 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025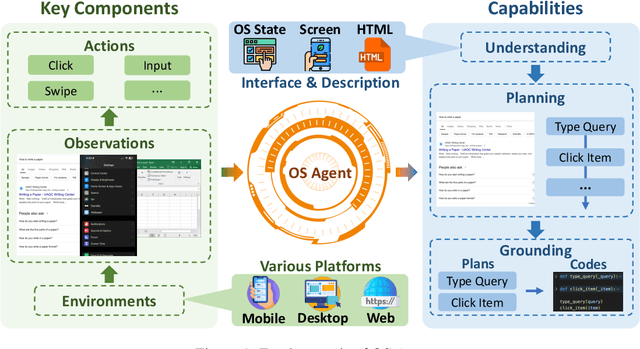
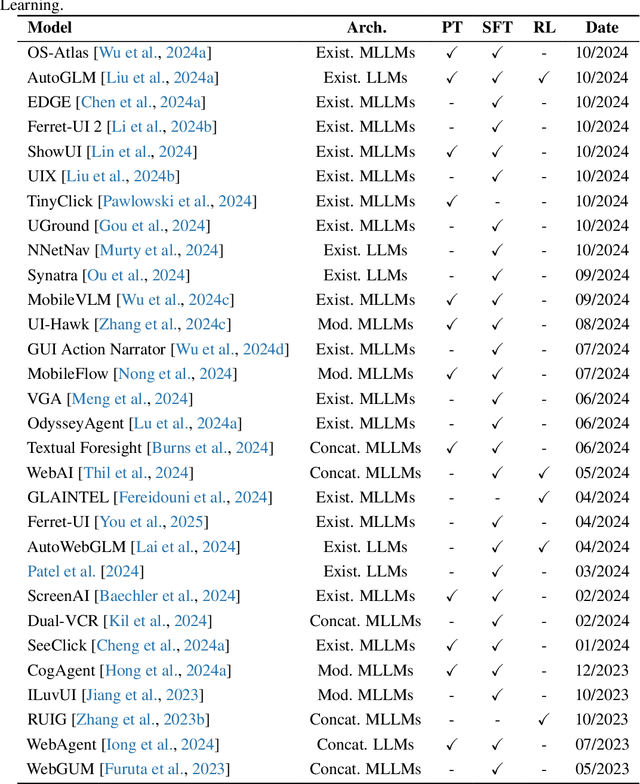
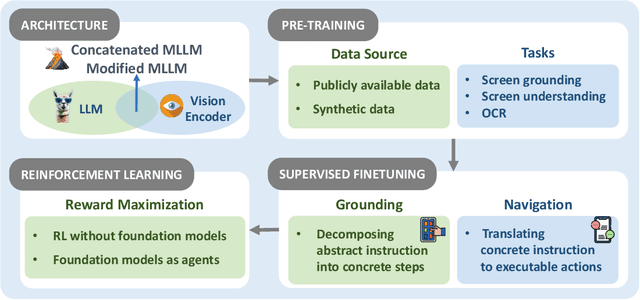
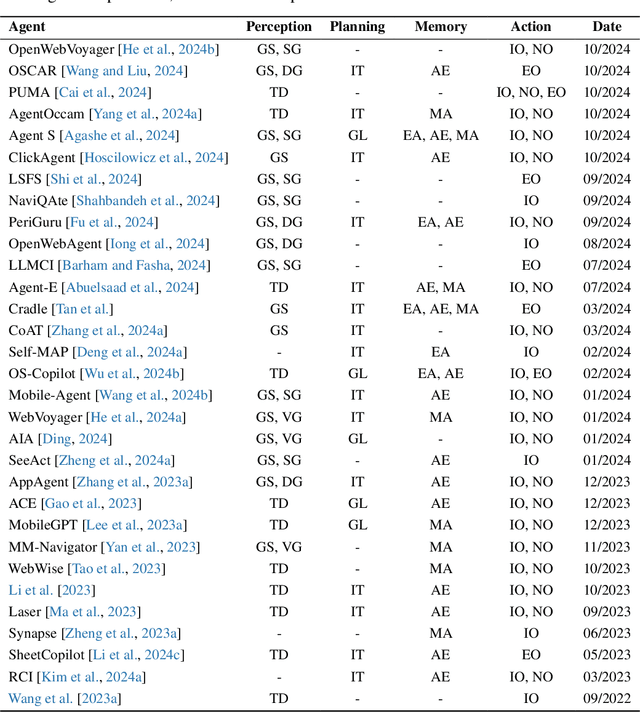
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
RealHiTBench: A Comprehensive Realistic Hierarchical Table Benchmark for Evaluating LLM-Based Table Analysis
Jun 16, 2025With the rapid advancement of Large Language Models (LLMs), there is an increasing need for challenging benchmarks to evaluate their capabilities in handling complex tabular data. However, existing benchmarks are either based on outdated data setups or focus solely on simple, flat table structures. In this paper, we introduce RealHiTBench, a comprehensive benchmark designed to evaluate the performance of both LLMs and Multimodal LLMs (MLLMs) across a variety of input formats for complex tabular data, including LaTeX, HTML, and PNG. RealHiTBench also includes a diverse collection of tables with intricate structures, spanning a wide range of task types. Our experimental results, using 25 state-of-the-art LLMs, demonstrate that RealHiTBench is indeed a challenging benchmark. Moreover, we also develop TreeThinker, a tree-based pipeline that organizes hierarchical headers into a tree structure for enhanced tabular reasoning, validating the importance of improving LLMs' perception of table hierarchies. We hope that our work will inspire further research on tabular data reasoning and the development of more robust models. The code and data are available at https://github.com/cspzyy/RealHiTBench.
D.Va: Validate Your Demonstration First Before You Use It
Feb 19, 2025In-context learning (ICL) has demonstrated significant potential in enhancing the capabilities of large language models (LLMs) during inference. It's well-established that ICL heavily relies on selecting effective demonstrations to generate outputs that better align with the expected results. As for demonstration selection, previous approaches have typically relied on intuitive metrics to evaluate the effectiveness of demonstrations, which often results in limited robustness and poor cross-model generalization capabilities. To tackle these challenges, we propose a novel method, \textbf{D}emonstration \textbf{VA}lidation (\textbf{D.Va}), which integrates a demonstration validation perspective into this field. By introducing the demonstration validation mechanism, our method effectively identifies demonstrations that are both effective and highly generalizable. \textbf{D.Va} surpasses all existing demonstration selection techniques across both natural language understanding (NLU) and natural language generation (NLG) tasks. Additionally, we demonstrate the robustness and generalizability of our approach across various language models with different retrieval models.
Automatic Dataset Construction (ADC): Sample Collection, Data Curation, and Beyond
Aug 21, 2024



Large-scale data collection is essential for developing personalized training data, mitigating the shortage of training data, and fine-tuning specialized models. However, creating high-quality datasets quickly and accurately remains a challenge due to annotation errors, the substantial time and costs associated with human labor. To address these issues, we propose Automatic Dataset Construction (ADC), an innovative methodology that automates dataset creation with negligible cost and high efficiency. Taking the image classification task as a starting point, ADC leverages LLMs for the detailed class design and code generation to collect relevant samples via search engines, significantly reducing the need for manual annotation and speeding up the data generation process. Despite these advantages, ADC also encounters real-world challenges such as label errors (label noise) and imbalanced data distributions (label bias). We provide open-source software that incorporates existing methods for label error detection, robust learning under noisy and biased data, ensuring a higher-quality training data and more robust model training procedure. Furthermore, we design three benchmark datasets focused on label noise detection, label noise learning, and class-imbalanced learning. These datasets are vital because there are few existing datasets specifically for label noise detection, despite its importance. Finally, we evaluate the performance of existing popular methods on these datasets, thereby facilitating further research in the field.
FlowBench: Revisiting and Benchmarking Workflow-Guided Planning for LLM-based Agents
Jun 21, 2024



LLM-based agents have emerged as promising tools, which are crafted to fulfill complex tasks by iterative planning and action. However, these agents are susceptible to undesired planning hallucinations when lacking specific knowledge for expertise-intensive tasks. To address this, preliminary attempts are made to enhance planning reliability by incorporating external workflow-related knowledge. Despite the promise, such infused knowledge is mostly disorganized and diverse in formats, lacking rigorous formalization and comprehensive comparisons. Motivated by this, we formalize different formats of workflow knowledge and present FlowBench, the first benchmark for workflow-guided planning. FlowBench covers 51 different scenarios from 6 domains, with knowledge presented in diverse formats. To assess different LLMs on FlowBench, we design a multi-tiered evaluation framework. We evaluate the efficacy of workflow knowledge across multiple formats, and the results indicate that current LLM agents need considerable improvements for satisfactory planning. We hope that our challenging benchmark can pave the way for future agent planning research.
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Jun 14, 2024



Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models
Nov 27, 2023



Collecting high-quality labeled data for model training is notoriously time-consuming and labor-intensive for various NLP tasks. While copious solutions, such as active learning for small language models (SLMs) and prevalent in-context learning in the era of large language models (LLMs), have been proposed and alleviate the labeling burden to some extent, their performances are still subject to human intervention. It is still underexplored how to reduce the annotation cost in the LLMs era. To bridge this, we revolutionize traditional active learning and propose an innovative collaborative learning framework FreeAL to interactively distill and filter the task-specific knowledge from LLMs. During collaborative training, an LLM serves as an active annotator inculcating its coarse-grained knowledge, while a downstream SLM is incurred as a student to filter out high-quality in-context samples to feedback LLM for the subsequent label refinery. Extensive experiments on eight benchmark datasets demonstrate that FreeAL largely enhances the zero-shot performances for both SLM and LLM without any human supervision. The code is available at https://github.com/Justherozen/FreeAL .
GaitFormer: Revisiting Intrinsic Periodicity for Gait Recognition
Jul 25, 2023



Gait recognition aims to distinguish different walking patterns by analyzing video-level human silhouettes, rather than relying on appearance information. Previous research on gait recognition has primarily focused on extracting local or global spatial-temporal representations, while overlooking the intrinsic periodic features of gait sequences, which, when fully utilized, can significantly enhance performance. In this work, we propose a plug-and-play strategy, called Temporal Periodic Alignment (TPA), which leverages the periodic nature and fine-grained temporal dependencies of gait patterns. The TPA strategy comprises two key components. The first component is Adaptive Fourier-transform Position Encoding (AFPE), which adaptively converts features and discrete-time signals into embeddings that are sensitive to periodic walking patterns. The second component is the Temporal Aggregation Module (TAM), which separates embeddings into trend and seasonal components, and extracts meaningful temporal correlations to identify primary components, while filtering out random noise. We present a simple and effective baseline method for gait recognition, based on the TPA strategy. Extensive experiments conducted on three popular public datasets (CASIA-B, OU-MVLP, and GREW) demonstrate that our proposed method achieves state-of-the-art performance on multiple benchmark tests.
Controllable Textual Inversion for Personalized Text-to-Image Generation
Apr 12, 2023



The recent large-scale generative modeling has attained unprecedented performance especially in producing high-fidelity images driven by text prompts. Text inversion (TI), alongside the text-to-image model backbones, is proposed as an effective technique in personalizing the generation when the prompts contain user-defined, unseen or long-tail concept tokens. Despite that, we find and show that the deployment of TI remains full of "dark-magics" -- to name a few, the harsh requirement of additional datasets, arduous human efforts in the loop and lack of robustness. In this work, we propose a much-enhanced version of TI, dubbed Controllable Textual Inversion (COTI), in resolving all the aforementioned problems and in turn delivering a robust, data-efficient and easy-to-use framework. The core to COTI is a theoretically-guided loss objective instantiated with a comprehensive and novel weighted scoring mechanism, encapsulated by an active-learning paradigm. The extensive results show that COTI significantly outperforms the prior TI-related approaches with a 26.05 decrease in the FID score and a 23.00% boost in the R-precision.
ProMix: Combating Label Noise via Maximizing Clean Sample Utility
Jul 22, 2022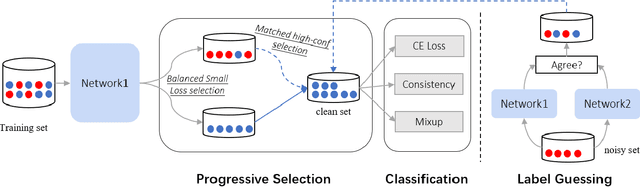
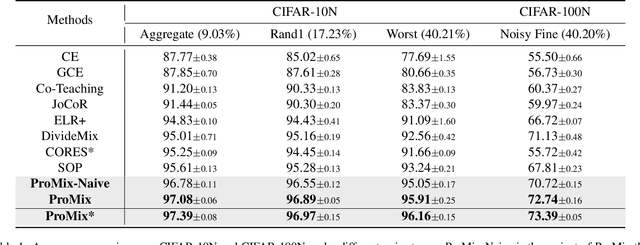
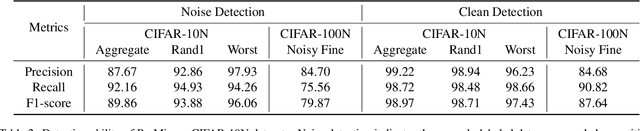
The ability to train deep neural networks under label noise is appealing, as imperfectly annotated data are relatively cheaper to obtain. State-of-the-art approaches are based on semi-supervised learning(SSL), which selects small loss examples as clean and then applies SSL techniques for boosted performance. However, the selection step mostly provides a medium-sized and decent-enough clean subset, which overlooks a rich set of clean samples. In this work, we propose a novel noisy label learning framework ProMix that attempts to maximize the utility of clean samples for boosted performance. Key to our method, we propose a matched high-confidence selection technique that selects those examples having high confidence and matched prediction with its given labels. Combining with the small-loss selection, our method is able to achieve a precision of 99.27 and a recall of 98.22 in detecting clean samples on the CIFAR-10N dataset. Based on such a large set of clean data, ProMix improves the best baseline method by +2.67% on CIFAR-10N and +1.61% on CIFAR-100N datasets. The code and data are available at https://github.com/Justherozen/ProMix