 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Post-Quantization: Native Hash Learning with a Dedicated HASH Token
Jul 03, 2026Efficient large-scale image retrieval requires compact representations that preserve semantic similarity under fast Hamming-space search. Deep hashing is appealing, but most existing CNN- and ViT-based methods still follow a post-quantization paradigm, where continuous visual features are first learned and binary codes are then produced by a terminal hash projection or binarization operation. This late code generation creates a feature-to-code discrepancy between the continuously optimized representation space and the discrete Hamming space used for retrieval. To address this limitation, we propose HashViT, a Vision Transformer framework for native hash token learning. Instead of treating hashing as a terminal readout, HashViT introduces a dedicated HASH token that serves as a persistent, hash-oriented retrieval state inside the transformer. The HASH token is structurally decomposed into a Hash Register for direct binary code generation and a Semantic Workspace for preserving auxiliary continuous semantics. To enable effective workspace-to-register interaction, we further design a lightweight Hash Refinement Adapter that progressively refines the Hash Register across transformer layers. As a result, binary-oriented representations are formed through token evolution within the backbone, rather than being abruptly induced by an output-level projection. HashViT is optimized with a unified objective that combines learnable semantic center supervision, class-token similarity distillation, and quantization regularization, encouraging the HASH token to encode semantically structured and compact binary representations. Extensive experiments on three widely used benchmarks demonstrate that HashViT achieves state-of-the-art or highly competitive retrieval performance while preserving the efficiency of compact Hamming codes. Code is available at https://github.com/Xinze919/HashViT.
EagleNet: Energy-Aware Fine-Grained Relationship Learning Network for Text-Video Retrieval
Mar 26, 2026Text-video retrieval tasks have seen significant improvements due to the recent development of large-scale vision-language pre-trained models. Traditional methods primarily focus on video representations or cross-modal alignment, while recent works shift toward enriching text expressiveness to better match the rich semantics in videos. However, these methods use only interactions between text and frames/video, and ignore rich interactions among the internal frames within a video, so the final expanded text cannot capture frame contextual information, leading to disparities between text and video. In response, we introduce Energy-Aware Fine-Grained Relationship Learning Network (EagleNet) to generate accurate and context-aware enriched text embeddings. Specifically, the proposed Fine-Grained Relationship Learning mechanism (FRL) first constructs a text-frame graph by the generated text candidates and frames, then learns relationships among texts and frames, which are finally used to aggregate text candidates into an enriched text embedding that incorporates frame contextual information. To further improve fine-grained relationship learning in FRL, we design Energy-Aware Matching (EAM) to model the energy of text-frame interactions and thus accurately capture the distribution of real text-video pairs. Moreover, for more effective cross-modal alignment and stable training, we replace the conventional softmax-based contrastive loss with the sigmoid loss. Extensive experiments have demonstrated the superiority of EagleNet across MSRVTT, DiDeMo, MSVD, and VATEX. Codes are available at https://github.com/draym28/EagleNet.
Critique Before Thinking: Mitigating Hallucination through Rationale-Augmented Instruction Tuning
May 12, 2025Despite significant advancements in multimodal reasoning tasks, existing Large Vision-Language Models (LVLMs) are prone to producing visually ungrounded responses when interpreting associated images. In contrast, when humans embark on learning new knowledge, they often rely on a set of fundamental pre-study principles: reviewing outlines to grasp core concepts, summarizing key points to guide their focus and enhance understanding. However, such preparatory actions are notably absent in the current instruction tuning processes. This paper presents Re-Critic, an easily scalable rationale-augmented framework designed to incorporate fundamental rules and chain-of-thought (CoT) as a bridge to enhance reasoning abilities. Specifically, Re-Critic develops a visual rationale synthesizer that scalably augments raw instructions with rationale explanation. To probe more contextually grounded responses, Re-Critic employs an in-context self-critic mechanism to select response pairs for preference tuning. Experiments demonstrate that models fine-tuned with our rationale-augmented dataset yield gains that extend beyond hallucination-specific tasks to broader multimodal reasoning tasks.
RealEra: Semantic-level Concept Erasure via Neighbor-Concept Mining
Oct 11, 2024



The remarkable development of text-to-image generation models has raised notable security concerns, such as the infringement of portrait rights and the generation of inappropriate content. Concept erasure has been proposed to remove the model's knowledge about protected and inappropriate concepts. Although many methods have tried to balance the efficacy (erasing target concepts) and specificity (retaining irrelevant concepts), they can still generate abundant erasure concepts under the steering of semantically related inputs. In this work, we propose RealEra to address this "concept residue" issue. Specifically, we first introduce the mechanism of neighbor-concept mining, digging out the associated concepts by adding random perturbation into the embedding of erasure concept, thus expanding the erasing range and eliminating the generations even through associated concept inputs. Furthermore, to mitigate the negative impact on the generation of irrelevant concepts caused by the expansion of erasure scope, RealEra preserves the specificity through the beyond-concept regularization. This makes irrelevant concepts maintain their corresponding spatial position, thereby preserving their normal generation performance. We also employ the closed-form solution to optimize weights of U-Net for the cross-attention alignment, as well as the prediction noise alignment with the LoRA module. Extensive experiments on multiple benchmarks demonstrate that RealEra outperforms previous concept erasing methods in terms of superior erasing efficacy, specificity, and generality. More details are available on our project page https://realerasing.github.io/RealEra/ .
Prediction Exposes Your Face: Black-box Model Inversion via Prediction Alignment
Jul 11, 2024



Model inversion (MI) attack reconstructs the private training data of a target model given its output, posing a significant threat to deep learning models and data privacy. On one hand, most of existing MI methods focus on searching for latent codes to represent the target identity, yet this iterative optimization-based scheme consumes a huge number of queries to the target model, making it unrealistic especially in black-box scenario. On the other hand, some training-based methods launch an attack through a single forward inference, whereas failing to directly learn high-level mappings from prediction vectors to images. Addressing these limitations, we propose a novel Prediction-to-Image (P2I) method for black-box MI attack. Specifically, we introduce the Prediction Alignment Encoder to map the target model's output prediction into the latent code of StyleGAN. In this way, prediction vector space can be well aligned with the more disentangled latent space, thus establishing a connection between prediction vectors and the semantic facial features. During the attack phase, we further design the Aligned Ensemble Attack scheme to integrate complementary facial attributes of target identity for better reconstruction. Experimental results show that our method outperforms other SOTAs, e.g.,compared with RLB-MI, our method improves attack accuracy by 8.5% and reduces query numbers by 99% on dataset CelebA.
Disrupting Diffusion: Token-Level Attention Erasure Attack against Diffusion-based Customization
May 31, 2024



With the development of diffusion-based customization methods like DreamBooth, individuals now have access to train the models that can generate their personalized images. Despite the convenience, malicious users have misused these techniques to create fake images, thereby triggering a privacy security crisis. In light of this, proactive adversarial attacks are proposed to protect users against customization. The adversarial examples are trained to distort the customization model's outputs and thus block the misuse. In this paper, we propose DisDiff (Disrupting Diffusion), a novel adversarial attack method to disrupt the diffusion model outputs. We first delve into the intrinsic image-text relationships, well-known as cross-attention, and empirically find that the subject-identifier token plays an important role in guiding image generation. Thus, we propose the Cross-Attention Erasure module to explicitly "erase" the indicated attention maps and disrupt the text guidance. Besides,we analyze the influence of the sampling process of the diffusion model on Projected Gradient Descent (PGD) attack and introduce a novel Merit Sampling Scheduler to adaptively modulate the perturbation updating amplitude in a step-aware manner. Our DisDiff outperforms the state-of-the-art methods by 12.75% of FDFR scores and 7.25% of ISM scores across two facial benchmarks and two commonly used prompts on average.
Digging into Depth Priors for Outdoor Neural Radiance Fields
Aug 08, 2023Neural Radiance Fields (NeRF) have demonstrated impressive performance in vision and graphics tasks, such as novel view synthesis and immersive reality. However, the shape-radiance ambiguity of radiance fields remains a challenge, especially in the sparse viewpoints setting. Recent work resorts to integrating depth priors into outdoor NeRF training to alleviate the issue. However, the criteria for selecting depth priors and the relative merits of different priors have not been thoroughly investigated. Moreover, the relative merits of selecting different approaches to use the depth priors is also an unexplored problem. In this paper, we provide a comprehensive study and evaluation of employing depth priors to outdoor neural radiance fields, covering common depth sensing technologies and most application ways. Specifically, we conduct extensive experiments with two representative NeRF methods equipped with four commonly-used depth priors and different depth usages on two widely used outdoor datasets. Our experimental results reveal several interesting findings that can potentially benefit practitioners and researchers in training their NeRF models with depth priors. Project Page: https://cwchenwang.github.io/outdoor-nerf-depth
Joint Plasticity Learning for Camera Incremental Person Re-Identification
Oct 18, 2022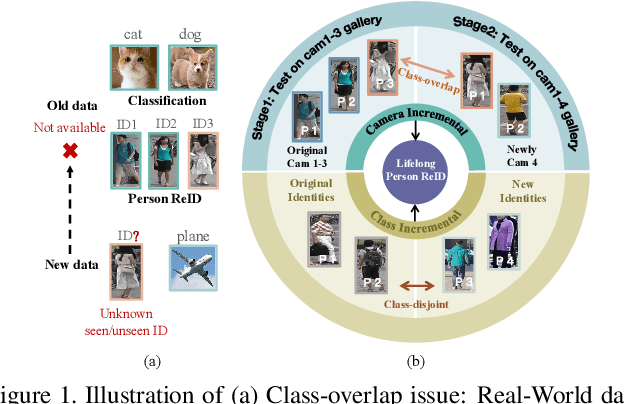

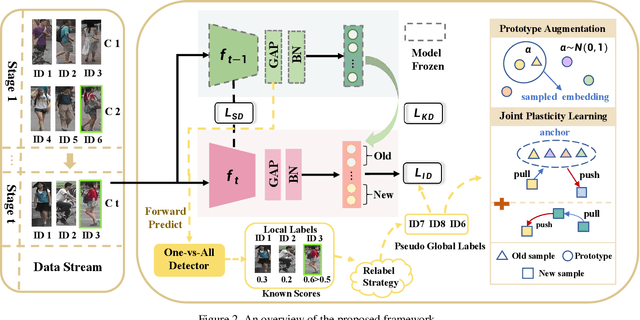
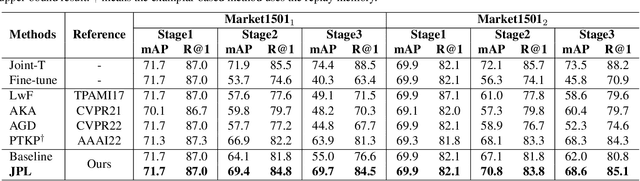
Recently, incremental learning for person re-identification receives increasing attention, which is considered a more practical setting in real-world applications. However, the existing works make the strong assumption that the cameras are fixed and the new-emerging data is class-disjoint from previous classes. In this paper, we focus on a new and more practical task, namely Camera Incremental person ReID (CIP-ReID). CIP-ReID requires ReID models to continuously learn informative representations without forgetting the previously learned ones only through the data from newly installed cameras. This is challenging as the new data only have local supervision in new cameras with no access to the old data due to privacy issues, and they may also contain persons seen by previous cameras. To address this problem, we propose a non-exemplar-based framework, named JPL-ReID. JPL-ReID first adopts a one-vs-all detector to discover persons who have been presented in previous cameras. To maintain learned representations, JPL-ReID utilizes a similarity distillation strategy with no previous training data available. Simultaneously, JPL-ReID is capable of learning new knowledge to improve the generalization ability using a Joint Plasticity Learning objective. The comprehensive experimental results on two datasets demonstrate that our proposed method significantly outperforms the comparative methods and can achieve state-of-the-art results with remarkable advantages.
Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification
Dec 15, 2021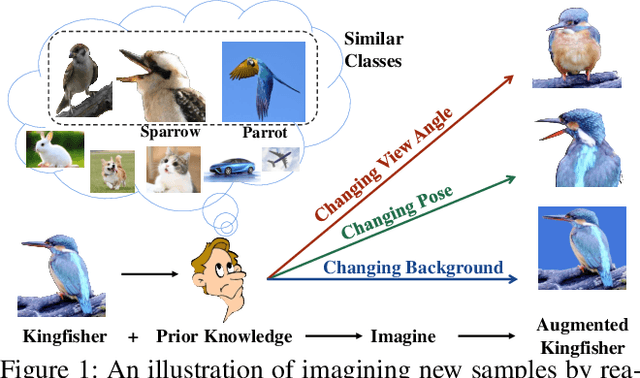
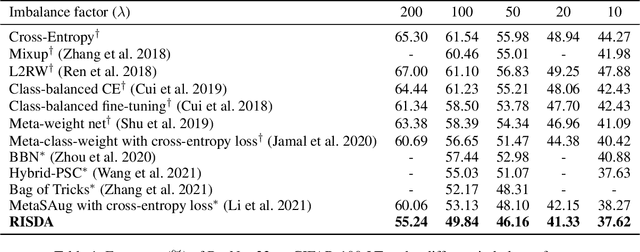
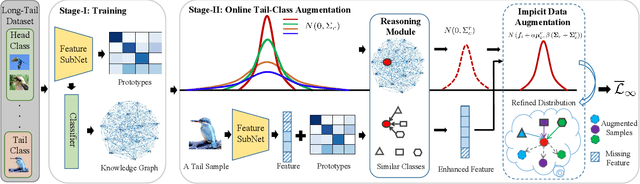
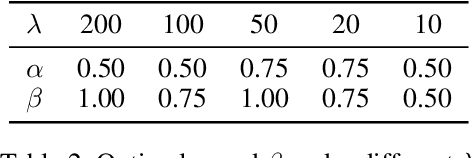
Real-world data often follows a long-tailed distribution, which makes the performance of existing classification algorithms degrade heavily. A key issue is that samples in tail categories fail to depict their intra-class diversity. Humans can imagine a sample in new poses, scenes, and view angles with their prior knowledge even if it is the first time to see this category. Inspired by this, we propose a novel reasoning-based implicit semantic data augmentation method to borrow transformation directions from other classes. Since the covariance matrix of each category represents the feature transformation directions, we can sample new directions from similar categories to generate definitely different instances. Specifically, the long-tailed distributed data is first adopted to train a backbone and a classifier. Then, a covariance matrix for each category is estimated, and a knowledge graph is constructed to store the relations of any two categories. Finally, tail samples are adaptively enhanced via propagating information from all the similar categories in the knowledge graph. Experimental results on CIFAR-100-LT, ImageNet-LT, and iNaturalist 2018 have demonstrated the effectiveness of our proposed method compared with the state-of-the-art methods.
Mask is All You Need: Rethinking Mask R-CNN for Dense and Arbitrary-Shaped Scene Text Detection
Sep 08, 2021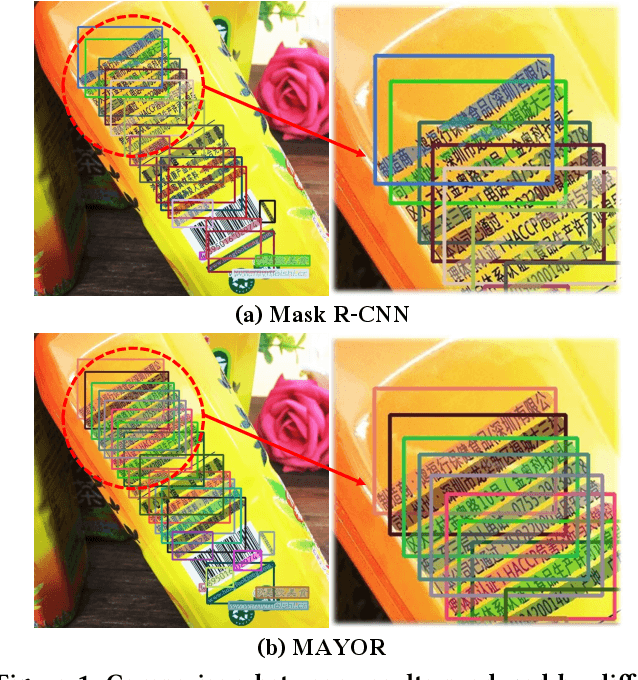
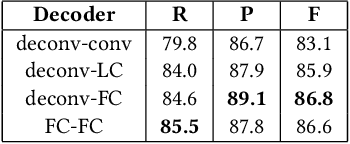
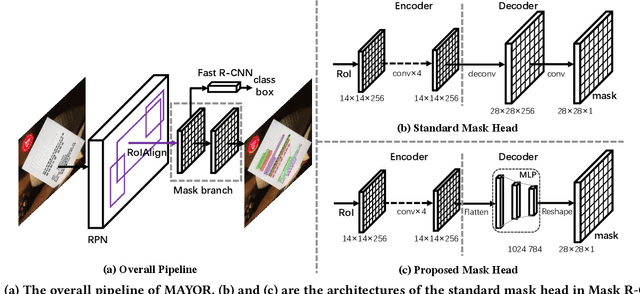
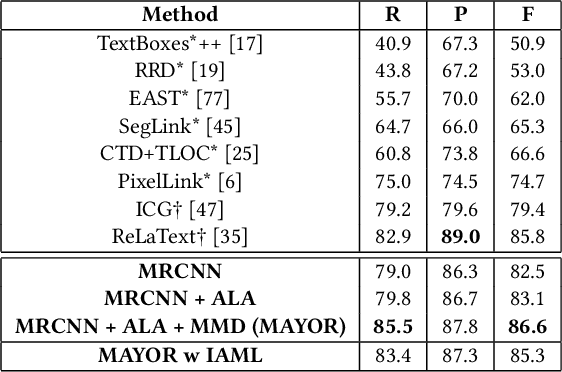
Due to the large success in object detection and instance segmentation, Mask R-CNN attracts great attention and is widely adopted as a strong baseline for arbitrary-shaped scene text detection and spotting. However, two issues remain to be settled. The first is dense text case, which is easy to be neglected but quite practical. There may exist multiple instances in one proposal, which makes it difficult for the mask head to distinguish different instances and degrades the performance. In this work, we argue that the performance degradation results from the learning confusion issue in the mask head. We propose to use an MLP decoder instead of the "deconv-conv" decoder in the mask head, which alleviates the issue and promotes robustness significantly. And we propose instance-aware mask learning in which the mask head learns to predict the shape of the whole instance rather than classify each pixel to text or non-text. With instance-aware mask learning, the mask branch can learn separated and compact masks. The second is that due to large variations in scale and aspect ratio, RPN needs complicated anchor settings, making it hard to maintain and transfer across different datasets. To settle this issue, we propose an adaptive label assignment in which all instances especially those with extreme aspect ratios are guaranteed to be associated with enough anchors. Equipped with these components, the proposed method named MAYOR achieves state-of-the-art performance on five benchmarks including DAST1500, MSRA-TD500, ICDAR2015, CTW1500, and Total-Text.