 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Identifier Visual Prompt and Verifiable Reinforcement Learning for Chemical Reaction Diagram Parsing
Mar 17, 2026Reaction diagram parsing (RxnDP) is critical for extracting chemical synthesis information from literature. Although recent Vision-Language Models (VLMs) have emerged as a promising paradigm to automate this complex visual reasoning task, their application is fundamentally bottlenecked by the inability to align visual chemical entities with pre-trained knowledge, alongside the inherent discrepancy between token-level training and reaction-level evaluation. To address these dual challenges, this work enhances VLM-based RxnDP from two complementary perspectives: prompting representation and learning paradigms. First, we propose Identifier as Visual Prompting (IdtVP), which leverages naturally occurring molecule identifiers (e.g., bold numerals like 1a) to activate the chemical knowledge acquired during VLM pre-training. IdtVP enables powerful zero-shot and out-of-distribution capabilities, outperforming existing prompting strategies. Second, to further optimize performance within fine-tuning paradigms, we introduce Re3-DAPO, a reinforcement learning algorithm that leverages verifiable rewards to directly optimize reaction-level metrics, thereby achieving consistent gains over standard supervised fine-tuning. Additionally, we release the ScannedRxn benchmark, comprising scanned historical reaction diagrams with real-world artifacts, to rigorously assess model robustness and out-of-distribution ability. Our contributions advance the accuracy and generalization of VLM-based reaction diagram parsing. We will release data, models, and code on GitHub.
On Channel Estimation for Group-Connected Beyond Diagonal RIS Assisted Multi-User MIMO Communication
Feb 24, 2026Beyond diagonal reconfigurable intelligent surface (BD-RIS) architectures offer superior beamforming gain over conventional diagonal RISs. However, the channel estimation overhead is the main hurdle for reaping the above gain in practice. This letter addresses this issue for group-connected BDRIS aided uplink communication from multiple multi-antenna users to one multi-antenna base station (BS). We first reveal that within each BD-RIS group, the cascaded channel associated with one user antenna and one BD-RIS element is a scaled version of that associated with any other user antenna and BD-RIS element due to the common RIS-BS channel. This insight drastically reduces the dimensionality of the channel estimation problem. Building on this property, we propose an efficient two-phase channel estimation protocol. In the first phase, the reference cascaded channels for all groups are estimated in parallel based on common received signals while determining the scaling coefficients for a single reference antenna. In the second phase, the scaling coefficients for all remaining user antennas are estimated. Numerical results demonstrate that our proposed framework achieves substantially lower estimation error with fewer pilot signals compared to state-of-the-art benchmark schemes.
Covariance-based Imaging and Multi-View Fusion for Networked Sensing
Nov 18, 2025This paper considers multi-view imaging in a sixth-generation (6G) integrated sensing and communication network, which consists of a transmit base-station (BS), multiple receive BSs connected to a central processing unit (CPU), and multiple extended targets. Our goal is to devise an effective multi-view imaging technique that can jointly leverage the targets' echo signals at all the receive BSs to precisely construct the image of these targets. To achieve this goal, we propose a two-phase approach. In Phase I, each receive BS recovers an individual image based on the sample covariance matrix of its received signals. Specifically, we propose a novel covariance-based imaging framework to jointly estimate effective scattering intensity and grid positions, which reduces the number of estimated parameters leveraging channel statistical properties and allows grid adjustment to conform to target geometry. In Phase II, the CPU fuses the individual images of all the receivers to construct a high-quality image of all the targets. Specifically, we design edge-preserving natural neighbor interpolation (EP-NNI) to map individual heterogeneous images onto common and finer grids, and then propose a joint optimization framework to estimate fused scattering intensity and BS fields of view. Extensive numerical results show that the proposed scheme significantly enhances imaging performance, facilitating high-quality environment reconstruction for future 6G networks.
Integrated Massive Communication and Target Localization in 6G Cell-Free Networks
Oct 16, 2025This paper presents an initial investigation into the combination of integrated sensing and communication (ISAC) and massive communication, both of which are largely regarded as key scenarios in sixth-generation (6G) wireless networks. Specifically, we consider a cell-free network comprising a large number of users, multiple targets, and distributed base stations (BSs). In each time slot, a random subset of users becomes active, transmitting pilot signals that can be scattered by the targets before reaching the BSs. Unlike conventional massive random access schemes, where the primary objectives are device activity detection and channel estimation, our framework also enables target localization by leveraging the multipath propagation effects introduced by the targets. However, due to the intricate dependency between user channels and target locations, characterizing the posterior distribution required for minimum mean-square error (MMSE) estimation presents significant computational challenges. To handle this problem, we propose a hybrid message passing-based framework that incorporates multiple approximations to mitigate computational complexity. Numerical results demonstrate that the proposed approach achieves high-accuracy device activity detection, channel estimation, and target localization simultaneously, validating the feasibility of embedding localization functionality into massive communication systems for future 6G networks.
Evaluating Large Language Model with Knowledge Oriented Language Specific Simple Question Answering
May 22, 2025
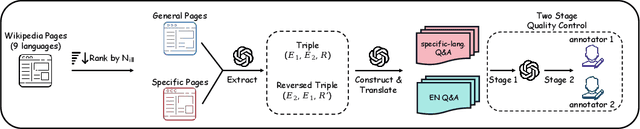


We introduce KoLasSimpleQA, the first benchmark evaluating the multilingual factual ability of Large Language Models (LLMs). Inspired by existing research, we created the question set with features such as single knowledge point coverage, absolute objectivity, unique answers, and temporal stability. These questions enable efficient evaluation using the LLM-as-judge paradigm, testing both the LLMs' factual memory and self-awareness ("know what they don't know"). KoLasSimpleQA expands existing research in two key dimensions: (1) Breadth (Multilingual Coverage): It includes 9 languages, supporting global applicability evaluation. (2) Depth (Dual Domain Design): It covers both the general domain (global facts) and the language-specific domain (such as history, culture, and regional traditions) for a comprehensive assessment of multilingual capabilities. We evaluated mainstream LLMs, including traditional LLM and emerging Large Reasoning Models. Results show significant performance differences between the two domains, particularly in performance metrics, ranking, calibration, and robustness. This highlights the need for targeted evaluation and optimization in multilingual contexts. We hope KoLasSimpleQA will help the research community better identify LLM capability boundaries in multilingual contexts and provide guidance for model optimization. We will release KoLasSimpleQA at https://github.com/opendatalab/KoLasSimpleQA .
OpenHuEval: Evaluating Large Language Model on Hungarian Specifics
Mar 27, 2025



We introduce OpenHuEval, the first benchmark for LLMs focusing on the Hungarian language and specifics. OpenHuEval is constructed from a vast collection of Hungarian-specific materials sourced from multiple origins. In the construction, we incorporated the latest design principles for evaluating LLMs, such as using real user queries from the internet, emphasizing the assessment of LLMs' generative capabilities, and employing LLM-as-judge to enhance the multidimensionality and accuracy of evaluations. Ultimately, OpenHuEval encompasses eight Hungarian-specific dimensions, featuring five tasks and 3953 questions. Consequently, OpenHuEval provides the comprehensive, in-depth, and scientifically accurate assessment of LLM performance in the context of the Hungarian language and its specifics. We evaluated current mainstream LLMs, including both traditional LLMs and recently developed Large Reasoning Models. The results demonstrate the significant necessity for evaluation and model optimization tailored to the Hungarian language and specifics. We also established the framework for analyzing the thinking processes of LRMs with OpenHuEval, revealing intrinsic patterns and mechanisms of these models in non-English languages, with Hungarian serving as a representative example. We will release OpenHuEval at https://github.com/opendatalab/OpenHuEval .
Advancing Comprehensive Aesthetic Insight with Multi-Scale Text-Guided Self-Supervised Learning
Dec 16, 2024



Image Aesthetic Assessment (IAA) is a vital and intricate task that entails analyzing and assessing an image's aesthetic values, and identifying its highlights and areas for improvement. Traditional methods of IAA often concentrate on a single aesthetic task and suffer from inadequate labeled datasets, thus impairing in-depth aesthetic comprehension. Despite efforts to overcome this challenge through the application of Multi-modal Large Language Models (MLLMs), such models remain underdeveloped for IAA purposes. To address this, we propose a comprehensive aesthetic MLLM capable of nuanced aesthetic insight. Central to our approach is an innovative multi-scale text-guided self-supervised learning technique. This technique features a multi-scale feature alignment module and capitalizes on a wealth of unlabeled data in a self-supervised manner to structurally and functionally enhance aesthetic ability. The empirical evidence indicates that accompanied with extensive instruct-tuning, our model sets new state-of-the-art benchmarks across multiple tasks, including aesthetic scoring, aesthetic commenting, and personalized image aesthetic assessment. Remarkably, it also demonstrates zero-shot learning capabilities in the emerging task of aesthetic suggesting. Furthermore, for personalized image aesthetic assessment, we harness the potential of in-context learning and showcase its inherent advantages.
Utilize the Flow before Stepping into the Same River Twice: Certainty Represented Knowledge Flow for Refusal-Aware Instruction Tuning
Oct 09, 2024



Refusal-Aware Instruction Tuning (RAIT) enables Large Language Models (LLMs) to refuse to answer unknown questions. By modifying responses of unknown questions in the training data to refusal responses such as "I don't know", RAIT enhances the reliability of LLMs and reduces their hallucination. Generally, RAIT modifies training samples based on the correctness of the initial LLM's response. However, this crude approach can cause LLMs to excessively refuse answering questions they could have correctly answered, the problem we call over-refusal. In this paper, we explore two primary causes of over-refusal: Static conflict emerges when the RAIT data is constructed solely on correctness criteria, causing similar samples in the LLM's feature space to be assigned different labels (original vs. modified "I don't know"). Dynamic conflict occurs due to the changes of LLM's knowledge state during fine-tuning, which transforms previous unknown questions into knowns, while the training data, which is constructed based on the initial LLM, remains unchanged. These conflicts cause the trained LLM to misclassify known questions as unknown, resulting in over-refusal. To address this issue, we introduce Certainty Represented Knowledge Flow for Refusal-Aware Instructions Construction (CRaFT). CRaFT centers on two main contributions: First, we additionally incorporate response certainty to selectively filter and modify data, reducing static conflicts. Second, we implement preliminary rehearsal training to characterize changes in the LLM's knowledge state, which helps mitigate dynamic conflicts during the fine-tuning process. We conducted extensive experiments on open-ended question answering and multiple-choice question task. Experiment results show that CRaFT can improve LLM's overall performance during the RAIT process. Source code and training data will be released at Github.
Asynchronous MIMO-OFDM Massive Unsourced Random Access with Codeword Collisions
May 20, 2024



This paper investigates asynchronous MIMO massive unsourced random access in an orthogonal frequency division multiplexing (OFDM) system over frequency-selective fading channels, with the presence of both timing and carrier frequency offsets (TO and CFO) and non-negligible codeword collisions. The proposed coding framework segregates the data into two components, namely, preamble and coding parts, with the former being tree-coded and the latter LDPC-coded. By leveraging the dual sparsity of the equivalent channel across both codeword and delay domains (CD and DD), we develop a message passing-based sparse Bayesian learning algorithm, combined with belief propagation and mean field, to iteratively estimate DD channel responses, TO, and delay profiles. Furthermore, we establish a novel graph-based algorithm to iteratively separate the superimposed channels and compensate for the phase rotations. Additionally, the proposed algorithm is applied to the flat fading scenario to estimate both TO and CFO, where the channel and offset estimation is enhanced by leveraging the geometric characteristics of the signal constellation. Simulations reveal that the proposed algorithm achieves superior performance and substantial complexity reduction in both channel and offset estimation compared to the codebook enlarging-based counterparts, and enhanced data recovery performances compared to state-of-the-art URA schemes.
VastTrack: Vast Category Visual Object Tracking
Mar 06, 2024In this paper, we introduce a novel benchmark, dubbed VastTrack, towards facilitating the development of more general visual tracking via encompassing abundant classes and videos. VastTrack possesses several attractive properties: (1) Vast Object Category. In particular, it covers target objects from 2,115 classes, largely surpassing object categories of existing popular benchmarks (e.g., GOT-10k with 563 classes and LaSOT with 70 categories). With such vast object classes, we expect to learn more general object tracking. (2) Larger scale. Compared with current benchmarks, VastTrack offers 50,610 sequences with 4.2 million frames, which makes it to date the largest benchmark regarding the number of videos, and thus could benefit training even more powerful visual trackers in the deep learning era. (3) Rich Annotation. Besides conventional bounding box annotations, VastTrack also provides linguistic descriptions for the videos. The rich annotations of VastTrack enables development of both the vision-only and the vision-language tracking. To ensure precise annotation, all videos are manually labeled with multiple rounds of careful inspection and refinement. To understand performance of existing trackers and to provide baselines for future comparison, we extensively assess 25 representative trackers. The results, not surprisingly, show significant drops compared to those on current datasets due to lack of abundant categories and videos from diverse scenarios for training, and more efforts are required to improve general tracking. Our VastTrack and all the evaluation results will be made publicly available https://github.com/HengLan/VastTrack.