 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Token-Level Hallucination Detection in Large Language Models
May 12, 2026Large language models (LLMs) have demonstrated remarkable capabilities, but they still frequently produce hallucinations. These hallucinations are difficult to detect in reasoning-intensive tasks, where the content appears coherent but contains errors like logical flaws and unreliable intermediate results. While step-level analysis is commonly used to detect internal hallucinations, it suffers from limited granularity and poor scalability due to its reliance on step segmentation. To address these limitations, we propose TokenHD, a holistic pipeline for training token-level hallucination detectors. Specifically, TokenHD consists of a scalable data engine for synthesizing large-scale hallucination annotations along with a training recipe featuring an importance-weighted strategy for robust model training. To systematically assess the detection performance, we also provide a rigorous evaluation protocol. Through training within TokenHD, our detector operates directly on free-form text to identify hallucinations, eliminating the need for predefined step segmentation or additional text reformatting. Our experiments show that even a small detector (0.6B) achieves substantial performance gains after training, surpassing much larger reasoning models (e.g., QwQ-32B), and detection performance scales consistently with model size from 0.6B to 8B. Finally, we show that our detector can generalize well across diverse practical scenarios and explore strategies to further enhance its cross-domain generalization capability.
RemoteZero: Geospatial Reasoning with Zero Human Annotations
May 06, 2026Geospatial reasoning requires models to resolve complex spatial semantics and user intent into precise target locations for Earth observation. Recent progress has liberated the reasoning path from manual curation, allowing models to generate their own inference chains. Yet a final dependency remains: they are still supervised by human-annotated ground-truth coordinates. This leaves the reasoning process autonomous, but not its spatial endpoint, and prevents true self-evolution on abundant unlabeled remote sensing data. To break this bottleneck, we introduce RemoteZero, a box-supervision-free framework for geospatial reasoning. RemoteZero is motivated by a simple asymmetry: an MLLM is typically better at verifying whether a region satisfies a query than at directly generating precise coordinates. Leveraging this stronger discriminative ability, RemoteZero replaces geometric supervision with intrinsic semantic verification and enables GRPO training without box annotations. The resulting framework further supports iterative self-evolution, allowing the model to improve from unlabeled remote sensing imagery through its own verification signal. Experiments show that RemoteZero achieves competitive performance against strong supervised methods, demonstrating the potential of self-verifying training for geospatial reasoning localization.
RemoteAgent: Bridging Vague Human Intents and Earth Observation with RL-based Agentic MLLMs
Apr 09, 2026Earth Observation (EO) systems are essentially designed to support domain experts who often express their requirements through vague natural language rather than precise, machine-friendly instructions. Depending on the specific application scenario, these vague queries can demand vastly different levels of visual precision. Consequently, a practical EO AI system must bridge the gap between ambiguous human queries and the appropriate multi-granularity visual analysis tasks, ranging from holistic image interpretation to fine-grained pixel-wise predictions. While Multi-modal Large Language Models (MLLMs) demonstrate strong semantic understanding, their text-based output format is inherently ill-suited for dense, precision-critical spatial predictions. Existing agentic frameworks address this limitation by delegating tasks to external tools, but indiscriminate tool invocation is computationally inefficient and underutilizes the MLLM's native capabilities. To this end, we propose RemoteAgent, an agentic framework that strategically respects the intrinsic capability boundaries of MLLMs. To empower this framework to understand real user intents, we construct VagueEO, a human-centric instruction dataset pairing EO tasks with simulated vague natural-language queries. By leveraging VagueEO for reinforcement fine-tuning, we align an MLLM into a robust cognitive core that directly resolves image- and sparse region-level tasks. Consequently, RemoteAgent processes suitable tasks internally while intelligently orchestrating specialized tools via the Model Context Protocol exclusively for dense predictions. Extensive experiments demonstrate that RemoteAgent achieves robust intent recognition capabilities while delivering highly competitive performance across diverse EO tasks.
GeoBrowse: A Geolocation Benchmark for Agentic Tool Use with Expert-Annotated Reasoning Traces
Apr 05, 2026Deep research agents integrate fragmented evidence through multi-step tool use. BrowseComp offers a text-only testbed for such agents, but existing multimodal benchmarks rarely require both weak visual cues composition and BrowseComp-style multi-hop verification. Geolocation is a natural testbed because answers depend on combining multiple ambiguous visual cues and validating them with open-web evidence. Thus, we introduce GeoBrowse, a geolocation benchmark that combines visual reasoning with knowledge-intensive multi-hop queries. Level 1 tests extracting and composing fragmented visual cues, and Level 2 increases query difficulty by injecting long-tail knowledge and obfuscating key entities. To support evaluation, we provide an agentic workflow GATE with five think-with-image tools and four knowledge-intensive tools, and release expert-annotated stepwise traces grounded in verifiable evidence for trajectory-level analysis. Experiments show that GATE outperforms direct inference and open-source agents, indicating that no-tool, search-only or image-only setups are insufficient. Gains come from coherent, level-specific tool-use plans rather than more tool calls, as they more reliably reach annotated key evidence steps and make fewer errors when integrating into the final decision. The GeoBrowse bernchmark and codes are provided in https://github.com/ornamentt/GeoBrowse
Mitigating Safety Tax via Distribution-Grounded Refinement in Large Reasoning Models
Feb 02, 2026Safety alignment incurs safety tax that perturbs a large reasoning model's (LRM) general reasoning ability. Existing datasets used for safety alignment for an LRM are usually constructed by distilling safety reasoning traces and answers from an external LRM or human labeler. However, such reasoning traces and answers exhibit a distributional gap with the target LRM that needs alignment, and we conjecture such distributional gap is the culprit leading to significant degradation of reasoning ability of the target LRM. Driven by this hypothesis, we propose a safety alignment dataset construction method, dubbed DGR. DGR transforms and refines an existing out-of-distributional safety reasoning dataset to be aligned with the target's LLM inner distribution. Experimental results demonstrate that i) DGR effectively mitigates the safety tax while maintaining safety performance across all baselines, i.e., achieving \textbf{+30.2\%} on DirectRefusal and \textbf{+21.2\%} on R1-ACT improvement in average reasoning accuracy compared to Vanilla SFT; ii) the degree of reasoning degradation correlates with the extent of distribution shift, suggesting that bridging this gap is central to preserving capabilities. Furthermore, we find that safety alignment in LRMs may primarily function as a mechanism to activate latent knowledge, as a mere \textbf{10} samples are sufficient for activating effective refusal behaviors. These findings not only emphasize the importance of distributional consistency but also provide insights into the activation mechanism of safety in reasoning models.
Empowering Reliable Visual-Centric Instruction Following in MLLMs
Jan 06, 2026Evaluating the instruction-following (IF) capabilities of Multimodal Large Language Models (MLLMs) is essential for rigorously assessing how faithfully model outputs adhere to user-specified intentions. Nevertheless, existing benchmarks for evaluating MLLMs' instruction-following capability primarily focus on verbal instructions in the textual modality. These limitations hinder a thorough analysis of instruction-following capabilities, as they overlook the implicit constraints embedded in the semantically rich visual modality. To address this gap, we introduce VC-IFEval, a new benchmark accompanied by a systematically constructed dataset that evaluates MLLMs' instruction-following ability under multimodal settings. Our benchmark systematically incorporates vision-dependent constraints into instruction design, enabling a more rigorous and fine-grained assessment of how well MLLMs align their outputs with both visual input and textual instructions. Furthermore, by fine-tuning MLLMs on our dataset, we achieve substantial gains in visual instruction-following accuracy and adherence. Through extensive evaluation across representative MLLMs, we provide new insights into the strengths and limitations of current models.
EcomBench: Towards Holistic Evaluation of Foundation Agents in E-commerce
Dec 11, 2025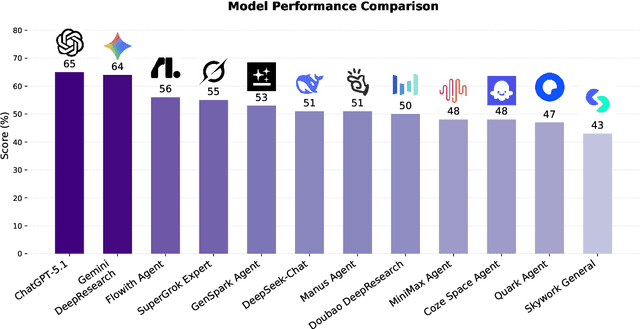
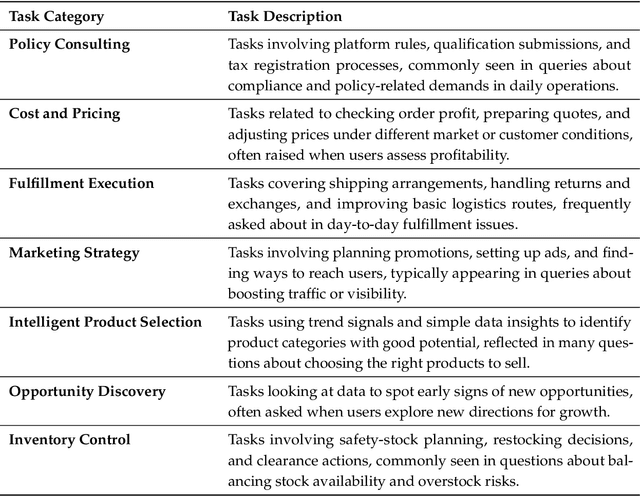

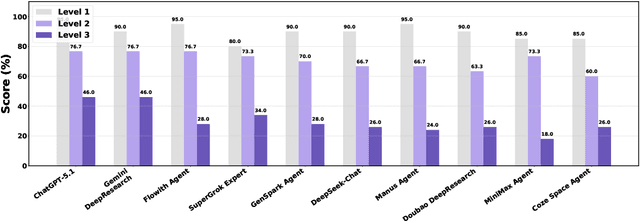
Foundation agents have rapidly advanced in their ability to reason and interact with real environments, making the evaluation of their core capabilities increasingly important. While many benchmarks have been developed to assess agent performance, most concentrate on academic settings or artificially designed scenarios while overlooking the challenges that arise in real applications. To address this issue, we focus on a highly practical real-world setting, the e-commerce domain, which involves a large volume of diverse user interactions, dynamic market conditions, and tasks directly tied to real decision-making processes. To this end, we introduce EcomBench, a holistic E-commerce Benchmark designed to evaluate agent performance in realistic e-commerce environments. EcomBench is built from genuine user demands embedded in leading global e-commerce ecosystems and is carefully curated and annotated through human experts to ensure clarity, accuracy, and domain relevance. It covers multiple task categories within e-commerce scenarios and defines three difficulty levels that evaluate agents on key capabilities such as deep information retrieval, multi-step reasoning, and cross-source knowledge integration. By grounding evaluation in real e-commerce contexts, EcomBench provides a rigorous and dynamic testbed for measuring the practical capabilities of agents in modern e-commerce.
Reasoning Path Divergence: A New Metric and Curation Strategy to Unlock LLM Diverse Thinking
Oct 30, 2025While Test-Time Scaling (TTS) has proven effective in improving the reasoning ability of large language models (LLMs), low diversity in model outputs often becomes a bottleneck; this is partly caused by the common "one problem, one solution" (1P1S) training practice, which provides a single canonical answer and can push models toward a narrow set of reasoning paths. To address this, we propose a "one problem, multiple solutions" (1PNS) training paradigm that exposes the model to a variety of valid reasoning trajectories and thus increases inference diversity. A core challenge for 1PNS is reliably measuring semantic differences between multi-step chains of thought, so we introduce Reasoning Path Divergence (RPD), a step-level metric that aligns and scores Long Chain-of-Thought solutions to capture differences in intermediate reasoning. Using RPD, we curate maximally diverse solution sets per problem and fine-tune Qwen3-4B-Base. Experiments show that RPD-selected training yields more varied outputs and higher pass@k, with an average +2.80% gain in pass@16 over a strong 1P1S baseline and a +4.99% gain on AIME24, demonstrating that 1PNS further amplifies the effectiveness of TTS. Our code is available at https://github.com/fengjujf/Reasoning-Path-Divergence .
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Sep 16, 2025



Recent advances in deep-research systems have demonstrated the potential for AI agents to autonomously discover and synthesize knowledge from external sources. In this paper, we introduce WebResearcher, a novel framework for building such agents through two key components: (1) WebResearcher, an iterative deep-research paradigm that reformulates deep research as a Markov Decision Process, where agents periodically consolidate findings into evolving reports while maintaining focused workspaces, overcoming the context suffocation and noise contamination that plague existing mono-contextual approaches; and (2) WebFrontier, a scalable data synthesis engine that generates high-quality training data through tool-augmented complexity escalation, enabling systematic creation of research tasks that bridge the gap between passive knowledge recall and active knowledge construction. Notably, we find that the training data from our paradigm significantly enhances tool-use capabilities even for traditional mono-contextual methods. Furthermore, our paradigm naturally scales through parallel thinking, enabling concurrent multi-agent exploration for more comprehensive conclusions. Extensive experiments across 6 challenging benchmarks demonstrate that WebResearcher achieves state-of-the-art performance, even surpassing frontier proprietary systems.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025
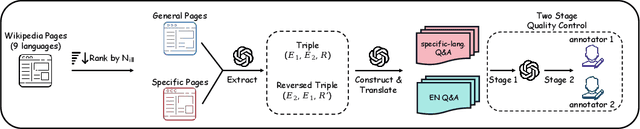


We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .