 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot synthesis of rare gastrointestinal lesions improves diagnostic accuracy and clinical training
Dec 30, 2025Rare gastrointestinal lesions are infrequently encountered in routine endoscopy, restricting the data available for developing reliable artificial intelligence (AI) models and training novice clinicians. Here we present EndoRare, a one-shot, retraining-free generative framework that synthesizes diverse, high-fidelity lesion exemplars from a single reference image. By leveraging language-guided concept disentanglement, EndoRare separates pathognomonic lesion features from non-diagnostic attributes, encoding the former into a learnable prototype embedding while varying the latter to ensure diversity. We validated the framework across four rare pathologies (calcifying fibrous tumor, juvenile polyposis syndrome, familial adenomatous polyposis, and Peutz-Jeghers syndrome). Synthetic images were judged clinically plausible by experts and, when used for data augmentation, significantly enhanced downstream AI classifiers, improving the true positive rate at low false-positive rates. Crucially, a blinded reader study demonstrated that novice endoscopists exposed to EndoRare-generated cases achieved a 0.400 increase in recall and a 0.267 increase in precision. These results establish a practical, data-efficient pathway to bridge the rare-disease gap in both computer-aided diagnostics and clinical education.
AMD-HookNet++: Evolution of AMD-HookNet with Hybrid CNN-Transformer Feature Enhancement for Glacier Calving Front Segmentation
Dec 16, 2025The dynamics of glaciers and ice shelf fronts significantly impact the mass balance of ice sheets and coastal sea levels. To effectively monitor glacier conditions, it is crucial to consistently estimate positional shifts of glacier calving fronts. AMD-HookNet firstly introduces a pure two-branch convolutional neural network (CNN) for glacier segmentation. Yet, the local nature and translational invariance of convolution operations, while beneficial for capturing low-level details, restricts the model ability to maintain long-range dependencies. In this study, we propose AMD-HookNet++, a novel advanced hybrid CNN-Transformer feature enhancement method for segmenting glaciers and delineating calving fronts in synthetic aperture radar images. Our hybrid structure consists of two branches: a Transformer-based context branch to capture long-range dependencies, which provides global contextual information in a larger view, and a CNN-based target branch to preserve local details. To strengthen the representation of the connected hybrid features, we devise an enhanced spatial-channel attention module to foster interactions between the hybrid CNN-Transformer branches through dynamically adjusting the token relationships from both spatial and channel perspectives. Additionally, we develop a pixel-to-pixel contrastive deep supervision to optimize our hybrid model by integrating pixelwise metric learning into glacier segmentation. Through extensive experiments and comprehensive quantitative and qualitative analyses on the challenging glacier segmentation benchmark dataset CaFFe, we show that AMD-HookNet++ sets a new state of the art with an IoU of 78.2 and a HD95 of 1,318 m, while maintaining a competitive MDE of 367 m. More importantly, our hybrid model produces smoother delineations of calving fronts, resolving the issue of jagged edges typically seen in pure Transformer-based approaches.
Multi-temporal Calving Front Segmentation
Dec 12, 2025The calving fronts of marine-terminating glaciers undergo constant changes. These changes significantly affect the glacier's mass and dynamics, demanding continuous monitoring. To address this need, deep learning models were developed that can automatically delineate the calving front in Synthetic Aperture Radar imagery. However, these models often struggle to correctly classify areas affected by seasonal conditions such as ice melange or snow-covered surfaces. To address this issue, we propose to process multiple frames from a satellite image time series of the same glacier in parallel and exchange temporal information between the corresponding feature maps to stabilize each prediction. We integrate our approach into the current state-of-the-art architecture Tyrion and accomplish a new state-of-the-art performance on the CaFFe benchmark dataset. In particular, we achieve a Mean Distance Error of 184.4 m and a mean Intersection over Union of 83.6.
GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection
Dec 10, 2025



Building AI systems for GUI automation task has attracted remarkable research efforts, where MLLMs are leveraged for processing user requirements and give operations. However, GUI automation includes a wide range of tasks, from document processing to online shopping, from CAD to video editing. Diversity between particular tasks requires MLLMs for GUI automation to have heterogeneous capabilities and master multidimensional expertise, raising problems on constructing such a model. To address such challenge, we propose GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection, a novel MLLM-based GUI automation agent framework designed for integrating knowledge and combining capabilities from heterogeneous models to build GUI automation agent systems with higher performance. Since different GUI-specific MLLMs are trained on different dataset and thus have different strengths, GAIR introduced a general-purpose MLLM for jointly processing the information from multiple GUI-specific models, further enhancing performance of the agent framework. The general-purpose MLLM also serves as decision maker, trying to execute a reasonable operation based on previously gathered information. When the general-purpose model thinks that there isn't sufficient information for a reasonable decision, GAIR would transit into group reflection status, where the general-purpose model would provide GUI-specific models with different instructions and hints based on their strengths and weaknesses, driving them to gather information with more significance and accuracy that can support deeper reasoning and decision. We evaluated the effectiveness and reliability of GAIR through extensive experiments on GUI benchmarks.
OmniEduBench: A Comprehensive Chinese Benchmark for Evaluating Large Language Models in Education
Oct 30, 2025With the rapid development of large language models (LLMs), various LLM-based works have been widely applied in educational fields. However, most existing LLMs and their benchmarks focus primarily on the knowledge dimension, largely neglecting the evaluation of cultivation capabilities that are essential for real-world educational scenarios. Additionally, current benchmarks are often limited to a single subject or question type, lacking sufficient diversity. This issue is particularly prominent within the Chinese context. To address this gap, we introduce OmniEduBench, a comprehensive Chinese educational benchmark. OmniEduBench consists of 24.602K high-quality question-answer pairs. The data is meticulously divided into two core dimensions: the knowledge dimension and the cultivation dimension, which contain 18.121K and 6.481K entries, respectively. Each dimension is further subdivided into 6 fine-grained categories, covering a total of 61 different subjects (41 in the knowledge and 20 in the cultivation). Furthermore, the dataset features a rich variety of question formats, including 11 common exam question types, providing a solid foundation for comprehensively evaluating LLMs' capabilities in education. Extensive experiments on 11 mainstream open-source and closed-source LLMs reveal a clear performance gap. In the knowledge dimension, only Gemini-2.5 Pro surpassed 60\% accuracy, while in the cultivation dimension, the best-performing model, QWQ, still trailed human intelligence by nearly 30\%. These results highlight the substantial room for improvement and underscore the challenges of applying LLMs in education.
Universal Legal Article Prediction via Tight Collaboration between Supervised Classification Model and LLM
Sep 26, 2025Legal Article Prediction (LAP) is a critical task in legal text classification, leveraging natural language processing (NLP) techniques to automatically predict relevant legal articles based on the fact descriptions of cases. As a foundational step in legal decision-making, LAP plays a pivotal role in determining subsequent judgments, such as charges and penalties. Despite its importance, existing methods face significant challenges in addressing the complexities of LAP. Supervised classification models (SCMs), such as CNN and BERT, struggle to fully capture intricate fact patterns due to their inherent limitations. Conversely, large language models (LLMs), while excelling in generative tasks, perform suboptimally in predictive scenarios due to the abstract and ID-based nature of legal articles. Furthermore, the diversity of legal systems across jurisdictions exacerbates the issue, as most approaches are tailored to specific countries and lack broader applicability. To address these limitations, we propose Uni-LAP, a universal framework for legal article prediction that integrates the strengths of SCMs and LLMs through tight collaboration. Specifically, in Uni-LAP, the SCM is enhanced with a novel Top-K loss function to generate accurate candidate articles, while the LLM employs syllogism-inspired reasoning to refine the final predictions. We evaluated Uni-LAP on datasets from multiple jurisdictions, and empirical results demonstrate that our approach consistently outperforms existing baselines, showcasing its effectiveness and generalizability.
SSGaussian: Semantic-Aware and Structure-Preserving 3D Style Transfer
Sep 04, 2025



Recent advancements in neural representations, such as Neural Radiance Fields and 3D Gaussian Splatting, have increased interest in applying style transfer to 3D scenes. While existing methods can transfer style patterns onto 3D-consistent neural representations, they struggle to effectively extract and transfer high-level style semantics from the reference style image. Additionally, the stylized results often lack structural clarity and separation, making it difficult to distinguish between different instances or objects within the 3D scene. To address these limitations, we propose a novel 3D style transfer pipeline that effectively integrates prior knowledge from pretrained 2D diffusion models. Our pipeline consists of two key stages: First, we leverage diffusion priors to generate stylized renderings of key viewpoints. Then, we transfer the stylized key views onto the 3D representation. This process incorporates two innovative designs. The first is cross-view style alignment, which inserts cross-view attention into the last upsampling block of the UNet, allowing feature interactions across multiple key views. This ensures that the diffusion model generates stylized key views that maintain both style fidelity and instance-level consistency. The second is instance-level style transfer, which effectively leverages instance-level consistency across stylized key views and transfers it onto the 3D representation. This results in a more structured, visually coherent, and artistically enriched stylization. Extensive qualitative and quantitative experiments demonstrate that our 3D style transfer pipeline significantly outperforms state-of-the-art methods across a wide range of scenes, from forward-facing to challenging 360-degree environments. Visit our project page https://jm-xu.github.io/SSGaussian for immersive visualization.
ClaimGen-CN: A Large-scale Chinese Dataset for Legal Claim Generation
Aug 24, 2025Legal claims refer to the plaintiff's demands in a case and are essential to guiding judicial reasoning and case resolution. While many works have focused on improving the efficiency of legal professionals, the research on helping non-professionals (e.g., plaintiffs) remains unexplored. This paper explores the problem of legal claim generation based on the given case's facts. First, we construct ClaimGen-CN, the first dataset for Chinese legal claim generation task, from various real-world legal disputes. Additionally, we design an evaluation metric tailored for assessing the generated claims, which encompasses two essential dimensions: factuality and clarity. Building on this, we conduct a comprehensive zero-shot evaluation of state-of-the-art general and legal-domain large language models. Our findings highlight the limitations of the current models in factual precision and expressive clarity, pointing to the need for more targeted development in this domain. To encourage further exploration of this important task, we will make the dataset publicly available.
FedEve: On Bridging the Client Drift and Period Drift for Cross-device Federated Learning
Aug 20, 2025Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model without exposing their private data. Data heterogeneity is a fundamental challenge in FL, which can result in poor convergence and performance degradation. Client drift has been recognized as one of the factors contributing to this issue resulting from the multiple local updates in FedAvg. However, in cross-device FL, a different form of drift arises due to the partial client participation, but it has not been studied well. This drift, we referred as period drift, occurs as participating clients at each communication round may exhibit distinct data distribution that deviates from that of all clients. It could be more harmful than client drift since the optimization objective shifts with every round. In this paper, we investigate the interaction between period drift and client drift, finding that period drift can have a particularly detrimental effect on cross-device FL as the degree of data heterogeneity increases. To tackle these issues, we propose a predict-observe framework and present an instantiated method, FedEve, where these two types of drift can compensate each other to mitigate their overall impact. We provide theoretical evidence that our approach can reduce the variance of model updates. Extensive experiments demonstrate that our method outperforms alternatives on non-iid data in cross-device settings.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025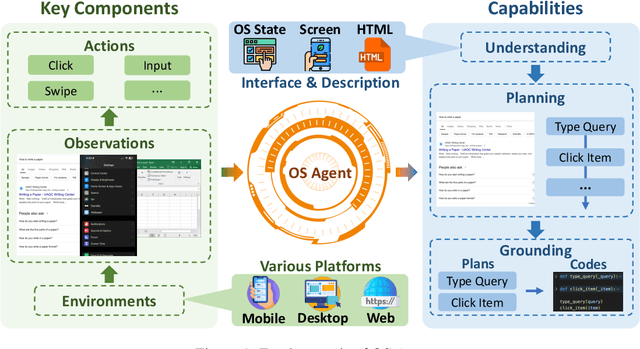
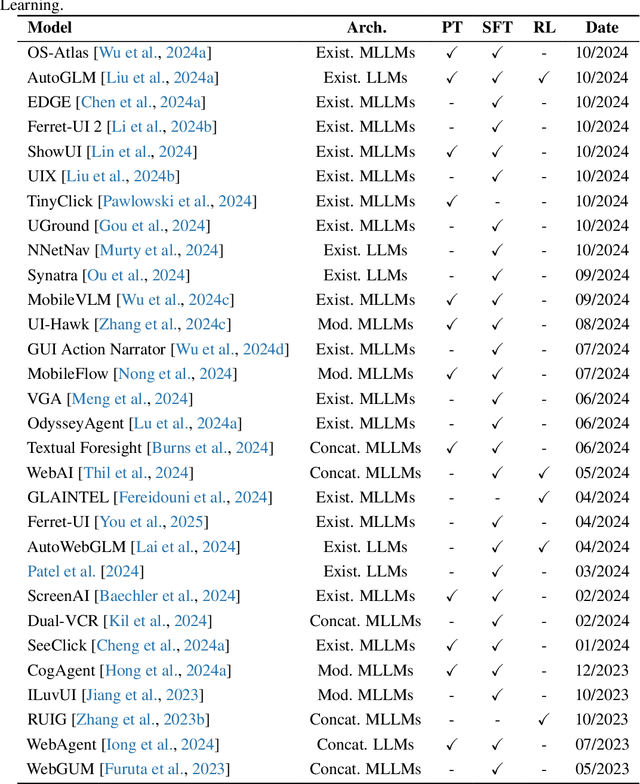
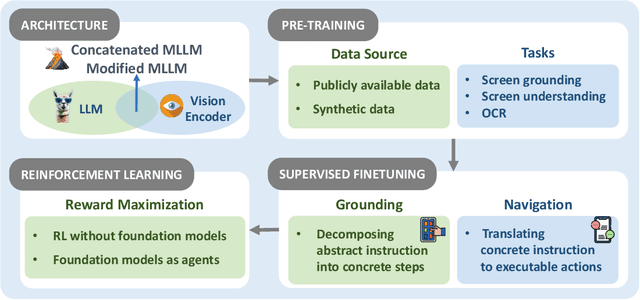
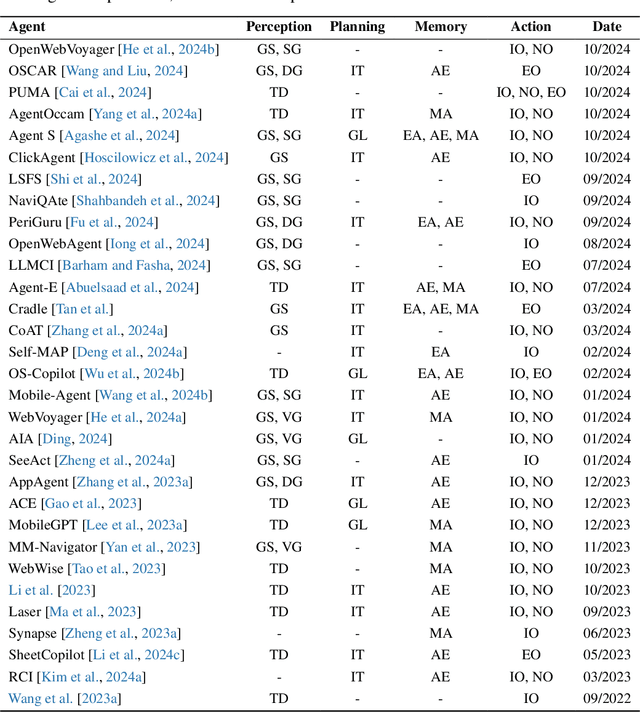
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.