 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidedVLA: Specifying Task-Relevant Factors via Plug-and-Play Action Attention Specialization
May 12, 2026Vision-Language-Action (VLA) models aim for general robot learning by aligning action as a modality within powerful Vision-Language Models (VLMs). Existing VLAs rely on end-to-end supervision to implicitly enable the action decoding process to learn task-relevant features. However, without explicit guidance, these models often overfit to spurious correlations, such as visual shortcuts or environmental noise, limiting their generalization. In this paper, we introduce GuidedVLA, a framework designed to manually guide the action generation to focus on task-relevant factors. Our core insight is to treat the action decoder not as a monolithic learner, but as an assembly of functional components. Individual attention heads are supervised by manually defined auxiliary signals to capture distinct factors. As an initial study, we instantiate this paradigm with three specialized heads: object grounding, spatial geometry, and temporal skill logic. Across simulation and real-robot experiments, GuidedVLA improves success rates in both in-domain and out-of-domain settings compared to strong VLA baselines. Finally, we show that the quality of these specialized factors correlates positively with task performance and that our mechanism yields decoupled, high-quality features. Our results suggest that explicitly guiding action-decoder learning is a promising direction for building more robust and general VLA models.
A Synonymous Variational Perspective on the Rate-Distortion-Perception Tradeoff
Apr 16, 2026The fundamental limit of natural signal compression has traditionally been characterized by classical rate-distortion (RD) theory through the tradeoff between coding rate and reconstruction distortion, while the rate-distortion-perception (RDP) framework introduces a divergence-based measure of perceptual quality as a modeling principle rather than a theoretically-derived principle, leaving its theoretical origin unclear. In this paper, motivated by a synonymity-based semantic information perspective, we reformulate perceptual reconstruction as recovering any admissible sample within an ideal synonymous set (synset) associated with the source, rather than the source sample itself, and correspondingly establish a synonymous source coding architecture. On this basis, we develop a synonymous variational inference (SVI) analysis framework with a synonymous variational lower bound (SVLBO) for tractable analysis of synset-oriented compression. Within this framework, we establish a synonymity-perception consistency principle, showing that optimal identification of semantic information is theoretically consistent with perceptual optimization. Based on its derivation result, we prove a synonymous RDP tradeoff for the proposed synonymous source coding. These analytical results show that the distributional divergence term arises naturally from the synset-based reconstruction objective, clarify its compatibility with existing RDP formulations and classical RD theory, and suggest the potential advantages of synonymous source coding.
Synonymous Variational Inference for Perceptual Image Compression
May 28, 2025Recent contributions of semantic information theory reveal the set-element relationship between semantic and syntactic information, represented as synonymous relationships. In this paper, we propose a synonymous variational inference (SVI) method based on this synonymity viewpoint to re-analyze the perceptual image compression problem. It takes perceptual similarity as a typical synonymous criterion to build an ideal synonymous set (Synset), and approximate the posterior of its latent synonymous representation with a parametric density by minimizing a partial semantic KL divergence. This analysis theoretically proves that the optimization direction of perception image compression follows a triple tradeoff that can cover the existing rate-distortion-perception schemes. Additionally, we introduce synonymous image compression (SIC), a new image compression scheme that corresponds to the analytical process of SVI, and implement a progressive SIC codec to fully leverage the model's capabilities. Experimental results demonstrate comparable rate-distortion-perception performance using a single progressive SIC codec, thus verifying the effectiveness of our proposed analysis method.
Visual Agentic Reinforcement Fine-Tuning
May 20, 2025A key trend in Large Reasoning Models (e.g., OpenAI's o3) is the native agentic ability to use external tools such as web browsers for searching and writing/executing code for image manipulation to think with images. In the open-source research community, while significant progress has been made in language-only agentic abilities such as function calling and tool integration, the development of multi-modal agentic capabilities that involve truly thinking with images, and their corresponding benchmarks, are still less explored. This work highlights the effectiveness of Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) for enabling flexible and adaptive reasoning abilities for Large Vision-Language Models (LVLMs). With Visual-ARFT, open-source LVLMs gain the ability to browse websites for real-time information updates and write code to manipulate and analyze input images through cropping, rotation, and other image processing techniques. We also present a Multi-modal Agentic Tool Bench (MAT) with two settings (MAT-Search and MAT-Coding) designed to evaluate LVLMs' agentic search and coding abilities. Our experimental results demonstrate that Visual-ARFT outperforms its baseline by +18.6% F1 / +13.0% EM on MAT-Coding and +10.3% F1 / +8.7% EM on MAT-Search, ultimately surpassing GPT-4o. Visual-ARFT also achieves +29.3 F1% / +25.9% EM gains on existing multi-hop QA benchmarks such as 2Wiki and HotpotQA, demonstrating strong generalization capabilities. Our findings suggest that Visual-ARFT offers a promising path toward building robust and generalizable multimodal agents.
DSM: Building A Diverse Semantic Map for 3D Visual Grounding
Apr 11, 2025



In recent years, with the growing research and application of multimodal large language models (VLMs) in robotics, there has been an increasing trend of utilizing VLMs for robotic scene understanding tasks. Existing approaches that use VLMs for 3D Visual Grounding tasks often focus on obtaining scene information through geometric and visual information, overlooking the extraction of diverse semantic information from the scene and the understanding of rich implicit semantic attributes, such as appearance, physics, and affordance. The 3D scene graph, which combines geometry and language, is an ideal representation method for environmental perception and is an effective carrier for language models in 3D Visual Grounding tasks. To address these issues, we propose a diverse semantic map construction method specifically designed for robotic agents performing 3D Visual Grounding tasks. This method leverages VLMs to capture the latent semantic attributes and relations of objects within the scene and creates a Diverse Semantic Map (DSM) through a geometry sliding-window map construction strategy. We enhance the understanding of grounding information based on DSM and introduce a novel approach named DSM-Grounding. Experimental results show that our method outperforms current approaches in tasks like semantic segmentation and 3D Visual Grounding, particularly excelling in overall metrics compared to the state-of-the-art. In addition, we have deployed this method on robots to validate its effectiveness in navigation and grasping tasks.
Multi-Block UAMP Detection for AFDM under Fractional Delay-Doppler Channel
Oct 15, 2024



Affine Frequency Division Multiplexing (AFDM) is considered as a promising solution for next-generation wireless systems due to its satisfactory performance in high-mobility scenarios. By adjusting AFDM parameters to match the multi-path delay and Doppler shift, AFDM can achieve two-dimensional time-frequency diversity gain. However, under fractional delay-Doppler channels, AFDM encounters energy dispersion in the affine domain, which poses significant challenges for signal detection. This paper first investigates the AFDM system model under fractional delay-Doppler channels. To address the energy dispersion in the affine domain, a unitary transformation based approximate message passing (UAMP) algorithm is proposed. The algorithm performs unitary transformations and message passing in the time domain to avoid the energy dispersion issue. Additionally, we implemented block-wise processing to reduce computational complexity. Finally, the empirical extrinsic information transfer (E-EXIT) chart is used to evaluate iterative detection performance. Simulation results show that UAMP significantly outperforms GAMP under fractional delay-Doppler conditions.
MMDU: A Multi-Turn Multi-Image Dialog Understanding Benchmark and Instruction-Tuning Dataset for LVLMs
Jun 17, 2024



Generating natural and meaningful responses to communicate with multi-modal human inputs is a fundamental capability of Large Vision-Language Models(LVLMs). While current open-source LVLMs demonstrate promising performance in simplified scenarios such as single-turn single-image input, they fall short in real-world conversation scenarios such as following instructions in a long context history with multi-turn and multi-images. Existing LVLM benchmarks primarily focus on single-choice questions or short-form responses, which do not adequately assess the capabilities of LVLMs in real-world human-AI interaction applications. Therefore, we introduce MMDU, a comprehensive benchmark, and MMDU-45k, a large-scale instruction tuning dataset, designed to evaluate and improve LVLMs' abilities in multi-turn and multi-image conversations. We employ the clustering algorithm to ffnd the relevant images and textual descriptions from the open-source Wikipedia and construct the question-answer pairs by human annotators with the assistance of the GPT-4o model. MMDU has a maximum of 18k image+text tokens, 20 images, and 27 turns, which is at least 5x longer than previous benchmarks and poses challenges to current LVLMs. Our in-depth analysis of 15 representative LVLMs using MMDU reveals that open-source LVLMs lag behind closed-source counterparts due to limited conversational instruction tuning data. We demonstrate that ffne-tuning open-source LVLMs on MMDU-45k signiffcantly address this gap, generating longer and more accurate conversations, and improving scores on MMDU and existing benchmarks (MMStar: +1.1%, MathVista: +1.5%, ChartQA:+1.2%). Our contributions pave the way for bridging the gap between current LVLM models and real-world application demands. This project is available at https://github.com/Liuziyu77/MMDU.
Semantics-Division Duplexing: A Novel Full-Duplex Paradigm
Dec 14, 2023



In-band full-duplex (IBFD) is a theoretically effective solution to increase the overall throughput for the future wireless communications system by enabling transmission and reception over the same time-frequency resources. However, reliable source reconstruction remains a great challenge in the practical IBFD systems due to the non-ideal elimination of the self-interference and the inherent limitations of the separate source and channel coding methods. On the other hand, artificial intelligence-enabled semantic communication can provide a viable direction for the optimization of the IBFD system. This article introduces a novel IBFD paradigm with the guidance of semantic communication called semantics-division duplexing (SDD). It utilizes semantic domain processing to further suppress self-interference, distinguish the expected semantic information, and recover the desired sources. Further integration of the digital and semantic domain processing can be implemented so as to achieve intelligent and concise communications. We present the advantages of the SDD paradigm with theoretical explanations and provide some visualized results to verify its effectiveness.
Wireless Deep Video Semantic Transmission
May 26, 2022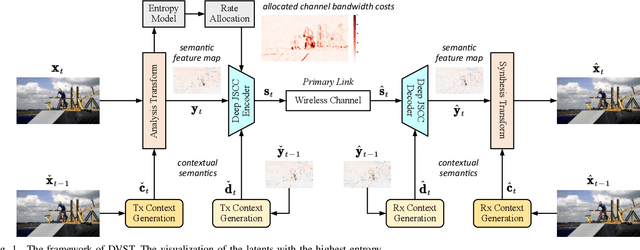
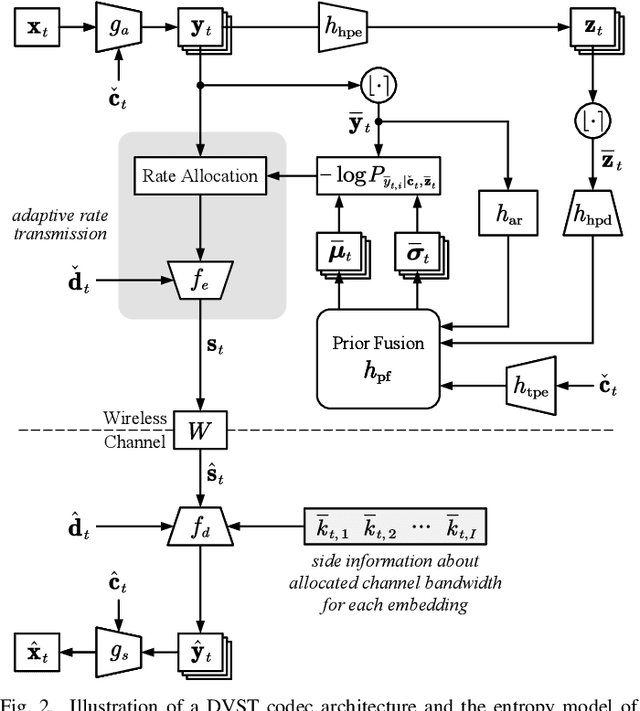
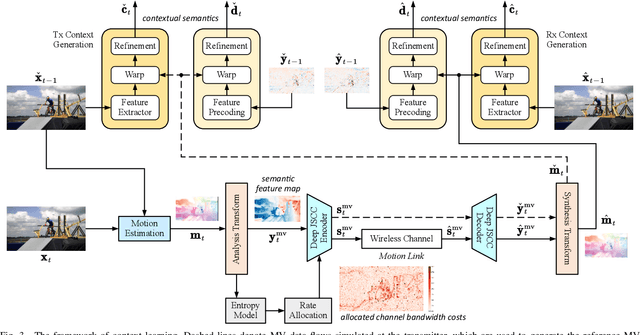
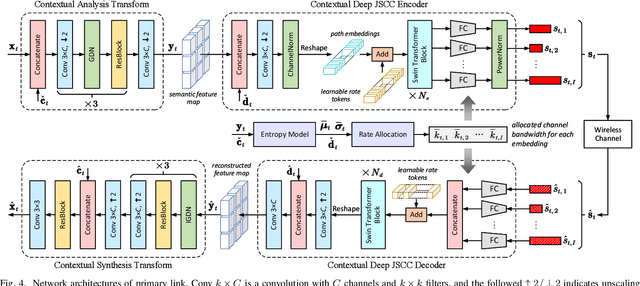
In this paper, we design a new class of high-efficiency deep joint source-channel coding methods to achieve end-to-end video transmission over wireless channels. The proposed methods exploit nonlinear transform and conditional coding architecture to adaptively extract semantic features across video frames, and transmit semantic feature domain representations over wireless channels via deep joint source-channel coding. Our framework is collected under the name deep video semantic transmission (DVST). In particular, benefiting from the strong temporal prior provided by the feature domain context, the learned nonlinear transform function becomes temporally adaptive, resulting in a richer and more accurate entropy model guiding the transmission of current frame. Accordingly, a novel rate adaptive transmission mechanism is developed to customize deep joint source-channel coding for video sources. It learns to allocate the limited channel bandwidth within and among video frames to maximize the overall transmission performance. The whole DVST design is formulated as an optimization problem whose goal is to minimize the end-to-end transmission rate-distortion performance under perceptual quality metrics or machine vision task performance metrics. Across standard video source test sequences and various communication scenarios, experiments show that our DVST can generally surpass traditional wireless video coded transmission schemes. The proposed DVST framework can well support future semantic communications due to its video content-aware and machine vision task integration abilities.