 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoAgent: Concurrency Control for Multi-Agent Systems
Jun 13, 2026Multi-agent LLM systems -- coding agents, devops agents, document agents -- now routinely run several agents in parallel against the same git tree, Kubernetes cluster, or document. As soon as two of them mutate shared state, they enter the regime classical concurrency control has studied for decades, but classical mechanisms fit LLM agents poorly. A single agent transaction spans minutes of inference, read sets are broad and opaque rather than statically inferable, and the live state agents act on admits neither fork nor buffer, so writes take effect the moment they execute. Locks block long inference intervals; OCC abort-and-retry discards minutes of work on every conflict. This paper builds concurrency control on a capability classical transactions lack: the LLM inside each agent can judge whether a conflicting write invalidates its plan, and can repair exactly the operations that depended on it. Control therefore turns advisory: the runtime informs, the agent repairs. Our protocol, MTPO (Monotonic Trajectory Pre-Order), fixes a serialization order at launch, serves each read the order-filtered value, and applies writes speculatively in place; a one-way notification asks an affected reader to re-judge and patch its plan, while the framework mechanically undoes and reorders misplaced writes through the saga-style inverse each tool registers in advance. At quiescence the run is serializable in the pre-decided order. We realize MTPO as CoAgent, toolcall middleware whose privileged ToolSmith grows footprint-declared, undoable tools online. On ten contended workloads, CoAgent stays within 5\% of serial correctness at a $1.4\times$ speedup and near-serial token cost, where 2PL and OCC surrender nearly all concurrency gains; on a bash-only target system, it grows a 25-tool library online and lifts the task pass rate from 45/71 to 63/71 at $0.80\times$ the time and $0.86\times$ the cost.
FairBatching: Fairness-Aware Batch Formation for LLM Inference
Oct 16, 2025Large language model (LLM) inference systems face a fundamental tension between minimizing Time-to-First-Token (TTFT) latency for new requests and maintaining a high, steady token generation rate (low Time-Per-Output-Token, or TPOT) for ongoing requests. Existing stall-free batching schedulers proposed by Sarathi, while effective at preventing decode stalls, introduce significant computational unfairness. They prioritize decode tasks excessively, simultaneously leading to underutilized decode slack and unnecessary prefill queuing delays, which collectively degrade the system's overall quality of service (QoS). This work identifies the root cause of this unfairness: the non-monotonic nature of Time-Between-Tokens (TBT) as a scheduling metric and the rigid decode-prioritizing policy that fails to adapt to dynamic workload bursts. We therefore propose FairBatching, a novel LLM inference scheduler that enforces fair resource allocation between prefill and decode tasks. It features an adaptive batch capacity determination mechanism, which dynamically adjusts the computational budget to improve the GPU utilization without triggering SLO violations. Its fair and dynamic batch formation algorithm breaks away from the decode-prioritizing paradigm, allowing computation resources to be reclaimed from bursting decode tasks to serve prefill surges, achieving global fairness. Furthermore, FairBatching provides a novel load estimation method, enabling more effective coordination with upper-level schedulers. Implemented and evaluated on realistic traces, FairBatching significantly reduces TTFT tail latency by up to 2.29x while robustly maintaining TPOT SLOs, achieving overall 20.0% improvement in single-node capacity and 54.3% improvement in cluster-level capacity.
An AI-native experimental laboratory for autonomous biomolecular engineering
Jul 03, 2025



Autonomous scientific research, capable of independently conducting complex experiments and serving non-specialists, represents a long-held aspiration. Achieving it requires a fundamental paradigm shift driven by artificial intelligence (AI). While autonomous experimental systems are emerging, they remain confined to areas featuring singular objectives and well-defined, simple experimental workflows, such as chemical synthesis and catalysis. We present an AI-native autonomous laboratory, targeting highly complex scientific experiments for applications like autonomous biomolecular engineering. This system autonomously manages instrumentation, formulates experiment-specific procedures and optimization heuristics, and concurrently serves multiple user requests. Founded on a co-design philosophy of models, experiments, and instruments, the platform supports the co-evolution of AI models and the automation system. This establishes an end-to-end, multi-user autonomous laboratory that handles complex, multi-objective experiments across diverse instrumentation. Our autonomous laboratory supports fundamental nucleic acid functions-including synthesis, transcription, amplification, and sequencing. It also enables applications in fields such as disease diagnostics, drug development, and information storage. Without human intervention, it autonomously optimizes experimental performance to match state-of-the-art results achieved by human scientists. In multi-user scenarios, the platform significantly improves instrument utilization and experimental efficiency. This platform paves the way for advanced biomaterials research to overcome dependencies on experts and resource barriers, establishing a blueprint for science-as-a-service at scale.
Learning Comprehensive Motion Representation for Action Recognition
Mar 23, 2021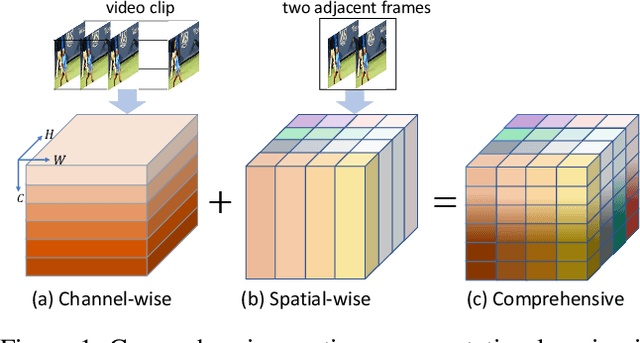
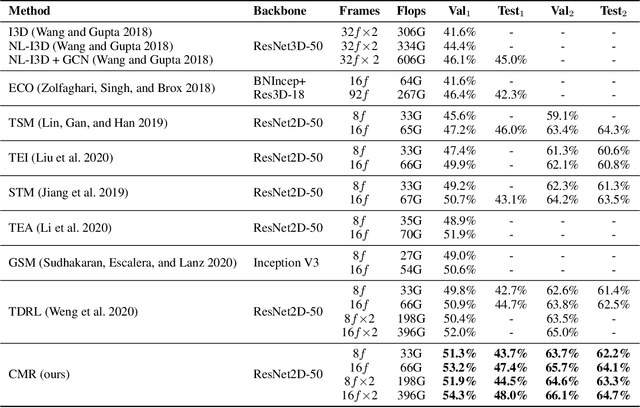
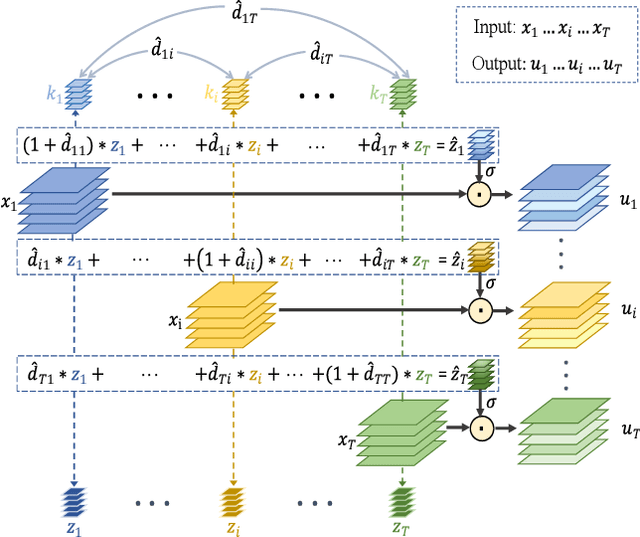
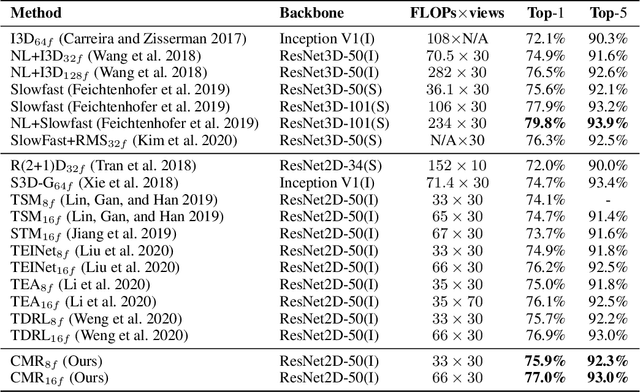
For action recognition learning, 2D CNN-based methods are efficient but may yield redundant features due to applying the same 2D convolution kernel to each frame. Recent efforts attempt to capture motion information by establishing inter-frame connections while still suffering the limited temporal receptive field or high latency. Moreover, the feature enhancement is often only performed by channel or space dimension in action recognition. To address these issues, we first devise a Channel-wise Motion Enhancement (CME) module to adaptively emphasize the channels related to dynamic information with a channel-wise gate vector. The channel gates generated by CME incorporate the information from all the other frames in the video. We further propose a Spatial-wise Motion Enhancement (SME) module to focus on the regions with the critical target in motion, according to the point-to-point similarity between adjacent feature maps. The intuition is that the change of background is typically slower than the motion area. Both CME and SME have clear physical meaning in capturing action clues. By integrating the two modules into the off-the-shelf 2D network, we finally obtain a Comprehensive Motion Representation (CMR) learning method for action recognition, which achieves competitive performance on Something-Something V1 & V2 and Kinetics-400. On the temporal reasoning datasets Something-Something V1 and V2, our method outperforms the current state-of-the-art by 2.3% and 1.9% when using 16 frames as input, respectively.