phenomenon termed Distilling BottleNeck and present to enlarge the embedding dimension to alleviate this problem. Our method does not introduce any extra parameter to lightweight models during deployment. Experimental results demonstrate that our method achieves the state-of-the-art on all lightweight models. Particularly, when ResNet-101/ResNet-50 is used as teacher to teach EfficientNet-B0, the linear result of EfficientNet-B0 on ImageNet is very close to ResNet-101/ResNet-50, but the number of parameters of EfficientNet-B0 is only 9.4%/16.3% of ResNet-101/ResNet-50.
Lottery Jackpots Exist in Pre-trained Models
Apr 18, 2021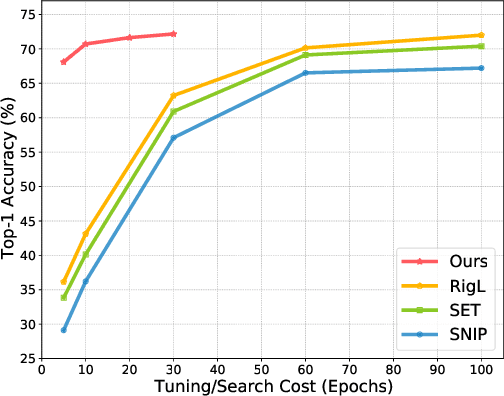
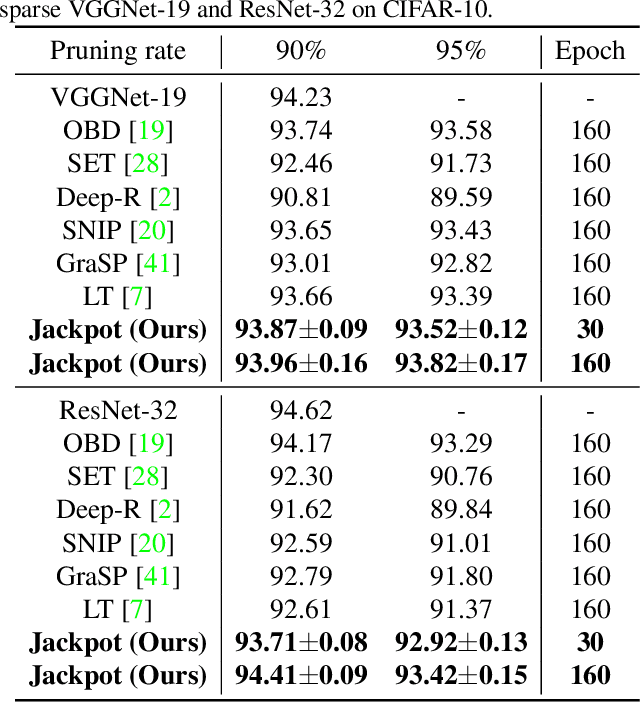
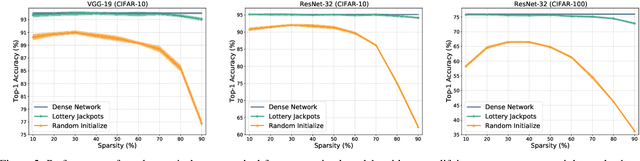
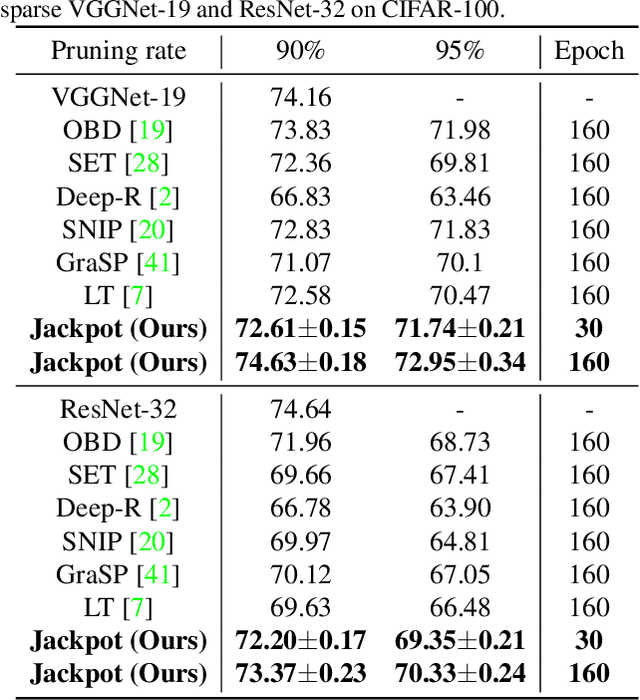
Network pruning is an effective approach to reduce network complexity without performance compromise. Existing studies achieve the sparsity of neural networks via time-consuming weight tuning or complex search on networks with expanded width, which greatly limits the applications of network pruning. In this paper, we show that high-performing and sparse sub-networks without the involvement of weight tuning, termed "lottery jackpots", exist in pre-trained models with unexpanded width. For example, we obtain a lottery jackpot that has only 10% parameters and still reaches the performance of the original dense VGGNet-19 without any modifications on the pre-trained weights. Furthermore, we observe that the sparse masks derived from many existing pruning criteria have a high overlap with the searched mask of our lottery jackpot, among which, the magnitude-based pruning results in the most similar mask with ours. Based on this insight, we initialize our sparse mask using the magnitude pruning, resulting in at least 3x cost reduction on the lottery jackpot search while achieves comparable or even better performance. Specifically, our magnitude-based lottery jackpot removes 90% weights in the ResNet-50, while easily obtains more than 70% top-1 accuracy using only 10 searching epochs on ImageNet.
Unveiling the Potential of Structure Preserving for Weakly Supervised Object Localization
Mar 30, 2021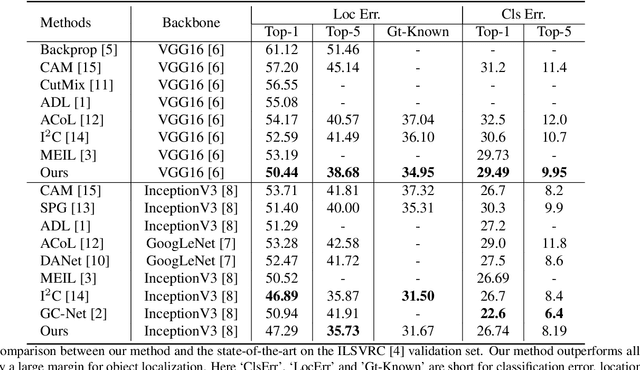

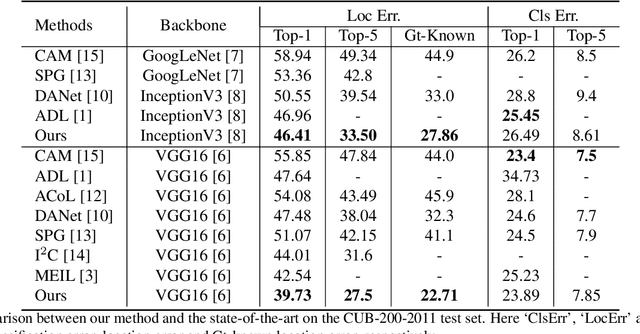
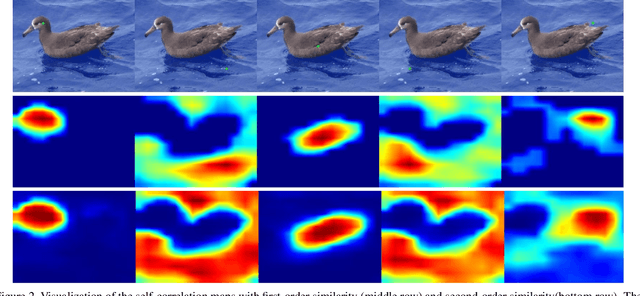
Weakly supervised object localization(WSOL) remains an open problem given the deficiency of finding object extent information using a classification network. Although prior works struggled to localize objects through various spatial regularization strategies, we argue that how to extract object structural information from the trained classification network is neglected. In this paper, we propose a two-stage approach, termed structure-preserving activation (SPA), toward fully leveraging the structure information incorporated in convolutional features for WSOL. First, a restricted activation module (RAM) is designed to alleviate the structure-missing issue caused by the classification network on the basis of the observation that the unbounded classification map and global average pooling layer drive the network to focus only on object parts. Second, we designed a post-process approach, termed self-correlation map generating (SCG) module to obtain structure-preserving localization maps on the basis of the activation maps acquired from the first stage. Specifically, we utilize the high-order self-correlation (HSC) to extract the inherent structural information retained in the learned model and then aggregate HSC of multiple points for precise object localization. Extensive experiments on two publicly available benchmarks including CUB-200-2011 and ILSVRC show that the proposed SPA achieves substantial and consistent performance gains compared with baseline approaches.Code and models are available at https://github.com/Panxjia/SPA_CVPR2021
Distilling a Powerful Student Model via Online Knowledge Distillation
Mar 29, 2021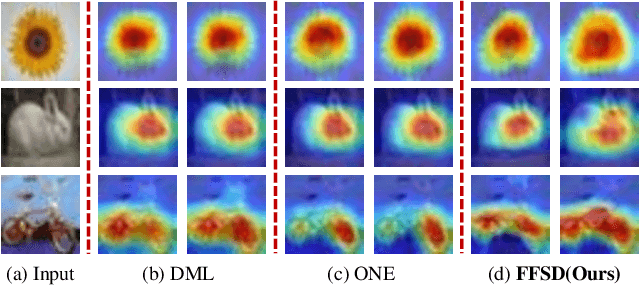
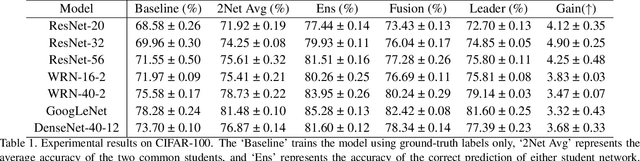
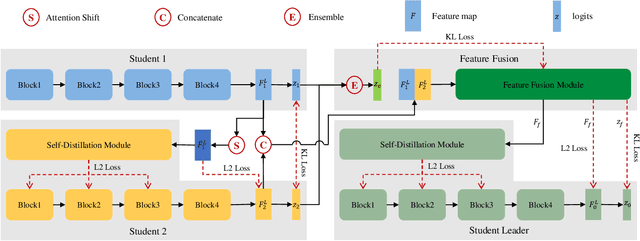
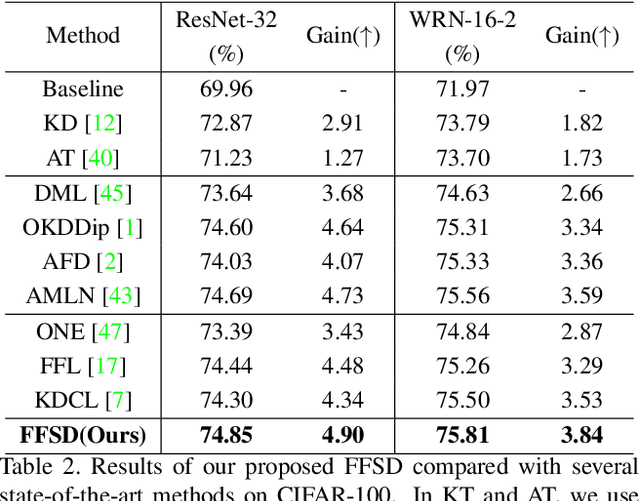
Existing online knowledge distillation approaches either adopt the student with the best performance or construct an ensemble model for better holistic performance. However, the former strategy ignores other students' information, while the latter increases the computational complexity. In this paper, we propose a novel method for online knowledge distillation, termed FFSD, which comprises two key components: Feature Fusion and Self-Distillation, towards solving the above problems in a unified framework. Different from previous works, where all students are treated equally, the proposed FFSD splits them into a student leader and a common student set. Then, the feature fusion module converts the concatenation of feature maps from all common students into a fused feature map. The fused representation is used to assist the learning of the student leader. To enable the student leader to absorb more diverse information, we design an enhancement strategy to increase the diversity among students. Besides, a self-distillation module is adopted to convert the feature map of deeper layers into a shallower one. Then, the shallower layers are encouraged to mimic the transformed feature maps of the deeper layers, which helps the students to generalize better. After training, we simply adopt the student leader, which achieves superior performance, over the common students, without increasing the storage or inference cost. Extensive experiments on CIFAR-100 and ImageNet demonstrate the superiority of our FFSD over existing works. The code is available at https://github.com/SJLeo/FFSD.
Learning Dynamic Alignment via Meta-filter for Few-shot Learning
Mar 25, 2021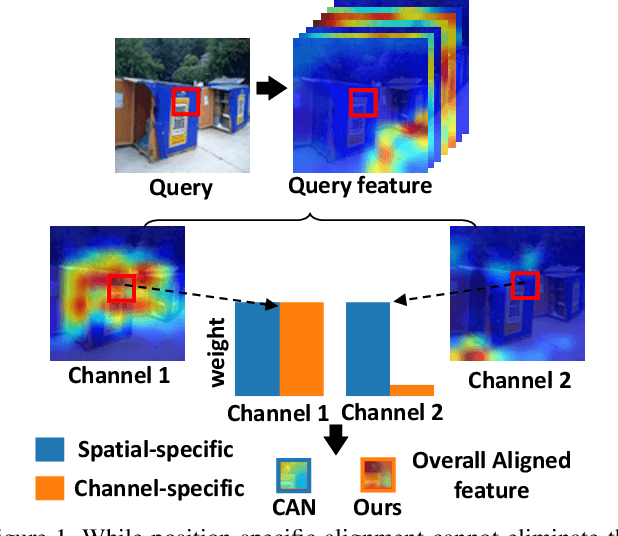
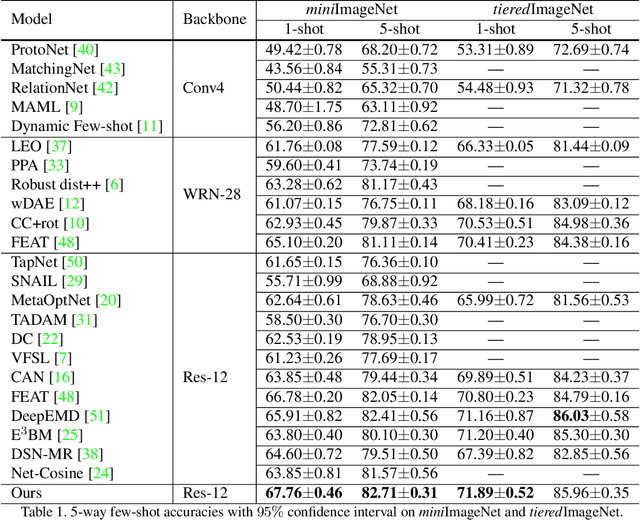
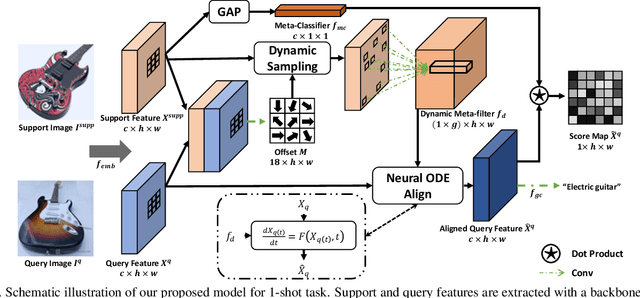

Few-shot learning (FSL), which aims to recognise new classes by adapting the learned knowledge with extremely limited few-shot (support) examples, remains an important open problem in computer vision. Most of the existing methods for feature alignment in few-shot learning only consider image-level or spatial-level alignment while omitting the channel disparity. Our insight is that these methods would lead to poor adaptation with redundant matching, and leveraging channel-wise adjustment is the key to well adapting the learned knowledge to new classes. Therefore, in this paper, we propose to learn a dynamic alignment, which can effectively highlight both query regions and channels according to different local support information. Specifically, this is achieved by first dynamically sampling the neighbourhood of the feature position conditioned on the input few shot, based on which we further predict a both position-dependent and channel-dependent Dynamic Meta-filter. The filter is used to align the query feature with position-specific and channel-specific knowledge. Moreover, we adopt Neural Ordinary Differential Equation (ODE) to enable a more accurate control of the alignment. In such a sense our model is able to better capture fine-grained semantic context of the few-shot example and thus facilitates dynamical knowledge adaptation for few-shot learning. The resulting framework establishes the new state-of-the-arts on major few-shot visual recognition benchmarks, including miniImageNet and tieredImageNet.
On Evolving Attention Towards Domain Adaptation
Mar 25, 2021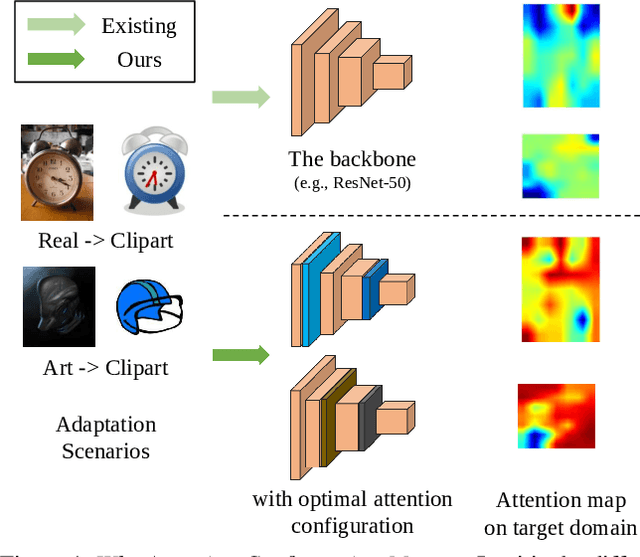
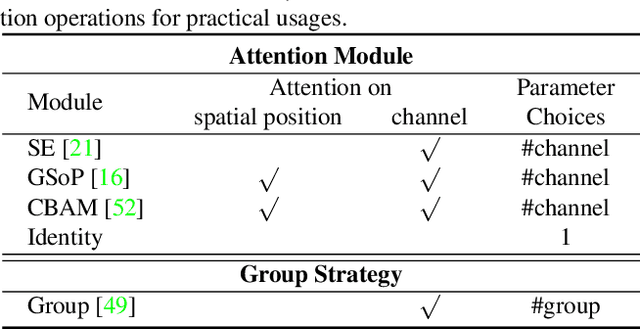
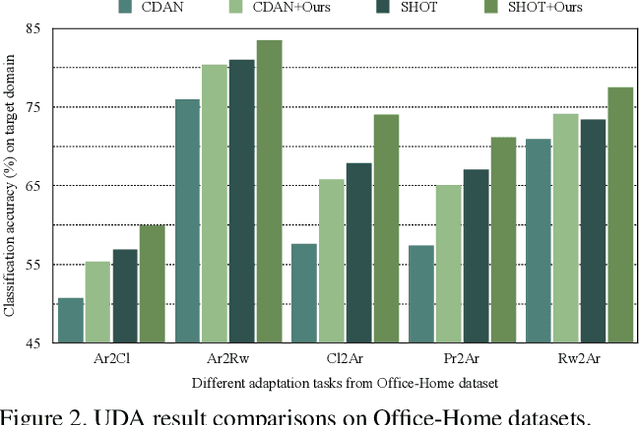
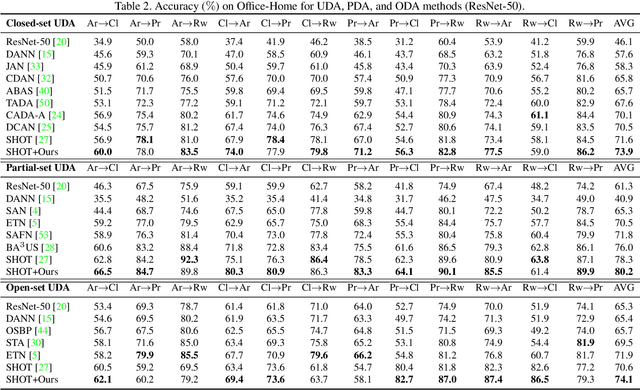
Towards better unsupervised domain adaptation (UDA). Recently, researchers propose various domain-conditioned attention modules and make promising progresses. However, considering that the configuration of attention, i.e., the type and the position of attention module, affects the performance significantly, it is more generalized to optimize the attention configuration automatically to be specialized for arbitrary UDA scenario. For the first time, this paper proposes EvoADA: a novel framework to evolve the attention configuration for a given UDA task without human intervention. In particular, we propose a novel search space containing diverse attention configurations. Then, to evaluate the attention configurations and make search procedure UDA-oriented (transferability + discrimination), we apply a simple and effective evaluation strategy: 1) training the network weights on two domains with off-the-shelf domain adaptation methods; 2) evolving the attention configurations under the guide of the discriminative ability on the target domain. Experiments on various kinds of cross-domain benchmarks, i.e., Office-31, Office-Home, CUB-Paintings, and Duke-Market-1510, reveal that the proposed EvoADA consistently boosts multiple state-of-the-art domain adaptation approaches, and the optimal attention configurations help them achieve better performance.
Learning Salient Boundary Feature for Anchor-free Temporal Action Localization
Mar 24, 2021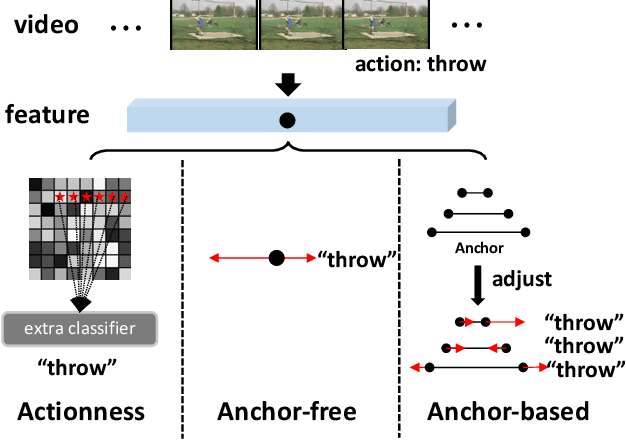
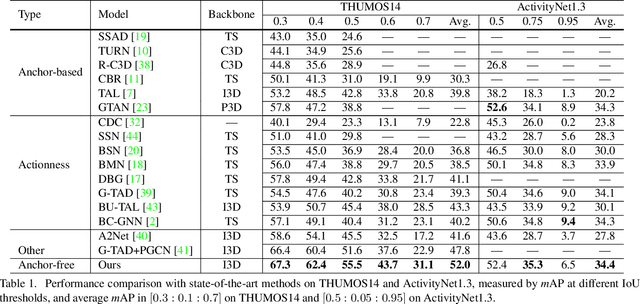


Temporal action localization is an important yet challenging task in video understanding. Typically, such a task aims at inferring both the action category and localization of the start and end frame for each action instance in a long, untrimmed video.While most current models achieve good results by using pre-defined anchors and numerous actionness, such methods could be bothered with both large number of outputs and heavy tuning of locations and sizes corresponding to different anchors. Instead, anchor-free methods is lighter, getting rid of redundant hyper-parameters, but gains few attention. In this paper, we propose the first purely anchor-free temporal localization method, which is both efficient and effective. Our model includes (i) an end-to-end trainable basic predictor, (ii) a saliency-based refinement module to gather more valuable boundary features for each proposal with a novel boundary pooling, and (iii) several consistency constraints to make sure our model can find the accurate boundary given arbitrary proposals. Extensive experiments show that our method beats all anchor-based and actionness-guided methods with a remarkable margin on THUMOS14, achieving state-of-the-art results, and comparable ones on ActivityNet v1.3. Code is available at https://github.com/TencentYoutuResearch/ActionDetection-AFSD.
Learning Comprehensive Motion Representation for Action Recognition
Mar 23, 2021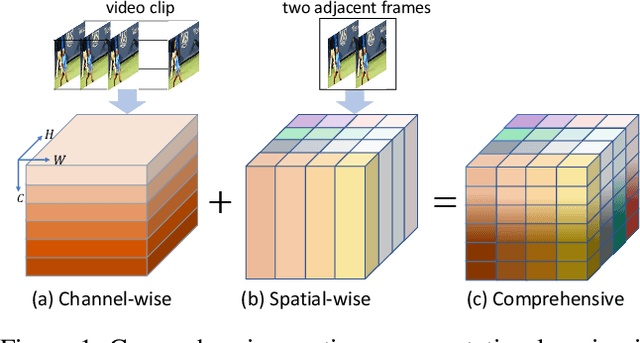
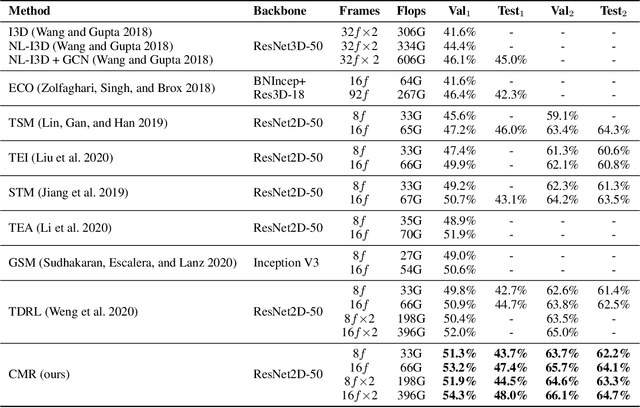
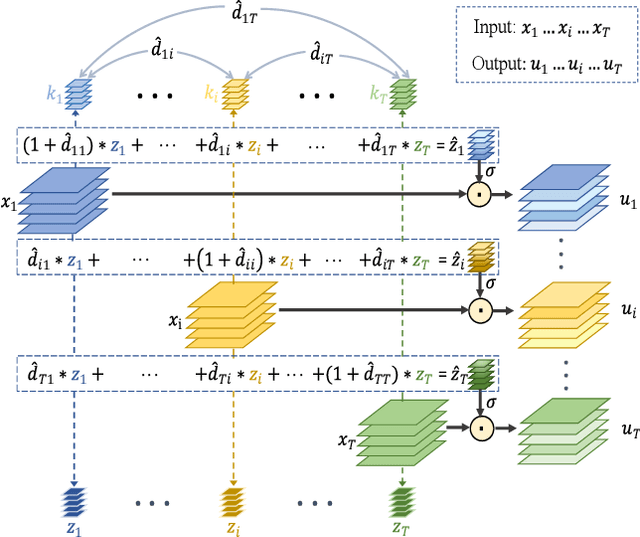
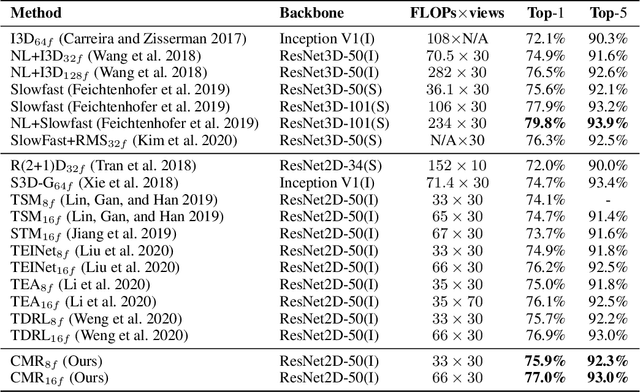
For action recognition learning, 2D CNN-based methods are efficient but may yield redundant features due to applying the same 2D convolution kernel to each frame. Recent efforts attempt to capture motion information by establishing inter-frame connections while still suffering the limited temporal receptive field or high latency. Moreover, the feature enhancement is often only performed by channel or space dimension in action recognition. To address these issues, we first devise a Channel-wise Motion Enhancement (CME) module to adaptively emphasize the channels related to dynamic information with a channel-wise gate vector. The channel gates generated by CME incorporate the information from all the other frames in the video. We further propose a Spatial-wise Motion Enhancement (SME) module to focus on the regions with the critical target in motion, according to the point-to-point similarity between adjacent feature maps. The intuition is that the change of background is typically slower than the motion area. Both CME and SME have clear physical meaning in capturing action clues. By integrating the two modules into the off-the-shelf 2D network, we finally obtain a Comprehensive Motion Representation (CMR) learning method for action recognition, which achieves competitive performance on Something-Something V1 & V2 and Kinetics-400. On the temporal reasoning datasets Something-Something V1 and V2, our method outperforms the current state-of-the-art by 2.3% and 1.9% when using 16 frames as input, respectively.