 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupGuard: A Framework for Modeling and Defending Collusive Attacks in Multi-Agent Systems
Mar 14, 2026While large language model-based agents demonstrate great potential in collaborative tasks, their interactivity also introduces security vulnerabilities. In this paper, we propose and model group collusive attacks, a highly destructive threat in which multiple agents coordinate via sociological strategies to mislead the system. To address this challenge, we introduce GroupGuard, a training-free defense framework that employs a multi-layered defense strategy, including continuous graph-based monitoring, active honeypot inducement, and structural pruning, to identify and isolate collusive agents. Experimental results across five datasets and four topologies demonstrate that group collusive attacks increase the attack success rate by up to 15\% compared to individual attacks. GroupGuard consistently achieves high detection accuracy (up to 88\%) and effectively restores collaborative performance, providing a robust solution for securing multi-agent systems.
Towards Faithful and Controllable Personalization via Critique-Post-Edit Reinforcement Learning
Oct 21, 2025Faithfully personalizing large language models (LLMs) to align with individual user preferences is a critical but challenging task. While supervised fine-tuning (SFT) quickly reaches a performance plateau, standard reinforcement learning from human feedback (RLHF) also struggles with the nuances of personalization. Scalar-based reward models are prone to reward hacking which leads to verbose and superficially personalized responses. To address these limitations, we propose Critique-Post-Edit, a robust reinforcement learning framework that enables more faithful and controllable personalization. Our framework integrates two key components: (1) a Personalized Generative Reward Model (GRM) that provides multi-dimensional scores and textual critiques to resist reward hacking, and (2) a Critique-Post-Edit mechanism where the policy model revises its own outputs based on these critiques for more targeted and efficient learning. Under a rigorous length-controlled evaluation, our method substantially outperforms standard PPO on personalization benchmarks. Personalized Qwen2.5-7B achieves an average 11\% win-rate improvement, and personalized Qwen2.5-14B model surpasses the performance of GPT-4.1. These results demonstrate a practical path to faithful, efficient, and controllable personalization.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025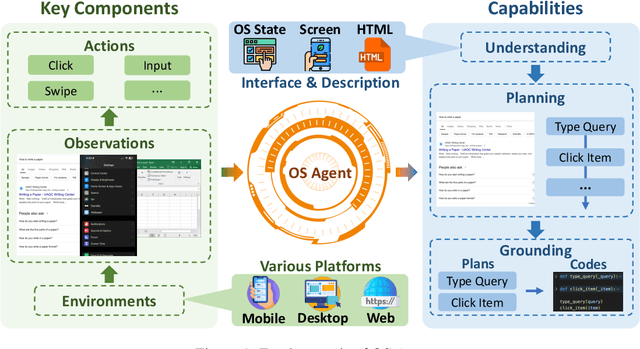
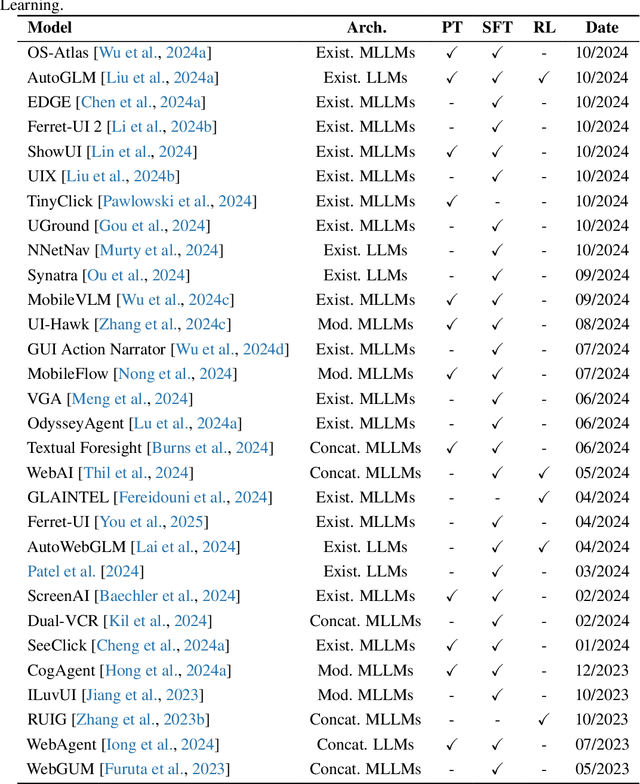
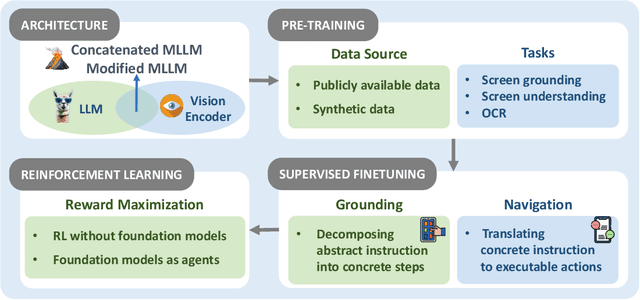
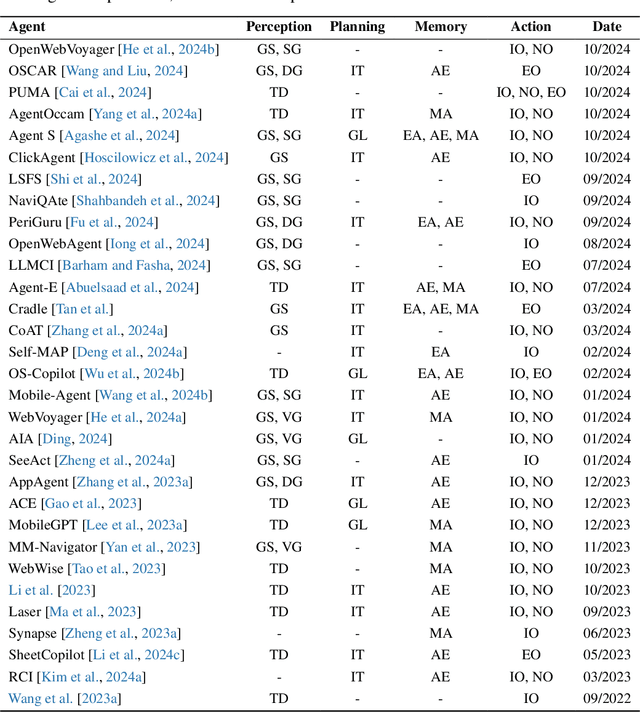
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
MiCoTA: Bridging the Learnability Gap with Intermediate CoT and Teacher Assistants
Jul 02, 2025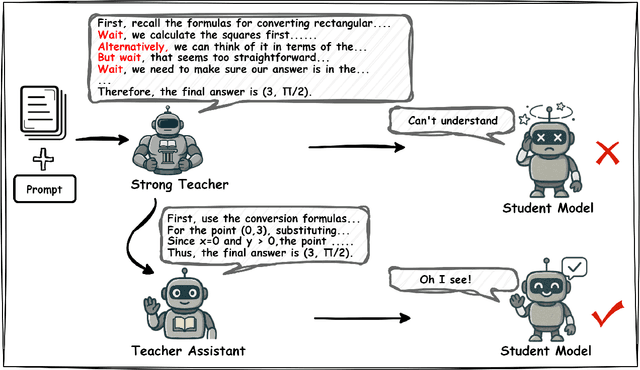
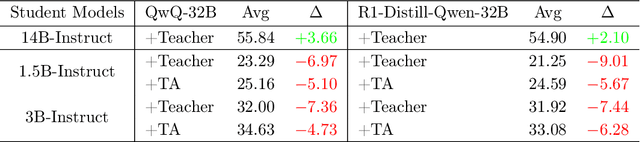
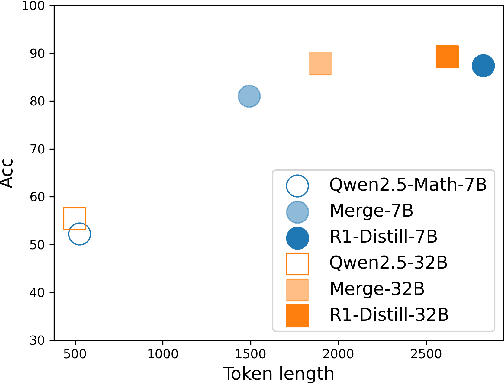
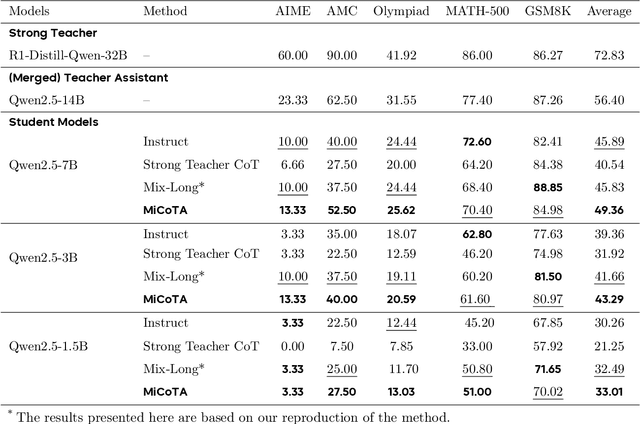
Large language models (LLMs) excel at reasoning tasks requiring long thought sequences for planning, reflection, and refinement. However, their substantial model size and high computational demands are impractical for widespread deployment. Yet, small language models (SLMs) often struggle to learn long-form CoT reasoning due to their limited capacity, a phenomenon we refer to as the "SLMs Learnability Gap". To address this, we introduce \textbf{Mi}d-\textbf{Co}T \textbf{T}eacher \textbf{A}ssistant Distillation (MiCoTAl), a framework for improving long CoT distillation for SLMs. MiCoTA employs intermediate-sized models as teacher assistants and utilizes intermediate-length CoT sequences to bridge both the capacity and reasoning length gaps. Our experiments on downstream tasks demonstrate that although SLMs distilled from large teachers can perform poorly, by applying MiCoTA, they achieve significant improvements in reasoning performance. Specifically, Qwen2.5-7B-Instruct and Qwen2.5-3B-Instruct achieve an improvement of 3.47 and 3.93 respectively on average score on AIME2024, AMC, Olympiad, MATH-500 and GSM8K benchmarks. To better understand the mechanism behind MiCoTA, we perform a quantitative experiment demonstrating that our method produces data more closely aligned with base SLM distributions. Our insights pave the way for future research into long-CoT data distillation for SLMs.
PersonaFeedback: A Large-scale Human-annotated Benchmark For Personalization
Jun 15, 2025With the rapid improvement in the general capabilities of LLMs, LLM personalization, i.e., how to build LLM systems that can generate personalized responses or services that are tailored to distinct user personas, has become an increasingly important research and engineering problem. However, unlike many new challenging benchmarks being released for evaluating the general/reasoning capabilities, the lack of high-quality benchmarks for evaluating LLM personalization greatly hinders progress in this field. To address this, we introduce PersonaFeedback, a new benchmark that directly evaluates LLMs' ability to provide personalized responses given pre-defined user personas and queries. Unlike existing benchmarks that require models to infer implicit user personas from historical interactions, PersonaFeedback decouples persona inference from personalization, focusing on evaluating the model's ability to generate responses tailored to explicit personas. PersonaFeedback consists of 8298 human-annotated test cases, which are categorized into easy, medium, and hard tiers based on the contextual complexity of the user personas and the difficulty in distinguishing subtle differences between two personalized responses. We conduct comprehensive evaluations across a wide range of models. The empirical results reveal that even state-of-the-art LLMs that can solve complex real-world reasoning tasks could fall short on the hard tier of PersonaFeedback where even human evaluators may find the distinctions challenging. Furthermore, we conduct an in-depth analysis of failure modes across various types of systems, demonstrating that the current retrieval-augmented framework should not be seen as a de facto solution for personalization tasks. All benchmark data, annotation protocols, and the evaluation pipeline will be publicly available to facilitate future research on LLM personalization.
MARS: Memory-Enhanced Agents with Reflective Self-improvement
Mar 25, 2025Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making, lack of long-term memory, and limited context windows in dynamic environments. To address these issues, this paper proposes an innovative framework Memory-Enhanced Agents with Reflective Self-improvement. The MARS framework comprises three agents: the User, the Assistant, and the Checker. By integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents capabilities in handling multi-tasking and long-span information.
AI PERSONA: Towards Life-long Personalization of LLMs
Dec 17, 2024In this work, we introduce the task of life-long personalization of large language models. While recent mainstream efforts in the LLM community mainly focus on scaling data and compute for improved capabilities of LLMs, we argue that it is also very important to enable LLM systems, or language agents, to continuously adapt to the diverse and ever-changing profiles of every distinct user and provide up-to-date personalized assistance. We provide a clear task formulation and introduce a simple, general, effective, and scalable framework for life-long personalization of LLM systems and language agents. To facilitate future research on LLM personalization, we also introduce methods to synthesize realistic benchmarks and robust evaluation metrics. We will release all codes and data for building and benchmarking life-long personalized LLM systems.
Self-evolving Agents with reflective and memory-augmented abilities
Sep 01, 2024Large language models (LLMs) have made significant advances in the field of natural language processing, but they still face challenges such as continuous decision-making. In this research, we propose a novel framework by integrating iterative feedback, reflective mechanisms, and a memory optimization mechanism based on the Ebbinghaus forgetting curve, it significantly enhances the agents' capabilities in handling multi-tasking and long-span information.
LanguaShrink: Reducing Token Overhead with Psycholinguistics
Sep 01, 2024As large language models (LLMs) improve their capabilities in handling complex tasks, the issues of computational cost and efficiency due to long prompts are becoming increasingly prominent. To accelerate model inference and reduce costs, we propose an innovative prompt compression framework called LanguaShrink. Inspired by the observation that LLM performance depends on the density and position of key information in the input prompts, LanguaShrink leverages psycholinguistic principles and the Ebbinghaus memory curve to achieve task-agnostic prompt compression. This effectively reduces prompt length while preserving essential information. We referred to the training method of OpenChat.The framework introduces part-of-speech priority compression and data distillation techniques, using smaller models to learn compression targets and employing a KL-regularized reinforcement learning strategy for training.\cite{wang2023openchat} Additionally, we adopt a chunk-based compression algorithm to achieve adjustable compression rates. We evaluate our method on multiple datasets, including LongBench, ZeroScrolls, Arxiv Articles, and a newly constructed novel test set. Experimental results show that LanguaShrink maintains semantic similarity while achieving up to 26 times compression. Compared to existing prompt compression methods, LanguaShrink improves end-to-end latency by 1.43 times.
CMAT: A Multi-Agent Collaboration Tuning Framework for Enhancing Small Language Models
Apr 04, 2024Open large language models (LLMs) have significantly advanced the field of natural language processing, showcasing impressive performance across various tasks.Despite the significant advancements in LLMs, their effective operation still relies heavily on human input to accurately guide the dialogue flow, with agent tuning being a crucial optimization technique that involves human adjustments to the model for better response to such guidance.Addressing this dependency, our work introduces the TinyAgent model, trained on a meticulously curated high-quality dataset. We also present the Collaborative Multi-Agent Tuning (CMAT) framework, an innovative system designed to augment language agent capabilities through adaptive weight updates based on environmental feedback. This framework fosters collaborative learning and real-time adaptation among multiple intelligent agents, enhancing their context-awareness and long-term memory. In this research, we propose a new communication agent framework that integrates multi-agent systems with environmental feedback mechanisms, offering a scalable method to explore cooperative behaviors. Notably, our TinyAgent-7B model exhibits performance on par with GPT-3.5, despite having fewer parameters, signifying a substantial improvement in the efficiency and effectiveness of LLMs.