 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025
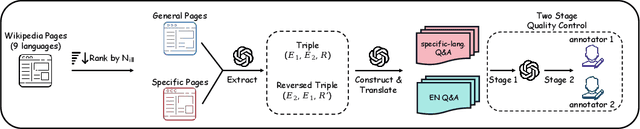


We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .
Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models
May 22, 2025

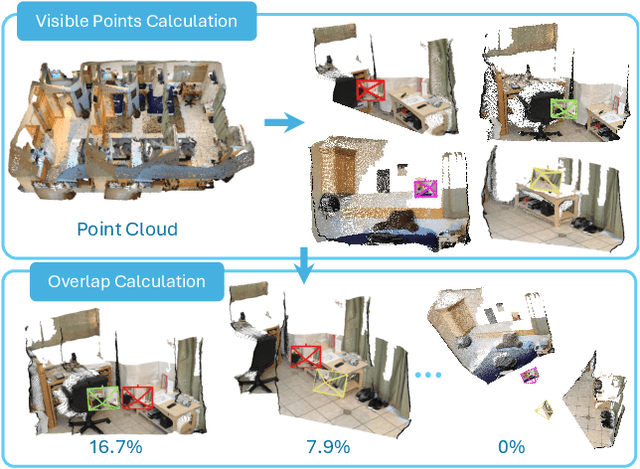
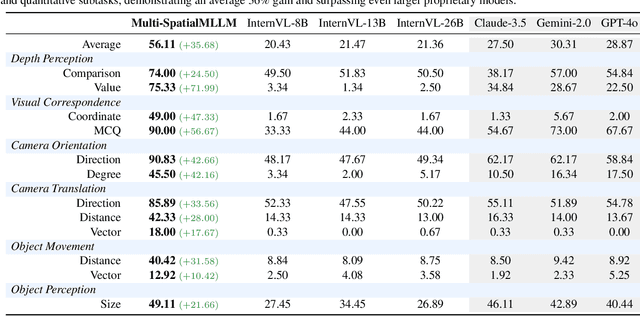
Multi-modal large language models (MLLMs) have rapidly advanced in visual tasks, yet their spatial understanding remains limited to single images, leaving them ill-suited for robotics and other real-world applications that require multi-frame reasoning. In this paper, we propose a framework to equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception. Central to our approach is the MultiSPA dataset, a novel, large-scale collection of more than 27 million samples spanning diverse 3D and 4D scenes. Alongside MultiSPA, we introduce a comprehensive benchmark that tests a wide spectrum of spatial tasks under uniform metrics. Our resulting model, Multi-SpatialMLLM, achieves significant gains over baselines and proprietary systems, demonstrating scalable, generalizable multi-frame reasoning. We further observe multi-task benefits and early indications of emergent capabilities in challenging scenarios, and showcase how our model can serve as a multi-frame reward annotator for robotics.
Visual Agentic Reinforcement Fine-Tuning
May 20, 2025A key trend in Large Reasoning Models (e.g., OpenAI's o3) is the native agentic ability to use external tools such as web browsers for searching and writing/executing code for image manipulation to think with images. In the open-source research community, while significant progress has been made in language-only agentic abilities such as function calling and tool integration, the development of multi-modal agentic capabilities that involve truly thinking with images, and their corresponding benchmarks, are still less explored. This work highlights the effectiveness of Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) for enabling flexible and adaptive reasoning abilities for Large Vision-Language Models (LVLMs). With Visual-ARFT, open-source LVLMs gain the ability to browse websites for real-time information updates and write code to manipulate and analyze input images through cropping, rotation, and other image processing techniques. We also present a Multi-modal Agentic Tool Bench (MAT) with two settings (MAT-Search and MAT-Coding) designed to evaluate LVLMs' agentic search and coding abilities. Our experimental results demonstrate that Visual-ARFT outperforms its baseline by +18.6% F1 / +13.0% EM on MAT-Coding and +10.3% F1 / +8.7% EM on MAT-Search, ultimately surpassing GPT-4o. Visual-ARFT also achieves +29.3 F1% / +25.9% EM gains on existing multi-hop QA benchmarks such as 2Wiki and HotpotQA, demonstrating strong generalization capabilities. Our findings suggest that Visual-ARFT offers a promising path toward building robust and generalizable multimodal agents.
MxMoE: Mixed-precision Quantization for MoE with Accuracy and Performance Co-Design
May 09, 2025



Mixture-of-Experts (MoE) models face deployment challenges due to their large parameter counts and computational demands. We explore quantization for MoE models and highlight two key insights: 1) linear blocks exhibit varying quantization sensitivity, and 2) divergent expert activation frequencies create heterogeneous computational characteristics. Based on these observations, we introduce MxMoE, a mixed-precision optimization framework for MoE models that considers both algorithmic and system perspectives. MxMoE navigates the design space defined by parameter sensitivity, expert activation dynamics, and hardware resources to derive efficient mixed-precision configurations. Additionally, MxMoE automatically generates optimized mixed-precision GroupGEMM kernels, enabling parallel execution of GEMMs with different precisions. Evaluations show that MxMoE outperforms existing methods, achieving 2.4 lower Wikitext-2 perplexity than GPTQ at 2.25-bit and delivering up to 3.4x speedup over full precision, as well as up to 29.4% speedup over uniform quantization at equivalent accuracy with 5-bit weight-activation quantization. Our code is available at https://github.com/cat538/MxMoE.
Novel Demonstration Generation with Gaussian Splatting Enables Robust One-Shot Manipulation
Apr 17, 2025Visuomotor policies learned from teleoperated demonstrations face challenges such as lengthy data collection, high costs, and limited data diversity. Existing approaches address these issues by augmenting image observations in RGB space or employing Real-to-Sim-to-Real pipelines based on physical simulators. However, the former is constrained to 2D data augmentation, while the latter suffers from imprecise physical simulation caused by inaccurate geometric reconstruction. This paper introduces RoboSplat, a novel method that generates diverse, visually realistic demonstrations by directly manipulating 3D Gaussians. Specifically, we reconstruct the scene through 3D Gaussian Splatting (3DGS), directly edit the reconstructed scene, and augment data across six types of generalization with five techniques: 3D Gaussian replacement for varying object types, scene appearance, and robot embodiments; equivariant transformations for different object poses; visual attribute editing for various lighting conditions; novel view synthesis for new camera perspectives; and 3D content generation for diverse object types. Comprehensive real-world experiments demonstrate that RoboSplat significantly enhances the generalization of visuomotor policies under diverse disturbances. Notably, while policies trained on hundreds of real-world demonstrations with additional 2D data augmentation achieve an average success rate of 57.2%, RoboSplat attains 87.8% in one-shot settings across six types of generalization in the real world.
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 15, 2025We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
GenDoP: Auto-regressive Camera Trajectory Generation as a Director of Photography
Apr 10, 2025Camera trajectory design plays a crucial role in video production, serving as a fundamental tool for conveying directorial intent and enhancing visual storytelling. In cinematography, Directors of Photography meticulously craft camera movements to achieve expressive and intentional framing. However, existing methods for camera trajectory generation remain limited: Traditional approaches rely on geometric optimization or handcrafted procedural systems, while recent learning-based methods often inherit structural biases or lack textual alignment, constraining creative synthesis. In this work, we introduce an auto-regressive model inspired by the expertise of Directors of Photography to generate artistic and expressive camera trajectories. We first introduce DataDoP, a large-scale multi-modal dataset containing 29K real-world shots with free-moving camera trajectories, depth maps, and detailed captions in specific movements, interaction with the scene, and directorial intent. Thanks to the comprehensive and diverse database, we further train an auto-regressive, decoder-only Transformer for high-quality, context-aware camera movement generation based on text guidance and RGBD inputs, named GenDoP. Extensive experiments demonstrate that compared to existing methods, GenDoP offers better controllability, finer-grained trajectory adjustments, and higher motion stability. We believe our approach establishes a new standard for learning-based cinematography, paving the way for future advancements in camera control and filmmaking. Our project website: https://kszpxxzmc.github.io/GenDoP/.
MM-IFEngine: Towards Multimodal Instruction Following
Apr 10, 2025The Instruction Following (IF) ability measures how well Multi-modal Large Language Models (MLLMs) understand exactly what users are telling them and whether they are doing it right. Existing multimodal instruction following training data is scarce, the benchmarks are simple with atomic instructions, and the evaluation strategies are imprecise for tasks demanding exact output constraints. To address this, we present MM-IFEngine, an effective pipeline to generate high-quality image-instruction pairs. Our MM-IFEngine pipeline yields large-scale, diverse, and high-quality training data MM-IFInstruct-23k, which is suitable for Supervised Fine-Tuning (SFT) and extended as MM-IFDPO-23k for Direct Preference Optimization (DPO). We further introduce MM-IFEval, a challenging and diverse multi-modal instruction-following benchmark that includes (1) both compose-level constraints for output responses and perception-level constraints tied to the input images, and (2) a comprehensive evaluation pipeline incorporating both rule-based assessment and judge model. We conduct SFT and DPO experiments and demonstrate that fine-tuning MLLMs on MM-IFInstruct-23k and MM-IFDPO-23k achieves notable gains on various IF benchmarks, such as MM-IFEval (+10.2$\%$), MIA (+7.6$\%$), and IFEval (+12.3$\%$). The full data and evaluation code will be released on https://github.com/SYuan03/MM-IFEngine.
HiFlow: Training-free High-Resolution Image Generation with Flow-Aligned Guidance
Apr 08, 2025Text-to-image (T2I) diffusion/flow models have drawn considerable attention recently due to their remarkable ability to deliver flexible visual creations. Still, high-resolution image synthesis presents formidable challenges due to the scarcity and complexity of high-resolution content. To this end, we present HiFlow, a training-free and model-agnostic framework to unlock the resolution potential of pre-trained flow models. Specifically, HiFlow establishes a virtual reference flow within the high-resolution space that effectively captures the characteristics of low-resolution flow information, offering guidance for high-resolution generation through three key aspects: initialization alignment for low-frequency consistency, direction alignment for structure preservation, and acceleration alignment for detail fidelity. By leveraging this flow-aligned guidance, HiFlow substantially elevates the quality of high-resolution image synthesis of T2I models and demonstrates versatility across their personalized variants. Extensive experiments validate HiFlow's superiority in achieving superior high-resolution image quality over current state-of-the-art methods.
Multi-identity Human Image Animation with Structural Video Diffusion
Apr 05, 2025Generating human videos from a single image while ensuring high visual quality and precise control is a challenging task, especially in complex scenarios involving multiple individuals and interactions with objects. Existing methods, while effective for single-human cases, often fail to handle the intricacies of multi-identity interactions because they struggle to associate the correct pairs of human appearance and pose condition and model the distribution of 3D-aware dynamics. To address these limitations, we present Structural Video Diffusion, a novel framework designed for generating realistic multi-human videos. Our approach introduces two core innovations: identity-specific embeddings to maintain consistent appearances across individuals and a structural learning mechanism that incorporates depth and surface-normal cues to model human-object interactions. Additionally, we expand existing human video dataset with 25K new videos featuring diverse multi-human and object interaction scenarios, providing a robust foundation for training. Experimental results demonstrate that Structural Video Diffusion achieves superior performance in generating lifelike, coherent videos for multiple subjects with dynamic and rich interactions, advancing the state of human-centric video generation.