 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs for Grammar Adaptation: A Study on Metamodel-Grammar Co-Evolution
May 20, 2026In model-driven engineering, metamodel evolution leads to the need to adapt corresponding grammars to maintain consistency, which typically requires tedious manual work. Existing rule-based methods can achieve partial automation but have limitations when handling complex grammar scenarios. This paper proposes a Large Language Model-based approach that automatically applies adaptations to new grammars after evolution by learning grammar adaptations from previous versions. We evaluated this approach on six real-world Xtext domain-specific languages, using four DSLs as a training set to develop prompting strategies, two DSLs as a test set for validation, and conducting a longitudinal case study on QVTo. The evaluation used three Large Language Models (Claude Sonnet 4.5, ChatGPT 5.1, Gemini 3) and measured grammar adaptation quality from three dimensions: grammar rule-level adaptation consistency, output similarity, and metamodel conformance. Results show that on the test set, all three LLMs achieved 100% adaptation consistency and output similarity, while the rule-based approach achieved only 84.21% on DOT and 62.50% on Xcore. In the QVTo longitudinal study, the LLM-based approach successfully reused learned adaptations across all three evolution steps without manual grammar editing, while the rule-based approach required manual adjustments in two of three transitions. However, on large-scale grammars (EAST-ADL, 297 rules), LLMs' adaptation consistency was far below 90%. This study demonstrates the advantages of LLM-based approaches in handling complex grammar scenarios, while revealing their limitations in large-scale grammar adaptation.
Molecular Identifier Visual Prompt and Verifiable Reinforcement Learning for Chemical Reaction Diagram Parsing
Mar 17, 2026Reaction diagram parsing (RxnDP) is critical for extracting chemical synthesis information from literature. Although recent Vision-Language Models (VLMs) have emerged as a promising paradigm to automate this complex visual reasoning task, their application is fundamentally bottlenecked by the inability to align visual chemical entities with pre-trained knowledge, alongside the inherent discrepancy between token-level training and reaction-level evaluation. To address these dual challenges, this work enhances VLM-based RxnDP from two complementary perspectives: prompting representation and learning paradigms. First, we propose Identifier as Visual Prompting (IdtVP), which leverages naturally occurring molecule identifiers (e.g., bold numerals like 1a) to activate the chemical knowledge acquired during VLM pre-training. IdtVP enables powerful zero-shot and out-of-distribution capabilities, outperforming existing prompting strategies. Second, to further optimize performance within fine-tuning paradigms, we introduce Re3-DAPO, a reinforcement learning algorithm that leverages verifiable rewards to directly optimize reaction-level metrics, thereby achieving consistent gains over standard supervised fine-tuning. Additionally, we release the ScannedRxn benchmark, comprising scanned historical reaction diagrams with real-world artifacts, to rigorously assess model robustness and out-of-distribution ability. Our contributions advance the accuracy and generalization of VLM-based reaction diagram parsing. We will release data, models, and code on GitHub.
RoboClaw: An Agentic Framework for Scalable Long-Horizon Robotic Tasks
Mar 12, 2026Vision-Language-Action (VLA) systems have shown strong potential for language-driven robotic manipulation. However, scaling them to long-horizon tasks remains challenging. Existing pipelines typically separate data collection, policy learning, and deployment, resulting in heavy reliance on manual environment resets and brittle multi-policy execution. We present RoboClaw, an agentic robotics framework that unifies data collection, policy learning, and task execution under a single VLM-driven controller. At the policy level, RoboClaw introduces Entangled Action Pairs (EAP), which couple forward manipulation behaviors with inverse recovery actions to form self-resetting loops for autonomous data collection. This mechanism enables continuous on-policy data acquisition and iterative policy refinement with minimal human intervention. During deployment, the same agent performs high-level reasoning and dynamically orchestrates learned policy primitives to accomplish long-horizon tasks. By maintaining consistent contextual semantics across collection and execution, RoboClaw reduces mismatch between the two phases and improves multi-policy robustness. Experiments in real-world manipulation tasks demonstrate improved stability and scalability compared to conventional open-loop pipelines, while significantly reducing human effort throughout the robot lifecycle, achieving a 25% improvement in success rate over baseline methods on long-horizon tasks and reducing human time investment by 53.7%.
Experiential Reinforcement Learning
Feb 15, 2026Reinforcement learning has become the central approach for language models (LMs) to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations. We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience-reflection-consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy. This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks. These results suggest that integrating explicit self-reflection into policy training provides a practical mechanism for transforming feedback into durable behavioral improvement.
Leveraging LLMs to support co-evolution between definitions and instances of textual DSLs: A Systematic Evaluation
Feb 12, 2026Software languages evolve over time for reasons such as feature additions. When grammars evolve, textual instances that originally conformed to them may become outdated. While model-driven engineering provides many techniques for co-evolving models with metamodel changes, these approaches are not designed for textual DSLs and may lose human-relevant information such as layout and comments. This study systematically evaluates the potential of large language models (LLMs) for co-evolving grammars and instances of textual DSLs. Using Claude Sonnet 4.5 and GPT-5.2 across ten case languages with ten runs each, we assess both correctness and preservation of human-oriented information. Results show strong performance on small-scale cases ($\geq$94% precision and recall for instances requiring fewer than 20 modified lines), but performance degraded with scale: Claude maintains 85% recall at 40 lines, while GPT fails on the largest instances. Response time increases substantially with instance size, and grammar evolution complexity and deletion granularity affect performance more than change type. These findings clarify when LLM-based co-evolution is effective and where current limitations remain.
One Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
Feb 03, 2026This paper introduces OMAR: One Model, All Roles, a reinforcement learning framework that enables AI to develop social intelligence through multi-turn, multi-agent conversational self-play. Unlike traditional paradigms that rely on static, single-turn optimizations, OMAR allows a single model to role-play all participants in a conversation simultaneously, learning to achieve long-term goals and complex social norms directly from dynamic social interaction. To ensure training stability across long dialogues, we implement a hierarchical advantage estimation that calculates turn-level and token-level advantages. Evaluations in the SOTOPIA social environment and Werewolf strategy games show that our trained models develop fine-grained, emergent social intelligence, such as empathy, persuasion, and compromise seeking, demonstrating the effectiveness of learning collaboration even under competitive scenarios. While we identify practical challenges like reward hacking, our results show that rich social intelligence can emerge without human supervision. We hope this work incentivizes further research on AI social intelligence in group conversations.
AdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Aug 11, 2025Recent advances in large language models (LLMs) have sparked growing interest in agentic workflows, which are structured sequences of LLM invocations intended to solve complex tasks. However, existing approaches often rely on static templates or manually designed workflows, which limit adaptability to diverse tasks and hinder scalability. We propose AdaptFlow, a natural language-based meta-learning framework inspired by model-agnostic meta-learning (MAML). AdaptFlow learns a generalizable workflow initialization that enables rapid subtask-level adaptation. It employs a bi-level optimization scheme: the inner loop refines the workflow for a specific subtask using LLM-generated feedback, while the outer loop updates the shared initialization to perform well across tasks. This setup allows AdaptFlow to generalize effectively to unseen tasks by adapting the initialized workflow through language-guided modifications. Evaluated across question answering, code generation, and mathematical reasoning benchmarks, AdaptFlow consistently outperforms both manually crafted and automatically searched baselines, achieving state-of-the-art results with strong generalization across tasks and models. The source code and data are available at https://github.com/microsoft/DKI_LLM/tree/AdaptFlow/AdaptFlow.
AD^2-Bench: A Hierarchical CoT Benchmark for MLLM in Autonomous Driving under Adverse Conditions
Jun 11, 2025



Chain-of-Thought (CoT) reasoning has emerged as a powerful approach to enhance the structured, multi-step decision-making capabilities of Multi-Modal Large Models (MLLMs), is particularly crucial for autonomous driving with adverse weather conditions and complex traffic environments. However, existing benchmarks have largely overlooked the need for rigorous evaluation of CoT processes in these specific and challenging scenarios. To address this critical gap, we introduce AD^2-Bench, the first Chain-of-Thought benchmark specifically designed for autonomous driving with adverse weather and complex scenes. AD^2-Bench is meticulously constructed to fulfill three key criteria: comprehensive data coverage across diverse adverse environments, fine-grained annotations that support multi-step reasoning, and a dedicated evaluation framework tailored for assessing CoT performance. The core contribution of AD^2-Bench is its extensive collection of over 5.4k high-quality, manually annotated CoT instances. Each intermediate reasoning step in these annotations is treated as an atomic unit with explicit ground truth, enabling unprecedented fine-grained analysis of MLLMs' inferential processes under text-level, point-level, and region-level visual prompts. Our comprehensive evaluation of state-of-the-art MLLMs on AD^2-Bench reveals accuracy below 60%, highlighting the benchmark's difficulty and the need to advance robust, interpretable end-to-end autonomous driving systems. AD^2-Bench thus provides a standardized evaluation platform, driving research forward by improving MLLMs' reasoning in autonomous driving, making it an invaluable resource.
EL4NER: Ensemble Learning for Named Entity Recognition via Multiple Small-Parameter Large Language Models
May 29, 2025In-Context Learning (ICL) technique based on Large Language Models (LLMs) has gained prominence in Named Entity Recognition (NER) tasks for its lower computing resource consumption, less manual labeling overhead, and stronger generalizability. Nevertheless, most ICL-based NER methods depend on large-parameter LLMs: the open-source models demand substantial computational resources for deployment and inference, while the closed-source ones incur high API costs, raise data-privacy concerns, and hinder community collaboration. To address this question, we propose an Ensemble Learning Method for Named Entity Recognition (EL4NER), which aims at aggregating the ICL outputs of multiple open-source, small-parameter LLMs to enhance overall performance in NER tasks at less deployment and inference cost. Specifically, our method comprises three key components. First, we design a task decomposition-based pipeline that facilitates deep, multi-stage ensemble learning. Second, we introduce a novel span-level sentence similarity algorithm to establish an ICL demonstration retrieval mechanism better suited for NER tasks. Third, we incorporate a self-validation mechanism to mitigate the noise introduced during the ensemble process. We evaluated EL4NER on multiple widely adopted NER datasets from diverse domains. Our experimental results indicate that EL4NER surpasses most closed-source, large-parameter LLM-based methods at a lower parameter cost and even attains state-of-the-art (SOTA) performance among ICL-based methods on certain datasets. These results show the parameter efficiency of EL4NER and underscore the feasibility of employing open-source, small-parameter LLMs within the ICL paradigm for NER tasks.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025
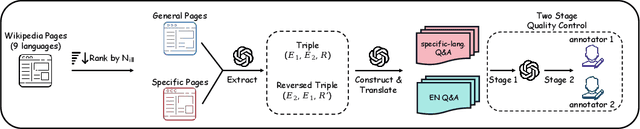


We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .