 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Graph Discovery with Retrieval-Augmented Generation based Large Language Models
Feb 23, 2024



Causal graph recovery is essential in the field of causal inference. Traditional methods are typically knowledge-based or statistical estimation-based, which are limited by data collection biases and individuals' knowledge about factors affecting the relations between variables of interests. The advance of large language models (LLMs) provides opportunities to address these problems. We propose a novel method that utilizes the extensive knowledge contained within a large corpus of scientific literature to deduce causal relationships in general causal graph recovery tasks. This method leverages Retrieval Augmented-Generation (RAG) based LLMs to systematically analyze and extract pertinent information from a comprehensive collection of research papers. Our method first retrieves relevant text chunks from the aggregated literature. Then, the LLM is tasked with identifying and labelling potential associations between factors. Finally, we give a method to aggregate the associational relationships to build a causal graph. We demonstrate our method is able to construct high quality causal graphs on the well-known SACHS dataset solely from literature.
Review-Incorporated Model-Agnostic Profile Injection Attacks on Recommender Systems
Feb 14, 2024

Recent studies have shown that recommender systems (RSs) are highly vulnerable to data poisoning attacks. Understanding attack tactics helps improve the robustness of RSs. We intend to develop efficient attack methods that use limited resources to generate high-quality fake user profiles to achieve 1) transferability among black-box RSs 2) and imperceptibility among detectors. In order to achieve these goals, we introduce textual reviews of products to enhance the generation quality of the profiles. Specifically, we propose a novel attack framework named R-Trojan, which formulates the attack objectives as an optimization problem and adopts a tailored transformer-based generative adversarial network (GAN) to solve it so that high-quality attack profiles can be produced. Comprehensive experiments on real-world datasets demonstrate that R-Trojan greatly outperforms state-of-the-art attack methods on various victim RSs under black-box settings and show its good imperceptibility.
Confidence-aware Fine-tuning of Sequential Recommendation Systems via Conformal Prediction
Feb 14, 2024



In Sequential Recommendation Systems, Cross-Entropy (CE) loss is commonly used but fails to harness item confidence scores during training. Recognizing the critical role of confidence in aligning training objectives with evaluation metrics, we propose CPFT, a versatile framework that enhances recommendation confidence by integrating Conformal Prediction (CP)-based losses with CE loss during fine-tuning. CPFT dynamically generates a set of items with a high probability of containing the ground truth, enriching the training process by incorporating validation data without compromising its role in model selection. This innovative approach, coupled with CP-based losses, sharpens the focus on refining recommendation sets, thereby elevating the confidence in potential item predictions. By fine-tuning item confidence through CP-based losses, CPFT significantly enhances model performance, leading to more precise and trustworthy recommendations that increase user trust and satisfaction. Our extensive evaluation across five diverse datasets and four distinct sequential models confirms CPFT's substantial impact on improving recommendation quality through strategic confidence optimization. Access to the framework's code will be provided following the acceptance of the paper.
Prompt Perturbation in Retrieval-Augmented Generation based Large Language Models
Feb 11, 2024



The robustness of large language models (LLMs) becomes increasingly important as their use rapidly grows in a wide range of domains. Retrieval-Augmented Generation (RAG) is considered as a means to improve the trustworthiness of text generation from LLMs. However, how the outputs from RAG-based LLMs are affected by slightly different inputs is not well studied. In this work, we find that the insertion of even a short prefix to the prompt leads to the generation of outputs far away from factually correct answers. We systematically evaluate the effect of such prefixes on RAG by introducing a novel optimization technique called Gradient Guided Prompt Perturbation (GGPP). GGPP achieves a high success rate in steering outputs of RAG-based LLMs to targeted wrong answers. It can also cope with instructions in the prompts requesting to ignore irrelevant context. We also exploit LLMs' neuron activation difference between prompts with and without GGPP perturbations to give a method that improves the robustness of RAG-based LLMs through a highly effective detector trained on neuron activation triggered by GGPP generated prompts. Our evaluation on open-sourced LLMs demonstrates the effectiveness of our methods.
OIL-AD: An Anomaly Detection Framework for Sequential Decision Sequences
Feb 07, 2024Anomaly detection in decision-making sequences is a challenging problem due to the complexity of normality representation learning and the sequential nature of the task. Most existing methods based on Reinforcement Learning (RL) are difficult to implement in the real world due to unrealistic assumptions, such as having access to environment dynamics, reward signals, and online interactions with the environment. To address these limitations, we propose an unsupervised method named Offline Imitation Learning based Anomaly Detection (OIL-AD), which detects anomalies in decision-making sequences using two extracted behaviour features: action optimality and sequential association. Our offline learning model is an adaptation of behavioural cloning with a transformer policy network, where we modify the training process to learn a Q function and a state value function from normal trajectories. We propose that the Q function and the state value function can provide sufficient information about agents' behavioural data, from which we derive two features for anomaly detection. The intuition behind our method is that the action optimality feature derived from the Q function can differentiate the optimal action from others at each local state, and the sequential association feature derived from the state value function has the potential to maintain the temporal correlations between decisions (state-action pairs). Our experiments show that OIL-AD can achieve outstanding online anomaly detection performance with up to 34.8% improvement in F1 score over comparable baselines.
Zero-shot sketch-based remote sensing image retrieval based on multi-level and attention-guided tokenization
Feb 03, 2024



Effectively and efficiently retrieving images from remote sensing databases is a critical challenge in the realm of remote sensing big data. Utilizing hand-drawn sketches as retrieval inputs offers intuitive and user-friendly advantages, yet the potential of multi-level feature integration from sketches remains underexplored, leading to suboptimal retrieval performance. To address this gap, our study introduces a novel zero-shot, sketch-based retrieval method for remote sensing images, leveraging multi-level, attention-guided tokenization. This approach starts by employing multi-level self-attention feature extraction to tokenize the query sketches, as well as self-attention feature extraction to tokenize the candidate images. It then employs cross-attention mechanisms to establish token correspondence between these two modalities, facilitating the computation of sketch-to-image similarity. Our method demonstrates superior retrieval accuracy over existing sketch-based remote sensing image retrieval techniques, as evidenced by tests on four datasets. Notably, it also exhibits robust zero-shot learning capabilities and strong generalizability in handling unseen categories and novel remote sensing data. The method's scalability can be further enhanced by the pre-calculation of retrieval tokens for all candidate images in a database. This research underscores the significant potential of multi-level, attention-guided tokenization in cross-modal remote sensing image retrieval. For broader accessibility and research facilitation, we have made the code and dataset used in this study publicly available online. Code and dataset are available at https://github.com/Snowstormfly/Cross-modal-retrieval-MLAGT.
KnowledgeNavigator: Leveraging Large Language Models for Enhanced Reasoning over Knowledge Graph
Dec 26, 2023Large language model (LLM) has achieved outstanding performance on various downstream tasks with its powerful natural language understanding and zero-shot capability, but LLM still suffers from knowledge limitation. Especially in scenarios that require long logical chains or complex reasoning, the hallucination and knowledge limitation of LLM limit its performance in question answering (QA). In this paper, we propose a novel framework KnowledgeNavigator to address these challenges by efficiently and accurately retrieving external knowledge from knowledge graph and using it as a key factor to enhance LLM reasoning. Specifically, KnowledgeNavigator first mines and enhances the potential constraints of the given question to guide the reasoning. Then it retrieves and filters external knowledge that supports answering through iterative reasoning on knowledge graph with the guidance of LLM and the question. Finally, KnowledgeNavigator constructs the structured knowledge into effective prompts that are friendly to LLM to help its reasoning. We evaluate KnowledgeNavigator on multiple public KGQA benchmarks, the experiments show the framework has great effectiveness and generalization, outperforming previous knowledge graph enhanced LLM methods and is comparable to the fully supervised models.
Fine-tuning vision foundation model for crack segmentation in civil infrastructures
Dec 15, 2023



Large-scale foundation models have become the mainstream deep learning method, while in civil engineering, the scale of AI models is strictly limited. In this work, a vision foundation model is introduced for crack segmentation. Two parameter-efficient fine-tuning methods, adapter and low-rank adaptation, are adopted to fine-tune the foundation model in semantic segmentation: the Segment Anything Model (SAM). The fine-tuned CrackSAM model is much larger than all the existing crack segmentation models but shows excellent performance. To test the zero-shot performance of the proposed method, two unique datasets related to road and exterior wall cracks are collected, annotated and open-sourced, for a total of 810 images. Comparative experiments are conducted with twelve mature semantic segmentation models. On datasets with artificial noise and previously unseen datasets, the performance of CrackSAM far exceeds that of all state-of-the-art models. CrackSAM exhibits remarkable superiority, particularly under challenging conditions such as dim lighting, shadows, road markings, construction joints, and other interference factors. These cross-scenario results demonstrate the outstanding zero-shot capability of foundation models and provide new ideas for developing vision models in civil engineering.
Toward General-Purpose Robots via Foundation Models: A Survey and Meta-Analysis
Dec 15, 2023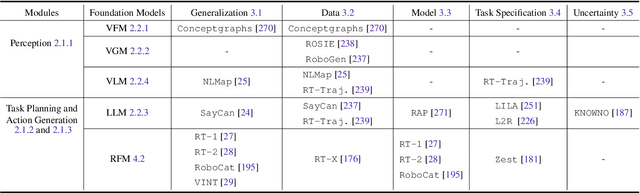
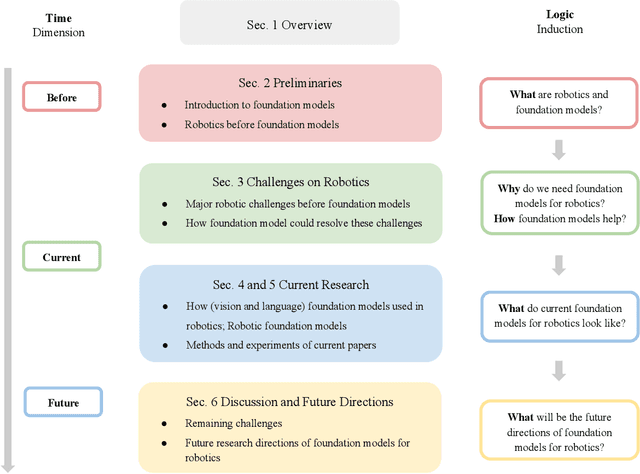
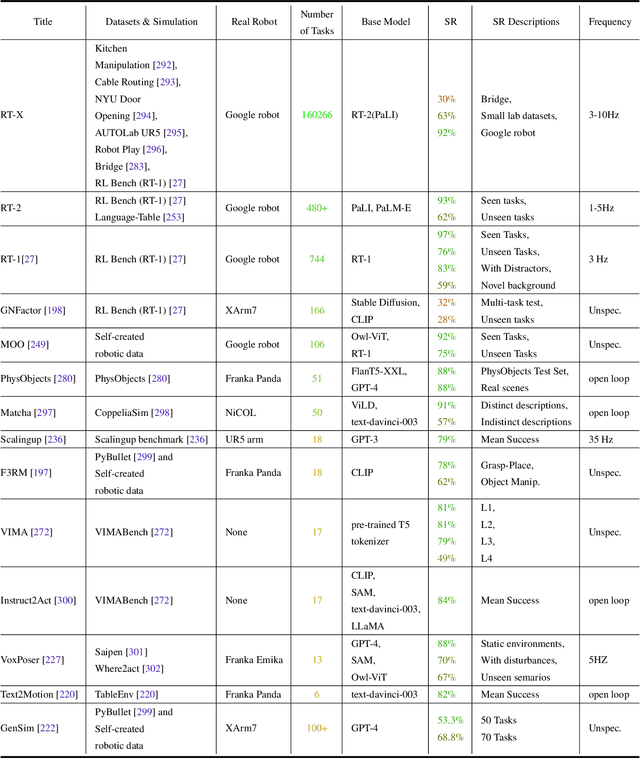
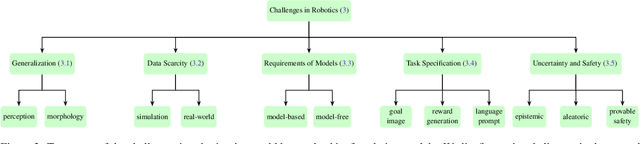
Building general-purpose robots that can operate seamlessly, in any environment, with any object, and utilizing various skills to complete diverse tasks has been a long-standing goal in Artificial Intelligence. Unfortunately, however, most existing robotic systems have been constrained - having been designed for specific tasks, trained on specific datasets, and deployed within specific environments. These systems usually require extensively-labeled data, rely on task-specific models, have numerous generalization issues when deployed in real-world scenarios, and struggle to remain robust to distribution shifts. Motivated by the impressive open-set performance and content generation capabilities of web-scale, large-capacity pre-trained models (i.e., foundation models) in research fields such as Natural Language Processing (NLP) and Computer Vision (CV), we devote this survey to exploring (i) how these existing foundation models from NLP and CV can be applied to the field of robotics, and also exploring (ii) what a robotics-specific foundation model would look like. We begin by providing an overview of what constitutes a conventional robotic system and the fundamental barriers to making it universally applicable. Next, we establish a taxonomy to discuss current work exploring ways to leverage existing foundation models for robotics and develop ones catered to robotics. Finally, we discuss key challenges and promising future directions in using foundation models for enabling general-purpose robotic systems. We encourage readers to view our living GitHub repository of resources, including papers reviewed in this survey as well as related projects and repositories for developing foundation models for robotics.
iMatching: Imperative Correspondence Learning
Dec 04, 2023Learning feature correspondence is a foundational task in computer vision, holding immense importance for downstream applications such as visual odometry and 3D reconstruction. Despite recent progress in data-driven models, feature correspondence learning is still limited by the lack of accurate per-pixel correspondence labels. To overcome this difficulty, we introduce a new self-supervised scheme, imperative learning (IL), for training feature correspondence. It enables correspondence learning on arbitrary uninterrupted videos without any camera pose or depth labels, heralding a new era for self-supervised correspondence learning. Specifically, we formulated the problem of correspondence learning as a bilevel optimization, which takes the reprojection error from bundle adjustment as a supervisory signal for the model. To avoid large memory and computation overhead, we leverage the stationary point to effectively back-propagate the implicit gradients through bundle adjustment. Through extensive experiments, we demonstrate superior performance on tasks including feature matching and pose estimation, in which we obtained an average of 30% accuracy gain over the state-of-the-art matching models.